
Escribir poemas es una de las tareas más difíciles en PNL y no solo en PNL, también es un desafío para la mayoría de los humanos. Y, sin embargo, eso es precisamente lo que vamos a conseguir en este artículo.
Vamos a escribir un modelo de red neuronal capaz de generar sonetos (un tipo de poema más famoso de los que está escrito por Shakespeare). Lo lograremos usando la incrustación de palabras, más sobre esto más adelante.
Índice
Cargando los datos
Puede obtener los datos para entrenar este generador de poesía de aquí:
Comencemos cargando los datos reales y viendo una pequeña muestra de ellos, digamos los primeros 300 caracteres.
data = open('./sonnets.txt’).read()
data[0:300]
La salida del bloque de código anterior se parece a esto:
De las criaturas más bellas deseamos crecer, para que la rosa de la belleza no muera nunca, pero como lo haría la más madura con el tiempo, su tierno heredero podría llevar su recuerdo: pero tú, contraído por tus propios ojos brillantes, alimentas tu llama de luz. con combustible autosustentable, haciendo una hambruna donde la abundancia.
Cargar los paquetes
from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.models import Sequential from tensorflow.keras.optimizers import Adam from tensorflow.keras import regularizers import tensorflow.keras.utils as ku import numpy as np
Para verificar la versión de TensorFlow, use el siguiente bloque de código
import tensorflow as tf print(tf.__version__)
Debería salir 2.1.0
Tokenizando los datos de entrenamiento
Puede lograr esto usando el siguiente bloque de código:
tokenizer = Tokenizer() corpus = data.lower().split(“\ n”) tokenizer.fit_on_texts(corpus) total_words = len(tokenizer.word_index) + 1 print(‘Total number of words in corpus:’,total_words)
Lo que hace es dividir los datos de entrenamiento en líneas individuales. Luego, divide aún más estas líneas en palabras y asigna un índice de palabras único a cada una. Esto se llama incrustación de palabras .
Además, contar el número de índices de palabras nos da el número total de palabras únicas.
Preparando los datos para el entrenamiento
Esta es la parte más importante de todo este guión y se puede dividir en cinco pasos. Así que entremos en ello, ¿de acuerdo?
Para cada línea del archivo de texto (datos de entrenamiento) , realizaremos las siguientes operaciones:
Puedes hacerlo usando lo siguiente:
tokenizer.texts_to_sequences([line])Una vez que convierta el texto en una secuencia, la salida se vería como la siguiente:
[34, 417, 877, 166, 213, 517]Esto se lograría utilizando los índices de palabras únicos discutidos anteriormente.
El siguiente paso es crear una secuencia N_gram que se vería así:
[34,417] [34,417,877] [34,417,877,166] [34,417,877,166,213] [34,417,877,166,213,517]
Empiece por encontrar la longitud de la secuencia más larga y luego rellenaría el resto de las secuencias para que coincida con esa longitud.
Puede hacer esto usando lo siguiente:
pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre')
El resultado de esto se vería así:
[0,0,0,0,34,417] [0,0,0,34,417,877] [0,0,34,417,877,166] [0,34,417,877,166,213] [34,417,877,166,213,517]
Aquí es donde entra la parte más interesante, vamos a considerar el último elemento en las matrices de secuencia N_gram que obtuvimos arriba como etiquetas y el resto de la matriz como predictores. Así por ejemplo:
PREDICTORS LABLES [0,0,0,0,34] 417 [0,0,0,34,417] 877 [0,0,34,417,877] 166 [0,34,417,877,166] 213 [34,417,877,166,213] 517
El código para todos los pasos anteriores se condensa en el siguiente bloque de código:
# create input sequences using list of tokensinput_sequences = [] for line in corpus: token_list = tokenizer.texts_to_sequences([line])[0] for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # get max sequence length max_sequence_len = max([len(x) for x in input_sequences]) #pad the sequence input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding=’pre’)) # create predictors and label predictors, label = input_sequences[:,:-1],input_sequences[:,-1] label = ku.to_categorical(label, num_classes=total_words)
Definiendo el modelo
En este punto, resulta obvio lo que vamos a predecir. El modelo se comportará como un clasificador de texto puro donde el número de clases es igual al número total de palabras únicas y la entrada son los predictores definidos anteriormente.
# Defining the model. model = Sequential() model.add(Embedding(total_words,100,input_length=max_sequence_len-1)) model.add(Bidirectional(LSTM(150,return_sequences=True))) model.add(Dropout(0.18)) model.add(Bidirectional(LSTM(100))) model.add(Dense(total_words/2,activation=’relu’,kernel_regularizer=regularizers.l2(0.01))) model.add(Dense(total_words,activation=’softmax’)) model.compile(loss=’categorical_crossentropy’,optimizer = ‘adam’,metrics = [‘accuracy’]) print(model.summary())
El modelo definido por esto se vería así:
Model: "sequential_20" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_20 (Embedding) (None, 10, 100) 321100 _________________________________________________________________ bidirectional_41 (Bidirectio (None, 10, 300) 301200 _________________________________________________________________ dropout_21 (Dropout) (None, 10, 300) 0 _________________________________________________________________ bidirectional_42 (Bidirectio (None, 200) 320800 _________________________________________________________________ dense_48 (Dense) (None, 1605) 322605 _________________________________________________________________ dense_49 (Dense) (None, 3211) 5156866 ================================================================= Total params: 6,422,571 Trainable params: 6,422,571 Non-trainable params: 0 _________________________________________________________________ None
Ahora, para comenzar a entrenar el modelo, esto podría llevar un par de horas o minutos, dependiendo del hardware en el que se esté ejecutando.
history = model.fit(predictors, label, epochs=100, verbose=1)

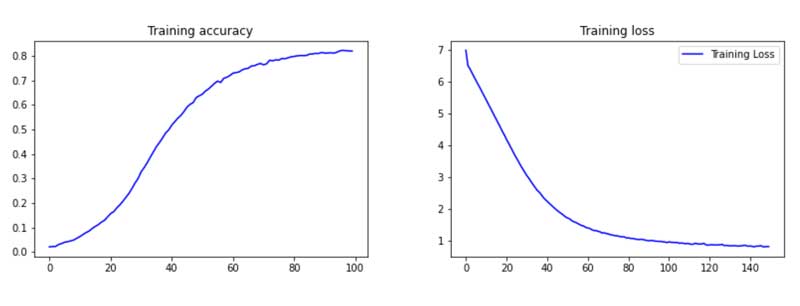
Aquí vamos a trazar 2 gráficas precisión vs épocas y pérdida vs épocas .
Para probar el modelo tenemos que dar 2 entradas:
- Ingrese texto o texto semilla para que la red pueda comenzar a predecir.
- La cantidad de palabras que desea que prediga la red.
seed_text = “O Ray of sunshine”
next_words = 30
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len- 1, padding=’pre’)
predicted = model.predict_classes(token_list, verbose=0)
output_word = “”
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += “ “ + output_word
print(seed_text)
El poema que nuestra red escribió tan elocuentemente es el siguiente:
Oh, rayo de sol, este pecado crece en ti, así que yace nuevo, más querido, su fuerte piel, prueba que has visto su pecho ser alegre, comienza a contar que sus mejillas valen una nueva y fuerte ...
Finalmente, esto se hizo usando la incrustación de palabras, en el próximo artículo veamos cómo la incrustación a nivel de personaje se compara con este enfoque.
Gracias por leer esto, espero que te haya resultado interesante.





Añadir comentario