
Muy buenas, soy Miguel y aquí les traigo este post.
Uso del aprendizaje profundo para la clasificación de sonido
Todos los días escuchamos diferentes sonidos y es parte de nuestra vida. Los seres humanos pueden diferenciar fácilmente entre sonidos, pero lo genial que será si la computadora también puede clasificar los sonidos en categorías.
En esta publicación de blog, aprenderemos técnicas para clasificar los sonidos urbanos en categorías utilizando el aprendizaje automático con redes neuronales.
El conjunto de datos se toma de una competencia en análisis vidya llamada Sonido urbano. Este conjunto de datos contiene 8732 extractos de sonido etiquetados de sonidos urbanos de 10 clases: air_conditioner, car_horn, children_playing, dog_bark, drill, enginge_idling, gun_shot, jackhammer, siren y street_music.
Usaré la biblioteca python librosa para extraer características numéricas de clips de audio y usaré esas características para entrenar un modelo de red neuronal.
Primero, obtengamos todas las bibliotecas necesarias,
import IPython.display as ipd import os import numpy as np import pandas as pd import matplotlib.pyplot as plt import librosa from tqdm import tqdm from sklearn.preprocessing import StandardScaler from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.optimizers import Adam
El conjunto de datos está disponible en una unidad de Google, se puede descargar desde aquí.
El conjunto de datos contiene train, carpeta de prueba en la que se guardan extractos de sonido y hay train.csv y test.csv que tienen etiquetas de cada extracto de sonido.
Usaré solo la carpeta del tren para entrenamiento, validación y prueba, contiene 5435 sonidos etiquetados.
data=pd.read_csv('/content/drive/MyDrive/colab_notebook/train.csv')
data.head()#To see the dataset
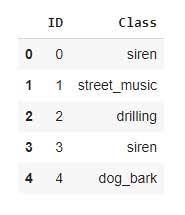
Escuchemos cualquier sonido aleatorio del conjunto de datos,
ipd.Audio(‘/content/drive/My Drive/colab_notebook/Train/123.wav’)
Ahora, el paso principal es extraer características del conjunto de datos. Para esto, usaré la biblioteca de librosa. Es una buena biblioteca para usar con archivos de audio.
Usando la biblioteca de librosa, extraeré cuatro características de los archivos de audio. Estas características son coeficientes cepstrales de frecuencia Mel (MFCC), tonnetz, espectrograma en escala mel y cromagrama de una forma de onda.
mfc=[]
chr=[]
me=[]
ton=[]
lab=[]
for i in tqdm(range(len(data))):
f_name='/content/drive/My
Drive/colab_notebook/Train/'+str(data.ID[i])+'.wav'
X, s_rate = librosa.load(f_name, res_type='kaiser_fast')
mf = np.mean(librosa.feature.mfcc(y=X, sr=s_rate).T,axis=0)
mfc.append(mf)
l=data.Class[i]
lab.append(l)
try:
t = np.mean(librosa.feature.tonnetz(
y=librosa.effects.harmonic(X),
sr=s_rate).T,axis=0)
ton.append(t)
except:
print(f_name)
m = np.mean(librosa.feature.melspectrogram(X, sr=s_rate).T,axis=0)
me.append(m)
s = np.abs(librosa.stft(X))
c = np.mean(librosa.feature.chroma_stft(S=s, sr=s_rate).T,axis=0)
chr.append(c)
Tengo 186 funciones para cada archivo de audio con sus respectivas etiquetas.
Después de extraer características de los archivos de audio, guarde las características porque tomará mucho tiempo extraerlas.
mfcc = pd.DataFrame(mfc)
mfcc.to_csv('/content/drive/My Drive/colab_notebook/mfc.csv', index=False)
chrr = pd.DataFrame(chr)
chrr.to_csv('/content/drive/My Drive/colab_notebook/chr.csv', index=False)
mee = pd.DataFrame(me)
mee.to_csv('/content/drive/My Drive/colab_notebook/me.csv', index=False)
tonn = pd.DataFrame(ton)
tonn.to_csv('/content/drive/My Drive/colab_notebook/ton.csv', index=False)
la = pd.DataFrame(lab)
la.to_csv('/content/drive/My Drive/colab_notebook/labels.csv', index=False)
Concatenar características en una matriz para que se pueda pasar al modelo.
features = []
for i in range(len(ton)):
features.append(np.concatenate((me[i], mfc[i],
ton[i], chr[i]), axis=0))
Codifique las etiquetas para que el modelo pueda entenderlas.
la = pd.get_dummies(lab) label_columns=la.columns #To get the classes target = la.to_numpy() #Convert labels to numpy array
Ahora normalice las características para que los descensos de gradiente puedan converger más rápidamente.
tran = StandardScaler() features_train = tran.fit_transform(features)
Ahora crearé un conjunto de datos de entrenamiento, validación y prueba.
feat_train=features_train[:4434] target_train=target[:4434] y_train=features_train[4434:5330] y_val=target[4434:5330] test_data=features_train[5330:] test_label=lab['0'][5330:]print("Training",feat_train.shape) print(target_train.shape) print("Validation",y_train.shape) print(y_val.shape) print("Test",test_data.shape) print(test_label.shape)

model = Sequential() model.add(Dense(186, input_shape=(186,), activation = 'relu')) model.add(Dense(256, activation = 'relu')) model.add(Dropout(0.6)) model.add(Dense(128, activation = 'relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation = 'softmax')) model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
Este es el modelo final que se utilizará para la formación.
history = model.fit (feat_train, target_train, batch_size = 64, epochs = 30, validation_data = (y_train, y_val))
El modelo se entrenará para epoch = 30 y tiene un tamaño de lote de 64.
Después de entrenar el modelo, da una precisión de validación del 92%.
Ahora veamos cómo funcionará nuestro modelo en el conjunto de datos de prueba.
predict = model.predict_classes (test_data) # Para predecir etiquetas
Esto obtendrá los valores ahora para obtener la predicción como clases.
predicción = [] para i en predecir: j = label_columns [i] prediction.append (j)
La predicción tiene 104 etiquetas de prueba y ahora calcula cuántas se predicen correctamente.
k = 0
para i, j en zip (test_label, predicción):
si i == j:
k = k + 1
De 104 etiquetas, este modelo ha predicho correctamente 94 etiquetas, lo cual es muy bueno.
En este blog, hemos discutido cómo extraer características de archivos de audio usando la biblioteca librosa y luego construir un modelo para clasificar archivos de audio en diferentes clases.
Espero que te hay sido de utilidad. Gracias por leer este post.





Añadir comentario