Hola, me llamo Luis y en esta ocasión les traigo este tutorial.
Índice
Una explicación paso a paso del bloque de auto-atención de múltiples cabezas
En este artículo, voy a explicar todo lo que necesita saber sobre la atención personal.
¿Qué contienen las redes neuronales transformadoras que las hace mucho más poderosas y de mejor rendimiento que las redes neuronales recurrentes regulares?
Respuesta: Utilizan el bloque de atención personal de múltiples cabezas para dar a las entradas de inserción de palabras más información contextual. Pero, ¿qué hace exactamente el bloque de auto-atención con las incrustaciones de palabras que hacen que estos modelos de transformadores sean mucho más poderosos?
Ese es el tema central de este artículo. El propósito principal de esta publicación es describir tanto la intuición detrás de cada parte del bloque de auto-atención como las operaciones matemáticas involucradas en él.
Este artículo no tiene como objetivo explicar la estructura general de las redes neuronales de transformadores. Tampoco describe la diferencia entre la atención propia y la atención regular.
¿Qué es la atención a uno mismo y por qué la necesitamos?
Sabemos que las incrustaciones de palabras son vectores que representan el significado semántico de una palabra. Las palabras con significados similares pueden tener incrustaciones similares. Sin embargo, en una oración, los significados individuales de las palabras no representan sus significados en la oración. Por ejemplo, si tuviera la frase, Bank of a river, las incrustaciones de Bank y river individualmente significan cosas completamente diferentes, pero tienen una fuerte correlación en la oración. Las incrustaciones de palabras sin atención propia no poseen este sentido de información contextual, por lo que dada la frase anterior, un modelo de lenguaje tendría pocas posibilidades de predecir el río. Para abordar este problema, en el artículo se propuso el bloque de autoatención. Atención es todo lo que necesitas como parte de la arquitectura original del transformador.
Un módulo de auto atención funciona comparando cada palabra de la oración con todas las demás palabras de la oración, incluyéndose a sí misma, y volviendo a sopesar las incrustaciones de palabras de cada palabra para incluir la relevancia contextual. Toma n incrustaciones de palabras sin contexto y devuelve n incrustaciones de palabras con información contextual. Por ejemplo, en la frase Bank of the river, Bank se compararía con Bank, of, the, and river, y cuando se compara Bank con esas cuatro palabras, la inserción de palabras se volvería a ponderar para incluir la relevancia de las palabras para su propio significado en la oración en consecuencia.
Pero, ¿cómo funciona exactamente?
El bloque Auto-atención consta de tres pasos / partes:
- Similitud de productos de puntos para encontrar puntuaciones de alineación
- Normalización de las puntuaciones para obtener los pesos.
- Repesado de las incrustaciones originales utilizando los pesos
1. Similitud del producto escalar
Cuando las incrustaciones de palabras de entrada se pasan al módulo de auto-atención y descubren a quién deben prestar atención, necesitan una función para encontrar qué tan similares son a las otras palabras de la oración. Aquí es donde entra en juego la similitud del producto escalar.
Para la siguiente explicación, usaré el siguiente ejemplo:
Words: v1 v2 v3 v4
donde v1, v2, v3 y v4 son las incrustaciones de palabras de palabras en una oración.
En nuestro ejemplo, prestaremos atención a v3 y lo compararemos con v1, v2, v3 y v4. La razón por la que también tenemos que comparar cada palabra consigo misma (por ejemplo, v3 a v3) es para que el modelo pueda aprender a qué partes del significado semántico de una palabra debe prestar atención. Puede parecer inusual que una palabra deba prestarse atención a sí misma. Sin embargo, a veces una palabra puede tener más de un significado representado en su incrustación (como el ejemplo con Bank), y a menos que también nos incluyamos en la similitud del producto escalar, el modelo no podrá aprender qué partes del significado de la palabra debe prestar atención a. En pocas palabras, las palabras suelen tener más de un significado, y para que el modelo reconozca a qué significado de la palabra debe prestar atención, debemos comparar las palabras entre sí incluyéndolas en la similitud del producto escalar. En nuestro ejemplo, donde v3 se compara con cualquier otra palabra y con ella misma, se ve así:
(v1*v3) = S31 (v2*v3) = S32 (v3*v3) = S33 (v4*v3) = S34
Tomaremos el producto escalar de v1 y v3, v2 y v3, v3 y v3 y v4 y v3 para determinar la puntuación de alineación de cada par de incrustaciones. Las puntuaciones de alineación, S31, S32, S33 y S34, nos dirán qué tan similares son los significados semánticos de v3 y cada una de las cuatro palabras comparadas. Cuanto mayor sea la puntuación de alineación, más similares serán los significados semánticos de las palabras y más atención tendrá que prestar atención a la otra palabra del par. Tenga en cuenta que cada una de las puntuaciones de alineación es un solo número, no un vector o matriz de números.
Solo he realizado este proceso para una palabra: v3. En realidad, este proceso se realizará simultáneamente para las cuatro palabras utilizando vectorización y álgebra lineal.
¿Por qué funciona la similitud del producto escalar?
Tome la palabra incrustación de Rey y Reina.
King = [0.99, 0.01, 0.02] Queen = [0.97, 0.03, 0.02]
La puntuación de alineación de este par sería:
(0.99 * 0.97) + (0.01 * 0.03) + (0.02 * 0.02) = 0.961
Ahora tome la palabra incrustaciones de King and Dog
King = [0.99, 0.01, 0.02] Dog = [0.01, 0.02, 0.02]
La puntuación de alineación de este par sería
(0.99 * 0.01) + (0.01 * 0.02) + (0.02 * 0.02) = 0.0105
Tenga en cuenta que estas incrustaciones de palabras están compuestas y que las incrustaciones de palabras reales de Dog, King y reina probablemente tengan un tamaño mucho mayor. También tenga en cuenta que el primer índice, donde el King y la Queen tenían un número alto, representa la realeza de la palabra en particular.
Como puede ver, la puntuación de alineación del King y la Queen es mucho mayor que la del King y el Dog. Esto se debe a que el significado semántico del king y el dog son diferentes, por lo que no son importantes entre sí en una oración. El índice 1 representa la realeza de la palabra, por lo que el King y la Queen son similares en ese sentido.
En resumen, si el significado semántico de ambas palabras difiere, entonces la puntuación de alineación no será alta, las palabras tendrán una correspondencia baja y cada palabra prestará poca atención entre sí, por lo que las incrustaciones de palabras originales de cada palabra ganarán, no cambie demasiado. Si el significado semántico de dos palabras es similar en cualquier aspecto, entonces la puntuación de alineación será alta, las palabras tendrán una alta correspondencia y las dos palabras prestarán mucha atención entre sí, por lo que la palabra original incrustaciones de cada una La palabra sufrirá un cambio significativo.
2. Normalización de las puntuaciones de alineación
Normalizar los valores de las salidas de cualquier red neuronal a través de una función de activación es un procedimiento común. Normalizaremos las puntuaciones de alineación utilizando una función de activación de SoftMax para obtener los pesos que aplicaremos a las incrustaciones de palabras originales. La función SoftMax hará que cada uno de los puntajes de alineación sea una distribución probabilística para que todos sumen uno. En nuestro ejemplo,
S31 -> SoftMax -> W31 S32 -> SoftMax -> W32 S33 -> SoftMax -> W33 S34 -> SoftMax -> W34
Los cuatro puntajes de alineación serán SoftMaxed para obtener los pesos finales que deben aplicarse a las incrustaciones de palabras originales para crear la incrustación contextualizada final.
Tenga en cuenta que cuando digo «pesos» en el párrafo anterior, no me refiero a los parámetros que aprenderá el modelo.
3. Proceso de pesaje final
Ahora tiene lugar el proceso de pesaje final. Para determinar la cantidad total de atención que la palabra (v3) debe prestar a las otras palabras, multiplicamos los pesos con sus respectivas incrustaciones de palabras originales y luego sumamos todos estos valores para obtener la incrustación de la palabra final para la palabra que se compara (v3); en este caso,
W31 * v1 = Y31 W32 * v2 = Y32 W33 * v3 = Y33 W34 * v4 = Y34Y31 + Y32 + Y33 + Y34 = Y3
Y3 es el último vector de incrustación de palabras ponderadas de v3. Recuerde que Y31, Y32, Y33 e Y34 son todos vectores individualmente, por lo que debemos sumarlos para obtener un vector final.
Recuerde que el proceso descrito anteriormente también se realizará para todas las demás palabras de la oración.
Intuitivamente, todos los procesos anteriores tienen sentido excepto por una cosa: el hecho de que debido a que no hay pesos que aprender, los puntajes de alineación y los pesos de auto atención estarán esencialmente predeterminados y el modelo no podrá aprender. cualquier conexión más profunda entre dos palabras. Es por eso que introduciremos pesos en el bloque de auto-atención. ¿Pero donde? Para que el modelo aprenda las conexiones más profundas entre palabras, presentaremos las ponderaciones en tres ubicaciones: las incrustaciones de palabras de entrada, la comparación de similitudes de productos escalares y el paso final de volver a pesar las incrustaciones de palabras. Además, un beneficio más de introducir las palabras en estos lugares es que las formas / dimensiones de los vectores multiplicados no cambian. Recuerda que si tenemos un vector de forma 1 xk y lo multiplicamos por una matriz de forma kxk, esto debería resultar en un vector de forma 1 xk. Por lo tanto, incluso si introducimos pesos en las ubicaciones descritas, nada debería cambiar en dimensionalidad o forma.
Es por eso que debemos introducir pesos en los lugares donde tenemos la palabra original incrustando vectores, v1, v2, v3 y v4, porque la forma de estos vectores es la misma, e incluso si introducimos una matriz de pesos kxk, la las formas de estos seguirán siendo 1 x k. Las tres ubicaciones en las que usamos los vectores de incrustación originales son las incrustaciones de palabras de entrada, la similitud del producto escalar cuando comparamos cada palabra con otras palabras y durante el proceso de pesaje final cuando multiplicamos los pesos normalizados por las incrustaciones de palabras originales. Con pesos, nuestros cálculos se verán como sigue:
(v1 * Mk) * (v3 * Mq) = S31 (v2 * Mk) * (v3 * Mq) = S32 (v3 * Mk) * (v3 * Mq) = S33 (v4 * Mk) * (v3 * Mq) = S34 S31 -> SoftMax -> W31 S32 -> SoftMax -> W32 S33 -> SoftMax -> W33 S34 -> SoftMax -> W34 (v1 * Mv) * W31 = Y31 (v2 * Mv) * W32 = Y32 (v3 * Mv) * W33 = Y33 (v4 * Mv) * W34 = Y34 Y31 + Y32 + Y33 + Y34 = Y3
Como puede ver, siempre que usemos las incrustaciones de palabras originales v1, v2, v3 y v4, multiplicamos esos vectores con las matrices de peso correspondientes. Mk, Mq y Mv son simplemente las matrices / pesos clave, de consulta y de valor que aprenderá el modelo. Recuerde que en los cálculos anteriores, solo hice la operación de atención personal para una palabra, v3. En realidad, esto le sucederá a todas las palabras simultáneamente a través de la vectorización y algo de álgebra lineal.
Tenga en cuenta que en el diagrama anterior, cuando multiplico las matrices de clave, consulta y valor con sus respectivos vectores de incrustación, hago una multiplicación de matrices, no un producto escalar.
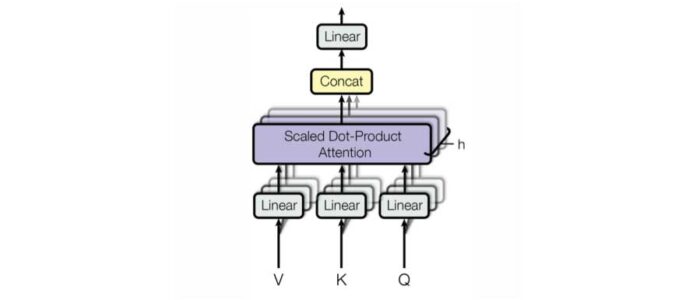
Atención de múltiples cabezas
Aunque pueda parecer razonable que un bloque de auto-atención sea suficiente para que una palabra adquiera relevancia contextual, no es así. A menudo, una palabra tendrá que prestar atención a muchas otras palabras, y es posible que solo un bloque de auto-atención no sea suficiente atención para varias palabras. Esto es especialmente evidente en ejemplos en los que el texto de entrada es muy grande (por ejemplo, para una tarea de resumen de texto). Por lo tanto, un par de palabras que tienen relevancia contextual a veces no recibirán suficiente atención como para hacer un cambio observable en sus respectivas incorporaciones.
Para solucionar este problema, usaremos un bloque de atención de múltiples cabezas. El bloque de atención de varios encabezados amplía la capacidad del modelo para centrarse en diferentes posiciones en el texto de entrada.
Un bloque de atención de múltiples cabezas es esencialmente lo mismo que un bloque de auto-atención regular, pero en lugar de solo un bloque de atención, el bloque de atención de múltiples cabezas contendrá múltiples bloques de auto-atención que operan en paralelo. Estos bloques de auto-atención no compartirán ningún peso; lo único que compartirán son las mismas incrustaciones de palabras de entrada. El número de bloques de atención propia en un bloque de atención de múltiples cabezas es un hiperparámetro del modelo. Suponga que elegimos tener n bloques de atención propia. La consecuencia de esto es que después de que todos los cálculos individuales sean realizados por cada uno de los bloques de auto-atención, tendremos n incrustaciones para cada palabra. Para solucionar este problema, el bloque de atención de múltiples cabezas concatena estas incrustaciones y finalmente las pasa a través de una capa densa. Recuerde que queremos que la forma y el número de las entradas sean iguales a la forma y el número de las salidas. Debido a que concatenamos las incorporaciones, mantenemos el número de entradas igual al número de salidas. Debido a que pasamos las salidas concatenadas a través de una capa densa, pudimos controlar su forma, asegurándonos de que sea la misma que la forma de las entradas.
Resumen
El bloque de auto-atención toma como entrada incrustaciones de palabras de palabras en una oración y devuelve el mismo número de incrustaciones de palabras pero con contexto. Lo logra a través de una serie de matrices de ponderación de clave, consulta y valor. El bloque de atención de múltiples cabezas consta de múltiples bloques de auto-atención que operan en paralelo y no comparten pesos. Después de que cada uno de los bloques de auto-atención devuelve nuevas incrustaciones de palabras contextualizadas, el bloque de atención de múltiples cabezas concatena estas nuevas incrustaciones y las pasa a través de una capa densa para controlar la forma de la salida. Esto permite que la incrustación de una palabra reciba suficiente atención que hará un cambio observable en su incrustación.
Espero que haya encontrado este contenido fácil e intuitivo de entender. Si cree que necesito dar más detalles o aclarar, deje un comentario a continuación.
Gracias por leer.
Referencias
Atención es todo lo que necesita (arxiv.org).






Añadir comentario