
Muy buenas, soy Miguel y hoy les traigo un post.
“SQL es una herramienta importante para cualquier científico de datos”, es mi entrada para la subestimación del año.
Como jockeys de la información, los científicos de datos utilizan SQL para consultar los datos que necesitarán para el análisis de las bases de datos establecidas. Dependiendo de las demandas de su puesto como científico de datos, es posible que incluso se le pida que ayude a construir una base de datos a partir de las fuentes de datos de su empleador, para lo cual SQL también es útil. Ser capaz de seleccionar la información que es pertinente al proyecto actual al inicio del proyecto es una eficiencia simple de aprender y ahorrará tiempo en el proyecto.
Al principio de mi viaje para aprender ciencia de datos, quería poder aprovechar Python con datos extraídos de una base de datos de Microsoft SQL Server y, después de aprender sobre el uso de sqlite3 en Python, descubrí cómo conectarme directamente para optimizar mi trabajo. extraer datos directamente en un cuaderno Jupyter. ¡Continúe leyendo si desea aprender cómo hacer esto!
Si no está familiarizado con el módulo Python sqlite3, es un módulo que proporciona una interfaz SQL para bases de datos SQLite. Hay mucha literatura sobre cómo usar SQLite en Python, pero encontré que esta publicación de blog es la más servicial.
Si no está construyendo su propia base de datos con SQLite y desea conectarse a una base de datos que ya está establecida, puede usar el módulo pyodbc. Pyodbc permite que un usuario se conecte con una base de datos del Sistema de gestión de base de datos (DBMS) utilizando el controlador ODBC. Una instalación rápida de pip debería ponerlo en funcionamiento, pero puede encontrar documentos de instalación completos aquí. Una vez que haya instalado pyodbc (se puede encontrar la documentación completa para pyodbc aquí) deberá instalar el controlador ODBC para el DBMS al que desea conectarse; una búsqueda rápida en Google debería dirigirlo a la descarga adecuada.
Ahora analizaré un ejemplo de cómo escribir una conexión a una base de datos de Microsoft SQL Server y extraer una consulta.
Al igual que en el módulo sqlite3, para conectarse a la base de datos necesitará establecer un objeto de conexión para representar la base de datos. Pyodbc pasa una cadena de conexión ODBC al administrador de controladores local, que a su vez llama al controlador de base de datos relevante, que a su vez llama a la base de datos para solicitar la conexión.

Para Microsoft SQL Server 2017, hay una serie de cadenas de conexión para seleccionar dependiendo de si se está conectando a una base de datos con seguridad estándar, si se está conectando a una conexión de confianza o si desea habilitar varios conjuntos de resultados activos (MARS). Usé lo siguiente para conectarme a una conexión confiable:
‘Driver = ODBC Driver 13 para SQL Server; Server = MyServerAddress; Base de datos = myDataBase; Trusted_Connection = sí; ‘
Encuentre otras cadenas de conexión configuradas para numerosos DBMS aquí.
Una vez que haya establecido su conexión, hay dos métodos que puede utilizar para extraer una consulta. La primera forma es establecer un objeto cursor. Un objeto de cursor permite recorrer las filas de un conjunto de resultados extraído de una base de datos. Un cursor le permitirá procesar filas individuales en el conjunto administrando el contexto de las operaciones de recuperación. Si se llama al método .cursor () sin argumentos de índice y clase especificados, crea un cursor de estilo DB-API que puede usar numerosas operaciones, como find (), execute (), fetchone () y fetchmany ().

Como puede ver en el código anterior, puede seleccionar un subconjunto de la consulta para extraer: fetchone () extraería solo una fila, fetchall () selecciona todas las filas y fetchmany (x) extrae las siguientes x filas restantes y devuelve ellos como una lista de tuplas.
El segundo método es usar la función pandas.read_sql, que es una función contenedora para las llamadas read_sql_table y read_sql_query que se muestran arriba. Esta función permite al usuario ingresar una consulta escrita o un nombre de tabla de base de datos y la cadena de conexión y alimentar el resultado directamente en un marco de datos.
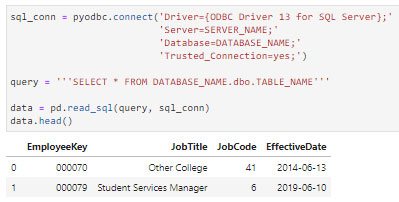
¡Y así tendrá sus datos listos para usar en un marco de datos!
Algunos consejos útiles para tener en cuenta:
- Las consultas se pueden escribir en Python exactamente como lo harían en un DBMS.
- Convierta tipos de datos directamente en la consulta para reducir las operaciones de conversión.
- Al escribir consultas largas, envuelva la cadena de consulta entre comillas triples; esto permite que las cadenas abarquen varias líneas, por lo que puede sangrar para mejorar la legibilidad.
Esperamos que esto le ayude a optimizar el suministro de datos.





Añadir comentario