
Muy buenas, soy Miguel y hoy les traigo otro post.
Índice
20 trucos geniales de Pandas que debes usar todos los días
A menos que sea nuevo en Data Science con Python o tenga algún tipo de dispositivo conectado a su enrutador que bloquee todos los paquetes entrantes relacionados con Pandas, probablemente haya oído hablar de Pandas.
Pandas no solo cumple y supera todas las expectativas en su mayor parte cuando se trata de trabajar con datos, sino que también está vinculado a Numpy y funciona increíblemente bien con él, consolidándolo aún más en el maravilloso ecosistema de paquetes de ciencia de datos Pythonic.
Si bien Pandas es popular y la mayoría de los científicos que trabajan con Python lo utilizan con mucha frecuencia, también es una biblioteca bastante profunda con muchas características.
Muchas de estas características pueden pasarse por alto fácilmente, pero su valor a menudo no puede subestimarse. Afortunadamente, hoy he organizado 20 de las funciones menos conocidas en la biblioteca de Pandas que ayudarán a cualquier científico de datos en su camino para dominar el paquete.
Los marcos de datos son la característica principal de la biblioteca Pandas. Aunque los marcos de datos son una gran funcionalidad por sí mismos, sin grandes funciones y operaciones que los acompañen, terminan siendo diccionarios glorificados.
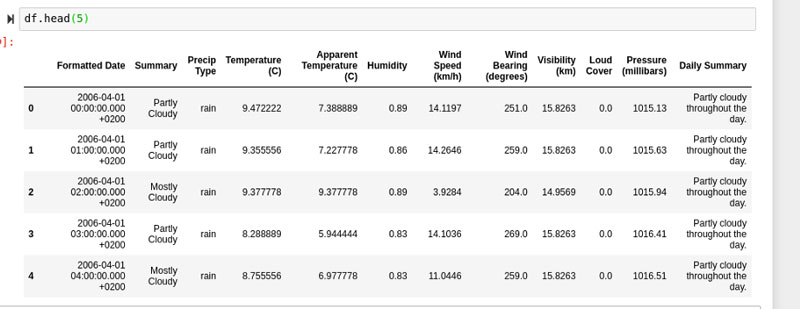
Afortunadamente, Pandas lo tiene cubierto con estas formas realmente geniales de explorar sus datos, limpiar sus datos y ajustar sus datos. Para todos los ejemplos a continuación, trabajaré con este marco de datos:

Los datos son datos meteorológicos históricos de fechas tan tempranas como 1910 y tan tardías como 2006
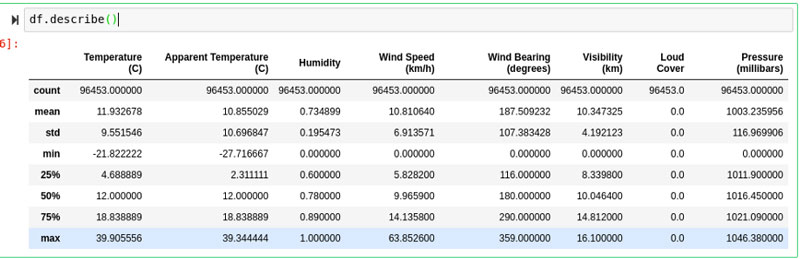
Una de las características más subestimadas de Pandas es una función simple llamada describe (). El uso de la función de descripción en un marco de datos produce un resultado muy estadístico que le dirá todo lo que necesita saber sobre los valores de cada columna de forma independiente.
Esta es una excelente manera de comprender dónde se encuentran la mayoría de los datos en una columna determinada sin solo tener que considerar la media.
Tener una idea de la desviación estándar, los valores mínimo-máximo y la media también dará una gran inclinación en cuanto a cuánta varianza hay en los datos. Usar esta función es una excelente manera de obtener todas las siguientes estadísticas para cada columna increíblemente rápido:
- Media.
- Contar.
- Desviación Estándar.
- 1er cuartil.
- 2do cuartil (mediana).
- 3er cuartil.
- Valor mínimo.
- Valor máximo.
df.describe()
La función groupby () es una función fantástica que se puede utilizar para reorganizar sus observaciones en función de valores categóricos o rangos continuos por valor numérico. La función simplemente pondrá los valores idénticos o similares más cercanos.
df.groupby(['Temperature (C)']).mean()

La función de pila se puede utilizar para devolver tanto un marco de datos como un tipo de serie con niveles más internos. Los nuevos niveles más internos se crean girando el marco de datos. El primer parámetro controla qué nivel o niveles se apilan:
df.stack([0])
Stack realmente no parece haber hecho mucho con estos datos. Esta función es una que solo se puede sentir cuando la tabla es mayoritariamente pivotante.
La función de aplicación se usa para aplicar código aritmético o lógico en todo un marco de datos o tipo de serie usando una función de Python.
Aunque esto ciertamente se puede aplicar a un marco de datos, solo lo voy a aplicar a una serie porque este marco de datos contiene tanto cadenas como tipos de datos de fecha y hora.
df["Temperature (C)"].apply(np.sqrt)

La función de información se puede utilizar en un marco de datos para proporcionar información sobre el marco de datos que generalmente se relaciona con el rendimiento más que con las estadísticas.
Esto es útil si desea verificar las asignaciones de memoria o los tipos de datos de cada serie dentro de un marco de datos.
df.info()

La consulta es una función de Pandas que permite aplicar una máscara condicional en todo un marco de datos.
La única diferencia significativa entre la consulta y una máscara condicional típica es que la función de consulta puede tomar una cadena que se interpretará como una declaración condicional, mientras que una máscara condicional enmascarará los datos con valores booleanos y luego devolverá las condiciones que son verdaderas.
df.query('Humidity < .89')

La función cumsum se puede utilizar para obtener la suma acumulativa de los marcos de datos y los tipos de series de Pandas. Esto significa que los números se sumarán en orden descendente y se sumarán entre sí continuamente a medida que avanzan.
df.cumsum()
 Malas noticias.
Malas noticias.
Desafortunadamente, el núcleo parece haber muerto. Dado que mi kernel de Jupyter se siente más emocional hoy, la cortaré (es una ella) un descanso y, en su lugar, simplemente ejecutaré la función en una sola serie.

Una de mis características favoritas dentro de la biblioteca Pandas es fácilmente la capacidad de enmascarar marcos de datos con condiciones. Aunque hay una manera de hacer esto con el método filter! ().
En mi idioma favorito, Julia, esto es algo que realmente extraño y desearía que pudiera incluirse en el idioma. En primer lugar, debe establecer una condición, para este ejemplo usaremos una velocidad del viento por debajo de 14.
our_mask = df["Wind Speed (km/h)"] < 14
A continuación, aplicaremos esta máscara simplemente estableciendo algo igual a los valores booleanos como índice:
seconddf = df[our_mask]
Ahora nuestro marco de datos no contiene velocidades del viento mayores o iguales a 14:
![df[conditional-mask]](https://manualestutor.com/wp-content/uploads/dfconditional-mask.jpg)
La fusión es lo opuesto a la función pivote, que pondrá sus datos en un formato lateral. Esto es útil si desea cambiar cuáles serán las observaciones y cuáles serán las características.
Sin embargo, es importante tener en cuenta que es posible que esto no funcione tan bien como esperaba sin proporcionar parámetros o sin cambiar la estructura de su marco de datos en algunos casos. Un ejemplo de exactamente eso es el marco de datos con el que estoy trabajando:
df = df.melt()

¿Alguna vez se ha encontrado con datos que se ven así por alguna razón? :

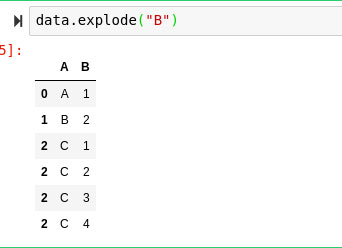
Todos los demás valores son observaciones precisas con un solo entero, excepto las observaciones que corresponden a: A en el marco de datos. Afortunadamente, podemos simplemente ejecutar explotar en nuestro marco de datos para corregir esto.
Explode “explotará” todos los conjuntos iterables dentro del marco de datos y los pondrá en observaciones individuales.
data.explode("B")
Tenemos un marco de datos con muchas categorías y queremos abordar una solución a un problema de clasificación. El único problema es que no queremos usar un modelo que sea propenso a sobreajustarse si tenemos tan pocas categorías que el modelo termina siendo exagerado.
Este sería un escenario bastante común en la vida cotidiana típica de un científico de datos. Afortunadamente, la solución a este problema es realmente simple: se necesita un recuento de todos los valores únicos. ¡Aún más afortunadamente, Pandas hace que hacerlo sea increíblemente fácil con la función nunique!
df.nunique()
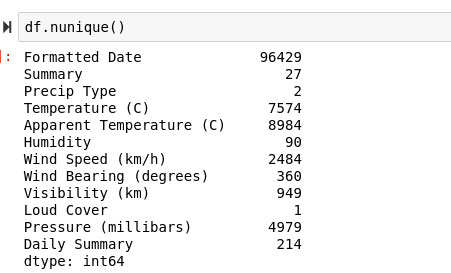
Esto proporcionará una lista completa de todas las características en nuestro marco de datos y sus correspondientes recuentos de valores únicos.
Otra cosa con la que podría encontrarse cuando trabaja con datos sucios son los tipos que inicialmente se presume que son algo que no lo son. Un gran ahorro de tiempo potencial para cambiar estos tipos de datos dentro de su marco de datos es usar df.infer_objects ().
La función infer_objects toma una suposición fundamentada sobre qué tipo de datos debería ser cada columna y establece toda la serie en ese tipo.
df.infer_objects()
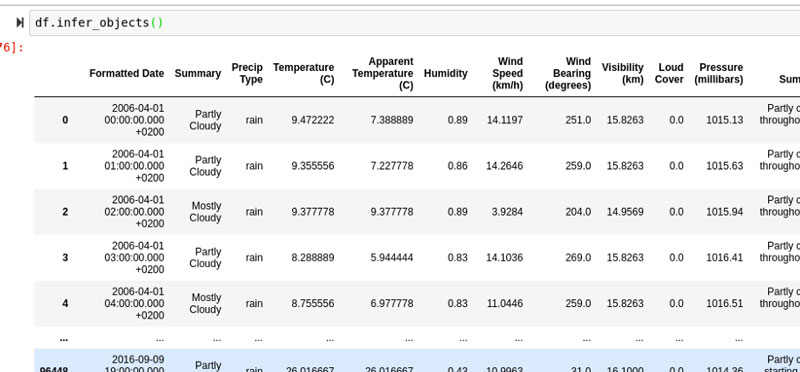
El uso de memoria es una función para la que la mayoría ya podría haber asumido el rendimiento. Si bien obtuvimos una idea amplia del uso de memoria dentro de nuestro marco de datos usando la función info (), memory_usage es mucho más completo y nos permitirá averiguar qué columnas consumen la mayor parte de nuestra memoria.
df.memory_usage()
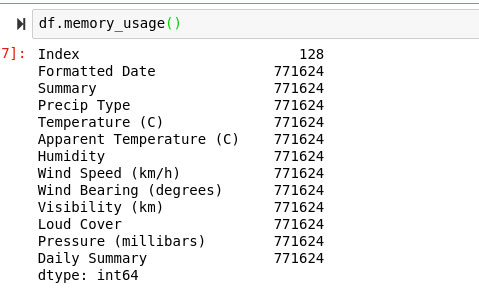
La función select_dtypes se puede utilizar para extraer ciertas columnas de un marco de datos según el tipo. Un gran ejemplo de cómo esto podría ser útil es para algo como aplicar, donde queríamos aplicar np.sqrt () a todo el marco de datos, pero solo pudimos hacerlo con una sola serie debido a las cadenas en nuestros datos cuadro.
df.select_dtypes(float).apply(np.sqrt)
La función iterrows () es un tipo de generador simple que generará una nueva matriz de iteraciones, una para cada columna. Esto es genial si necesita comprimir todas sus filas en un solo objeto iterable:
rowlist = df.iterrows()
Ahora podríamos iterar sobre este generador:

Perfiles
Es difícil mencionar el análisis de datos de Pandas sin hablar de la elaboración de perfiles de Pandas.
Aunque requerirá otra biblioteca, es sin duda una de las mejores herramientas que los científicos de datos de Pythonic tienen a su disposición para obtener una descripción general rápida de los datos con una sola llamada de función. Puede verificarlo aquí:
Para usarlo, simplemente llame.
df.profile_report()
¡Esto proporcionará un examen completo de sus datos en un práctico folleto HTML que es fácil de digerir y perfectamente compatible con IPython!
Serie
El tipo de serie Pandas, aunque probablemente no sea tan integral para Pandas como el marco de datos, ciertamente tiene su importancia. A diferencia de las características de una lista normal, la serie Pandas viene con una gran cantidad de opciones diferentes que simplemente no se admiten en ningún otro lugar.
Por lo general, incluyen las herramientas típicas de calidad de vida que la mayoría de los científicos de datos esperan de trabajar en Python.
La función isin devolverá una máscara condicional que devolverá verdadero si una determinada observación de la serie está dentro de la lista de valores a la que se llama. Por ejemplo, podríamos crear una máscara para determinar si cada valor en nuestra columna: PrecipType es "lluvia" o no:
df["Precip Type"].isin(["rain"])

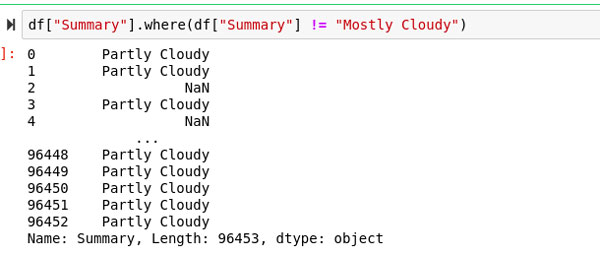
Donde aplicará una condición a una serie dada y devolverá valores que cumplan con dicha condición. La función where tiene un nombre bastante directo según el equivalente SQL del propósito de esta función.
df["Summary"].where(df["Summary"] != "Mostly Cloudy")
Si no está familiarizado con iloc y loc, entonces probablemente debería comenzar a practicar, ¡porque estos dos son muy importantes! La regla de oro es que loc is used for labelsy iloc is used for integer-based indexing. En primer lugar, intentemos usar iloc en un tipo de serie y veamos qué obtenemos a cambio.
df["Precip Type"].iloc[2]

Estamos obteniendo "lluvia" como retorno aquí porque es el segundo índice en nuestra columna "Tipo de precipitación". Echemos otro vistazo al encabezado del marco de datos:

Alternativamente, podríamos usar loc en lugar de iloc para obtener un valor basado en la etiqueta que contiene en el índice. Considere el siguiente marco de datos:
data = pd.DataFrame("Age": [25, 35,45], index = ["Corgi", "Maltese", "Pug"])

Ahora podríamos llamar a loc en cualquier índice dado y recibir el conjunto de observación completo con cada característica:
data.loc["Corgi"]
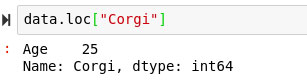
En realidad, no estoy seguro de qué tipo de datos devolverá, por lo que también tengo curiosidad por comprobar de qué tipo es:

La función de rango se puede usar para proporcionar rangos numéricos a los valores, generalmente basados en su posición relativa a los valores mínimo y máximo en los datos.
Esto es útil por una serie de razones diferentes, pero se puede ver una gran aplicación de rangos en la prueba Wilcox Rank Sum, una prueba estadística que usa rangos para devolver la probabilidad.
df["Humidity"].rank()
![]()
Aunque hay muchos paquetes geniales en otros lenguajes que buscan realizar tareas similares, la mayoría de ellos me hacen perder las formas brillantes en que Pandas aborda problemas complicados.
Usando estas funciones, está casi garantizado que la mayoría de los problemas que puede encontrar un científico se puedan resolver.
Aunque Pandas es una biblioteca muy detallada, es genial estar siempre al tanto de las funciones geniales que pueden acelerar tu trabajo y llevarte a las cosas divertidas un poco antes.
Diviértete aprendiendo. Gracias por leer este post.






Añadir comentario