
Muy buenas, les saluda Miguel y en esta ocasión les traigo un nuevo post.
Índice
Muchos conceptos están relacionados
¿Qué son los modelos mentales?
La forma más sencilla de describirlos es que son patrones. Aprende los patrones una vez y luego puede aplicarlos a otros escenarios y temas para aprender cosas nuevas más rápido.
Los modelos mentales son una forma de comprender el mundo.
Dado que hay tantos conceptos diferentes en la ingeniería de software, los modelos mentales pueden ser extremadamente beneficiosos para que los desarrolladores aprendan nuevos conceptos.
La mayoría de la gente tendría dificultades para memorizar más de 100 algoritmos diferentes, pero es mucho más manejable cuando puede agruparlos por principios.
Un ejemplo
Recuerdo a un hombre que ganó un premio en una feria al memorizar una cadena de 100 dígitos en una hora.
5778563856325719554823908754396193272936058610938258472045803948555752930485720948623046984501993756
¡Qué asco! La mayoría de la gente tendría dificultades para memorizar todos estos dígitos. ¿Pero el secreto de este hombre? Usó números de teléfono como modelo mental.
(577) 856-3856
(325) 719-5548
(239) 087-5439
(619) 327-2936
(058) 610-9382
(584) 720-4580
(394) 855-5752
(930) 485-7209
(486 ) 230-4698
(450) 199-3756
En lugar de intentar meter en su cabeza una secuencia anormalmente grande de números, la dividió en diez partes individuales y fingió que eran números de teléfono.
Antes de la era de los teléfonos inteligentes y las listas de contactos, la mayoría de nosotros nos comprometíamos números de teléfono de memoria de todos modos. Realizar diez secuencias pequeñas es mucho más manejable en comparación con una secuencia grande de 100 números.
Además, la visualización de números de teléfono hace que los dígitos sean más fáciles de memorizar. Todos aplicamos modelos que hemos aprendido previamente a nuevos conceptos, ya sea de forma consciente o inconsciente.
Usando este ejemplo como referencia, analicemos algunos modelos mentales útiles en programación y la amplia variedad de temas que pueden ayudarlo a aprender más rápido.
Optimización local frente a global
Cuando trabaja en un sistema en el que puede tomar decisiones, puede priorizar las cosas de las dos formas siguientes:
- Hacer algo que le beneficie inmediatamente o «localmente».
- Hacer algo que le beneficie en el futuro o «globalmente».
Por ejemplo, hoy puedo optar por comer comida chatarra. Me beneficia de inmediato porque estoy feliz. Pero el costo es la salud a largo plazo. Por el contrario, puedo optar por comer una comida saludable de verduras y cereales integrales. No estoy tan contento con eso, pero hay un beneficio a largo plazo al hacer esto, especialmente repetidamente.
Del mismo modo, la optimización local frente a la global se muestra en muchos conceptos de CS:
Algoritmos de enrutamiento
En la búsqueda y el recorrido, puede elegir el mejor paso siguiente según el punto de vista del nodo actual (local) o desde el punto de vista de toda la cuadrícula / árbol (global).
La optimización global significa mejores resultados generales, pero a menudo a un costo; por ejemplo, pasará más ciclos de reloj recopilando datos globales y más memoria almacenándolos.
A continuación, dada una red en chip ( NoC ) donde necesito enrutar datos desde el punto A al punto B, las opciones optimizadas localmente dan como resultado una ruta y una latencia general diferentes que una opción optimizada globalmente.

A cambio, para que cada uno de los nodos haga esa elección óptima globalmente, todos los nodos deben sincronizar su información entre sí en las tablas de enrutamiento, lo que consume memoria y energía.
Algoritmos de ruta más corta
Los algoritmos de ruta más corta son un tipo específico de algoritmo de enrutamiento a través de una matriz, un gráfico, etc. Aquí hay una compensación en la cantidad de memoria y procesamiento que se realiza. Estás explorando muchas, muchas ramas y nodos, y solo estás eligiendo la mejor.
Por su naturaleza, el resultado final es siempre óptimo a nivel mundial, pero a veces utilizarán la optimización local para llegar allí.
Por ejemplo, el algoritmo de Bellman-Ford utiliza una serie de decisiones óptimas a nivel local para actualizar continuamente la distancia más corta a cada nodo en iteraciones a medida que descubre más pesos de vértice. El resultado final es el óptimo global.
Árboles de decisión y gráficos
Las computadoras y la inteligencia artificial en los juegos usan árboles de decisiones para tomar decisiones sobre el siguiente mejor movimiento.
Cada decisión o cambio de estado en el juego tiene consecuencias posteriores y reverberantes, y la computadora explora ese árbol para minimizar su pérdida o maximizar sus ganancias.
Tome el ejemplo (muy rudimentario) a continuación:

Puede verlo claramente, el movimiento B es la mejor opción. Pero si, por ejemplo, tiene la dificultad de una computadora configurada en Fácil, entonces solo puede esperar una decisión por delante. Posteriormente decide que el movimiento A es mejor porque +1> -1 y procede a perder.
Ajustar el nivel de dificultad de la IA normalmente es ajustar la profundidad que la IA explorará en el árbol de decisiones. Una mayor dificultad significa que la computadora buscará más abajo en el árbol y, posteriormente, optimizará su decisión basándose en más y más posibilidades, una base más “global”.
Algoritmos de clasificación
Muchos algoritmos de clasificación utilizan optimización local. Por ejemplo, Bubble Sort utilizará la fuerza bruta y comparará cada elemento con su vecino inmediato y lo intercambiará si es necesario. Esto es globalmente subóptimo porque un elemento puede realizar varios intercambios antes de encontrar el lugar que le corresponde.
Mergesort es un algoritmo Divide and Conquer que divide la lista de elementos y los maneja de forma recursiva en pequeñas partes. La parte de división es un problema de optimización local en el que solo necesita comparar dos elementos. Al fusionar todo de nuevo, combina los efectos de varias decisiones locales en el resultado final.
Almacenamiento en caché
El almacenamiento en caché es el proceso de almacenar los resultados de una operación. Las llamadas futuras a esa operación solo obtendrán el resultado almacenado en lugar de volver a calcular o ejecutar la operación, lo que dará como resultado un rendimiento más rápido.

De hecho, utiliza el «almacenamiento en caché» en su vida diaria. Las cosas que usas y tocas con frecuencia están cerca de ti y se puede acceder a ellas rápidamente (por ejemplo, tu teléfono), mientras que las cosas que no tocas con mucha frecuencia están escondidas (por ejemplo, tu chaqueta fuera de temporada).
Internet
La implementación más común de almacenamiento en caché que conoce la gente es almacenamiento en caché del navegador. El contenido de las páginas web se almacena, lo que agiliza las cargas posteriores de la misma página.
Pero el almacenamiento en caché en realidad ocurre más allá de su navegador. Hay Almacenamiento en caché de DNS (por ejemplo, se almacenan las resoluciones de IP para sitios web visitados con frecuencia). También hay caché de red (los sitios web que se visitan con frecuencia en la misma red se almacenan y recuperan para varios usuarios).
El almacenamiento en caché está arraigado en las profundidades de Internet, incluso en conmutadores y enrutadores que simplemente enrutan el tráfico por todo el mundo.
Hardware
El almacenamiento en caché también se utiliza a nivel de hardware. Es posible que haya oído hablar de las cachés L1, L2 y L3 de un procesador o chip.
Los chips de computadora suelen tener varias capas de almacenamiento en caché. Siempre que un caché falla (p. Ej., L1), comprobará la siguiente capa de caché (L2) en busca de un acierto.
Cada capa de la caché tiene un rendimiento más lento y un tamaño más grande, pero aún así es mucho más rápido que obtener un fragmento de datos de la memoria. Si fallan todos los cachés, finalmente obtenemos datos de la DRAM (memoria principal), y si la DRAM falla, usamos la memoria de intercambio en el disco duro (la más lenta).
Programación dinámica y memorización
Cuando utiliza algoritmos recursivos, a veces se encuentra calculando la misma información una y otra vez.
Un ejemplo de esto es Fibonacci recursivo:

Ignorando los casos base, que solo devolverán 0 y 1, puede ver que f (2) se llama tres veces y f (3) se llama dos veces. Ahora, si lo aumentamos en un nivel …

¿Ves lo desordenado que se está poniendo? Cada nivel adicional de Fibonacci aumenta el número de cálculos duplicados que hacemos. Y esta es la razón por la que es útil almacenar, o «almacenar en caché», resultados como en la programación dinámica.
A medida que el árbol de Fibonacci crece, las ganancias obtenidas del almacenamiento en caché de los resultados intermedios aumentan (p. Ej., f (10) llamadas f (2) 34 veces, lo que significa que ha guardado 33 operaciones redundantes y apila punteros).
Servidor de cliente
Los modelos cliente / servidor existen en muchas facetas, generalmente en el diseño de aplicaciones de software.
El principio es que el “servidor” suele ser el principal facilitador de acciones e información; reciben solicitudes, procesan datos y luego envían respuestas e información a los clientes según sea necesario.

Los clientes suelen realizar su propio procesamiento localmente, pero el servidor es la «fuente de la verdad».
Juegos multijugador
Los juegos multijugador, como los FPS en línea, utilizan un modelo cliente / servidor. Para evitar trampas, el servidor mantiene la «autoridad» sobre todas las acciones que ocurren en el juego.
Los clientes, o jugadores individuales en casa, realizan acciones haciendo una solicitud al servidor, y el servidor permite las acciones y actualiza a todos los demás según sea necesario.
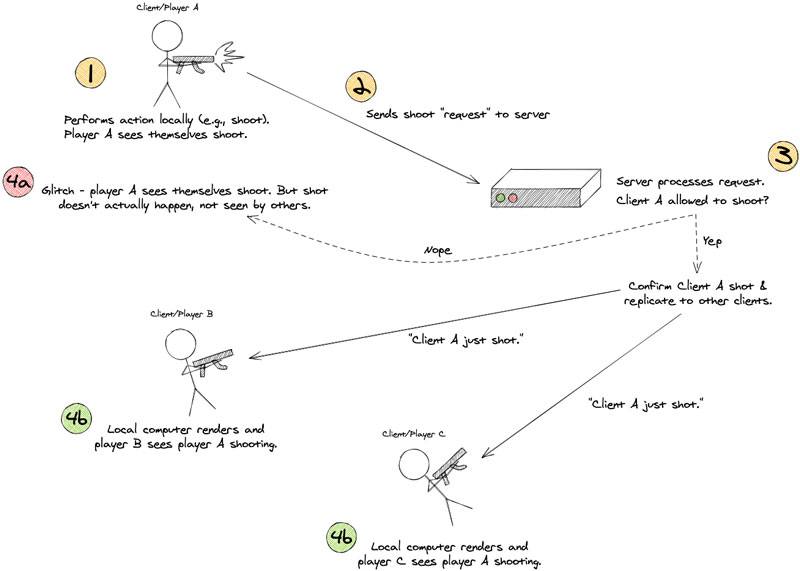
Aplicaciones web
Muchos de los servicios y aplicaciones web que utiliza suelen ser cliente / servidor.
Por ejemplo, si está utilizando una aplicación de lista de tareas sincronizada y multiplataforma, la aplicación con la que interactúa en su teléfono es el cliente.
Siempre que realiza una actualización, el cambio ocurre localmente, pero se realiza una solicitud a un servidor para mantener este cambio en algún lugar de la nube (si está utilizando una aplicación multiplataforma sincronizada).
Es lo mismo con otras aplicaciones como las redes sociales: ves una interfaz localmente, haces algunas acciones y se envía una solicitud a un servidor o servicio en algún lugar para persistir y luego replicar esas acciones.
Los nuevos tweets o publicaciones se escriben en una base de datos en algún lugar, y luego otros clientes (usuarios) ven sus últimos memes y fotos de gatos.
Conclusión
Los modelos mentales son extremadamente útiles para aprender cosas más rápido. Puede usar patrones que ha visto antes para comprender nuevos conceptos.
Esta primera historia es solo una muestra de los muchos patrones que puede encontrar en el mundo del desarrollo de software.
Espero que este artículo te haya sido útil.






Añadir comentario