
Muy buenas, me llamo Luis y para hoy les traigo este nuevo post.
- ILSVRC’10
- ILSVRC’11
- ILSVRC’12 (AlexNet)
- ILSVRC’13 (ZFNet)
- ILSVRC’14 (VGGNet)
- ILSVRC’14 (GoogleNet)
- ILSVRC’15 (ResNet)
- ILSVRC son las siglas de Imagenet Large Scale, Visual Recognition Challenge o Imagenet Challenge.
- ILSVRC es un desafío que se realiza anualmente para permitir a los contendientes clasificar las imágenes correctamente y generar las mejores predicciones posibles.
Índice
AlexNet

La arquitectura de AlexNet CNN ganó el desafío de ImageNet ILSVRC 2012 por un amplio margen: logró una tasa de error del 17%, mientras que el segundo mejor logró sólo un 26%.
Fue desarrollado por Alex Krizhevsky , Ilya Sutskever y Geoffrey Hinton.
Es bastante similar a LeNet-5, sólo que mucho más grande y profundo, y fue el primero en apilar capas convolucionales directamente encima de cada una de ellas, en lugar de apilar una capa de reserva encima de cada capa convolucional.
Consiste en 8 capas convolucionales completamente conectadas y 3 capas de agrupación máximas.

Para reducir el exceso de equipamiento, los autores utilizaron dos técnicas de regularización: primero aplicaron la deserción con una tasa de abandono del 50% durante el entrenamiento a los resultados de las capas F8 y F9.
En segundo lugar, realizaron un aumento de los datos desplazando aleatoriamente las imágenes de entrenamiento mediante varias compensaciones, dándoles la vuelta horizontalmente y cambiando las condiciones de iluminación.
ZFNet

-
ZFNetes otra arquitectura de 8 capas de CNN. -
ZFNetes muy similar aAlexNet, con la excepción de algunas de las capas. - La arquitectura
ZFNet CNNganó el desafío deImageNet ILSVRCen 2013. - Una diferencia importante en los enfoques fue que
ZF Netusó filtros de tamaño 7×7 mientras queAlexNetusó filtros de11x11. - La intuición detrás de esto es que al usar filtros más grandes estábamos perdiendo mucha información de píxeles, que podemos retener al tener tamaños de filtro más pequeños en las capas de convolución anteriores.
- El número de filtros aumenta a medida que profundizamos. Esta red también utilizó
ReLUspara su activación y se entrenó utilizando el descenso de gradientes estocásticos por lotes.
VGGNet
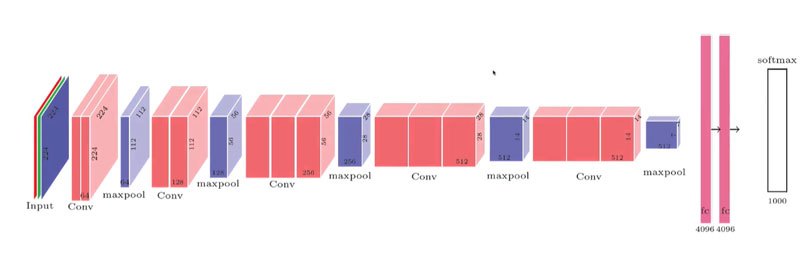
El segundo puesto en el desafío de la ILSVRC 2014 fue para VGGNet.
Fue desarrollado por K. Simon-yan y A. Zisserman.
Durante el diseño de la VGGNet, se encontró que no se necesitaban capas de convolución alternas y de agrupación. Así que la VGGnet usa múltiples capas de convolución en secuencia con capas de agrupamiento entre ellas.
Tenía una arquitectura muy simple y clásica, con 2 o 3 capas convolucionales, una capa de reserva, luego otra vez 2 o 3 capas convolucionales, una capa de reserva, y así sucesivamente (con un total de sólo 16 capas convolucionales) , además de una red densa final con 2 capas ocultas y la capa de salida. Utilizó sólo 3 × 3 filtros, pero muchos filtros.
GoogLeNet

- La arquitectura
GoogLeNetfue desarrollada por Christian Szegedy et al. de Google Research, 12 y ganó el desafíoILSVRC 2014al llevar la tasa de error de los 5 principales por debajo del 7%. - Esta gran actuación se debió en gran parte al hecho de que la red era mucho más profunda que las CNN anteriores.
- Esto fue posible gracias a las subredes llamadas módulos de inicio, que permiten a
GoogLeNetutilizar los parámetros de manera mucho más eficiente que las arquitecturas anteriores:GoogLeNeten realidad tiene 10 veces menos parámetros queAlexNet(aproximadamente 6 millones en lugar de 60 millones) .

GoogLeNet usa el módulo de inicio 9 y elimina todas las capas completamente conectadas usando la agrupación promedio para pasar de 7x7x1024 a 1x1x1024. Esto ahorra muchos parámetros.
Posteriormente, los investigadores de Google propusieron varias variantes de la arquitectura GoogLeNet, incluidos Inception-v3 e Inception-v4, utilizando módulos de inicio ligeramente diferentes y alcanzando un rendimiento aún mejor.
ResNet

- El desafío de la
ILSVRC 2015se ganó usando una Red Residual (o ResNet) . - Fue desarrollado por Kaiming He et al .
- Proporcionó una asombrosa tasa de error de los 5 primeros por debajo del 3,6%, usando un CNN extremadamente profundo compuesto de 152 capas. Confirmó la tendencia general: los modelos son cada vez más profundos, con cada vez menos parámetros. La clave para poder entrenar una red tan profunda es utilizar conexiones de salto (también llamadas conexiones de atajo) : la señal que alimenta una capa también se añade a la salida de una capa situada un poco más arriba en la pila. Veamos por qué esto es útil.

Cuando se entrena una red neuronal, el objetivo es hacer que modele una función objetivo h(x). Si se añade la entrada x a la salida de la red (es decir, se añade una conexión de salto) , entonces la red se verá obligada a modelar f(x) = h(x)-x en lugar de h(x). Esto se denomina aprendizaje residual .
- https://www.guvi.in/ (Plataforma de aprendizaje en línea).
- Handson Machine Learning with Scikit (Libro de referencia, PDF – https://drive.google.com/file/d/16DdwF4KIGi47ky7Q_B-4aApvMYW2evJZ/view?usp=sharing ).
Espero que te sea de utilidad. Gracias por leer.





Añadir comentario