
Hola, me llamo Luis y esta vez les traigo este nuevo post.
Índice
La manipulación de cuerdas es más fácil con Pandas
Tenemos que representar cada bit de datos en valores numéricos para ser procesados y analizados por modelos de aprendizaje automático y aprendizaje profundo. Sin embargo, las cadenas no suelen tener un formato agradable y limpio y requieren un procesamiento previo para convertirlas en valores numéricos. Pandas ofrece muchas funciones versátiles para modificar y procesar datos de cadenas de manera eficiente.
En esta publicación, descubriremos cómo los Pandas pueden manipular cadenas. Agrupé funciones y métodos de cadena en 5 categorías:
- Terrible
- Pelar
- Reemplazo
- Filtración
- Combinatorio
Primero creemos un marco de datos de muestra para trabajar con ejemplos.
import numpy as np import pandas as pdsample = 'col_a':['Houston,TX', 'Dallas,TX', 'Chicago,IL', 'Phoenix,AZ', 'San Diego,CA'], 'col_b':['$64K-$72K', '$62K-$70K', '$69K-$76K', '$62K-$72K', '$71K-$78K' ], 'col_c':['A','B','A','a','c'], 'col_d':[' 1x', ' 1y', '2x ', '1x', '1y '] df_sample = pd.DataFrame(sample) df_sample
1. División
A veces, las cadenas contienen más de una pieza de información y es posible que debamos usarlas por separado. Por ejemplo, «col_a» contiene tanto la ciudad como el estado. los división La función de los pandas es una función muy flexible para dividir cuerdas.
df_sample['col_a'].str.split(',')0 [Houston, TX]
1 [Dallas, TX]
2 [Chicago, IL]
3 [Phoenix, AZ]
4 [San Diego, CA]
Name: col_a, dtype: object
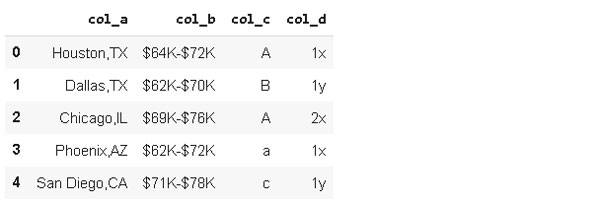
Ahora, cada elemento se convierte en una lista basada en el carácter utilizado para dividir. Podemos exportar fácilmente elementos individuales de esas listas. Creemos una columna de «estado».
df_sample['state'] = df_sample['col_a'].str.split(',').str[1]df_sample
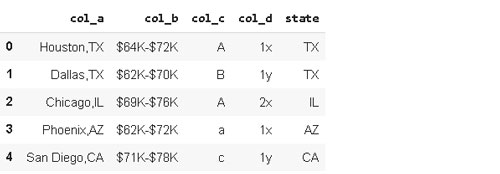
Advertencia: Subíndice ([1]) debe aplicarse con la palabra clave str. De lo contrario, obtendremos la lista en la fila especificada.
df_sample['col_a'].str.split(',')[1]
['Dallas', 'TX']
La división se puede realizar en cualquier carácter o letra.
La función de división devuelve un marco de datos si el parámetro de expansión se establece como Verdadero.
df_sample['col_a'].str.split('a', expand=True)

split vs rsplit
De forma predeterminada, la división se realiza desde la izquierda. Para dividir a la derecha, use rsplit.
Considere la siguiente serie:

Apliquemos la función de división y limitemos el número de divisiones con norte parámetro:
categories.str.split('-', expand=True, n=2)

Solo se realizan 2 divisiones a la izquierda. Si hacemos la misma operación con rsplit:
categories.str.rsplit('-', expand=True, n=2)

Se realiza la misma operación pero a la derecha.
2. Desnudando
Desnudar es como recortar las ramas de los árboles. Podemos eliminar espacios o cualquier otro carácter al principio o al final de una cadena.
Por ejemplo, las cadenas en «col_b» tienen el carácter $ al principio que puede ser eliminado con lstrip:
df_sample['col_b'].str.lstrip('$')0 64K-$72K 1 62K-$70K 2 69K-$76K 3 62K-$72K 4 71K-$78K Name: col_b, dtype: object
De forma similar, la rstrip se utiliza para recortar personajes del final.
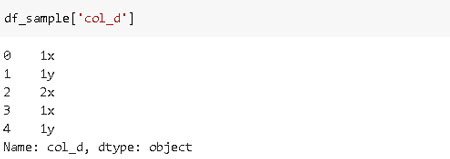
Las cadenas pueden tener espacios al principio o al final. Considere «col_d» en nuestro marco de datos.

Esos espacios de entrada y salida pueden ser eliminados con una tira:
df_sample['col_d'] = df_sample['col_d'].str.strip()
3. Reemplazando
La función de reemplazo de pandas se utiliza para reemplazar los valores en filas o columnas. Del mismo modo, la operación replace as a string se utiliza para reemplazar los caracteres de una cadena.
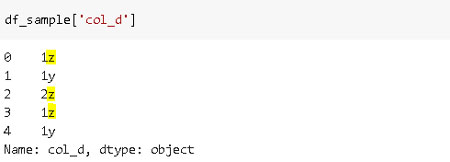
Reemplazamos las letras «x» en «col_d» por «z».
df_sample['col_d'] = df_sample['col_d'].str.replace('x', 'z')
4. Filtro
Podemos filtrar las cadenas basadas en el primer y último personaje. Las funciones a utilizar son startwith() y endswith().
Aquí está nuestro marco de datos original:
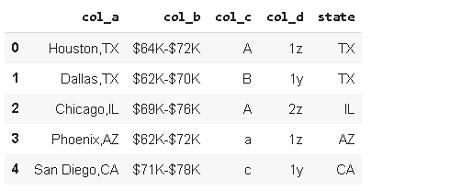
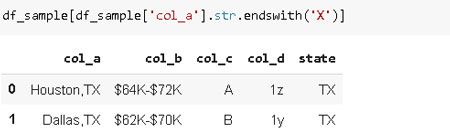
Aquí hay una versión filtrada que sólo incluye filas en las que «col_a» termina con la letra «x».
df_sample[df_sample['col_a'].str.endswith('X')]
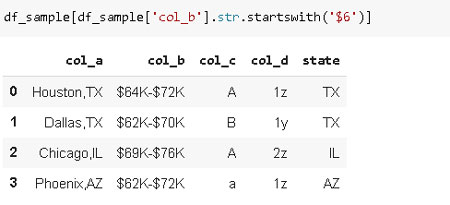
O, filas en las que «col_b» comienza con «$6»:
df_sample[df_sample['col_b'].str.startswith('$6')]
También podemos filtrar las cadenas extrayendo ciertos caracteres. Para instace, podemos obtener los 2 primeros caracteres de las cadenas en una columna o serie por str[:2].
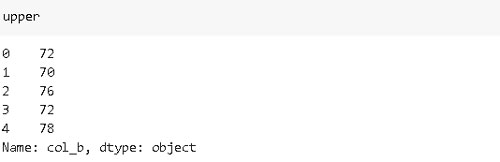
«col_b» representa un rango de valores, pero los valores numéricos están ocultos en una cadena. Vamos a extraerlos con subíndices de cadenas:
lower = df_sample['col_b'].str[1:3]
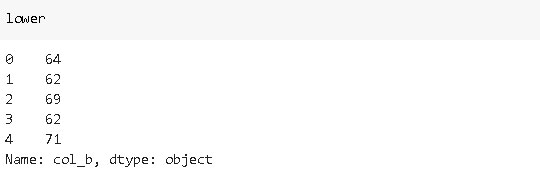
upper = df_sample['col_b'].str[-3:-1]
5. Combinando
La función de gato puede usarse para concatenar cuerdas.
Necesitamos pasar un argumento para poner entre las cadenas concatenadas usando el parámetro sep. Por defecto, cat ignora los valores perdidos pero también podemos especificar cómo manejarlos usando el parámetro na_rep.
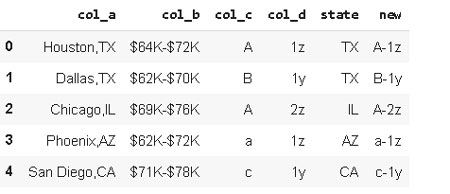
Vamos a crear una nueva columna concatenando «col_c» y «col_d» con el separador «-«.
df_sample['new']=df_sample['col_c'].str.cat(df_sample['col_d'], sep='-')df_sample
Bonus: Objeto vs Cadena
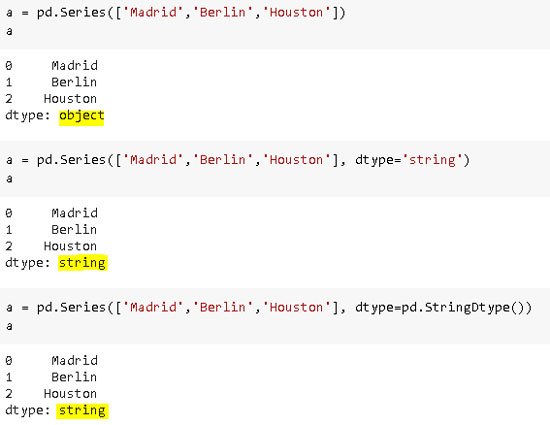
Antes de pandas 1.0, sólo se utilizaba el tipo de datos «objeto» para almacenar cadenas, lo que causaba algunos inconvenientes porque los datos que no eran cadenas también se podían almacenar utilizando el tipo de datos «objeto». Pandas 1.0 introduce un nuevo tipo de datos específico para los datos de cadenas que es el StringDtype. A partir de ahora, podemos seguir usando el objeto o StringDtype para almacenar cadenas, pero en el futuro, puede que sólo tengamos que usar StringDtype.
Una cosa importante a tener en cuenta aquí es que el tipo de datos de objeto sigue siendo el tipo de datos por defecto para las cadenas. Para usar StringDtype, necesitamos declararlo explícitamente.
Podemos pasar el argumento «string» o pd.StringDtype() al parámetro dtype a string datatype.
Gracias por leer. Por favor, avíseme si tiene algún comentario.





Añadir comentario