
Hola, les saluda Miguel y para hoy les traigo este tutorial.
Índice
Un texto estándar rápido para ayudar a construir API rápidas usando Flask y FaunaDB.
Con el auge de la tecnología sin servidor, hacer que los servicios web sea más fácil. Las aplicaciones sin servidor cambian la antigua arquitectura monolítica de las aplicaciones y promueven más una solución de microservicio para problemas técnicos.
Con la ventaja del ajuste de escala automático y las implementaciones multirregionales, no es de extrañar que las aplicaciones sin servidor estén aumentando rápidamente en los últimos años. El costo de la tecnología sin servidor también ha redefinido la forma en que creamos software, ya que ahora es por solicitud en lugar de un servicio basado en el tiempo.
Aún mejor, la tecnología sin servidor también permite que los pequeños servicios sean totalmente gratuitos. Solo se necesita pagar después de un millón de solicitudes aproximadamente. Un ejemplo sería el plan de consumo de Azure Function .
¿Qué tiene que ver Serverless con este tutorial?
La razón principal por la que se menciona serve r less aquí es porque FaunaDB es una base de datos NoSQL que está hecha para servidores sin servidor. El precio de esta base de datos se basa en la solicitud, precisamente lo que necesitan las aplicaciones sin servidor.
El uso de un servicio como FaunaDB puede ayudar a reducir los costos tanto que las capacidades de alojamiento de la aplicación serían prácticamente gratuitas. Excluyendo los costos de desarrollo, por supuesto. Por lo tanto, el uso de una base de datos facturada mensualmente para aplicaciones sin servidor mata el punto.
Un ejemplo de pila libre sería una combinación de Netlify, Netlify Functions y FaunaDB. Aunque solo sería ‘gratis’ para una cierta cantidad de solicitudes. A menos que esté creando una aplicación que obtenga miles de usuarios el día cero de la implementación, no creo que sea un gran problema.
En mi opinión, el uso de una base de datos facturada mensualmente para aplicaciones sin servidor mata el punto.
Flask, por otro lado, es un microframework escrito en Python. Es un marco minimalista sin capas de abstracción de base de datos, validación de formularios o cualquier otra función particular proporcionada por otros marcos.
Flask es compatible con servidores grandes. Puede crear una aplicación Flask sin servidor con AWS Lambda. Aquí hay una guía oficial de Flask serverless de serverless.com .
Empezando
Configuración de Python y Pip
En primer lugar, instale Python y Pip. No voy a enumerar todas las formas posibles de instalarlo, para los usuarios de Windows pueden obtener el instalador aquí . En cuanto a los usuarios de Linux, si está utilizando una distribución basada en Debian / Ubuntu, abra su símbolo del sistema e instale Python y Pip así:
sudo apt update sudo apt install python3 python3-pip
Para comprobar si la instalación es correcta, intente ejecutar estos comandos:
python --version pip --version
Los números de versión se mostrarían entonces para los comandos correspondientes.
Instalación de dependencias
Una vez completada la configuración del entorno, el siguiente paso sería instalar Flask. El proceso de instalación es simple, solo ingrese:
pip install Flask
Luego, instale el controlador de Python para FaunaDB:
pip install faunadb
¡Genial! ¡Estás listo!
Hacer una aplicación de lista de tareas pendientes
Ahora vamos a crear una aplicación de ejemplo con la madre de todas las ideas de aplicaciones, la aplicación de lista de tareas pendientes.
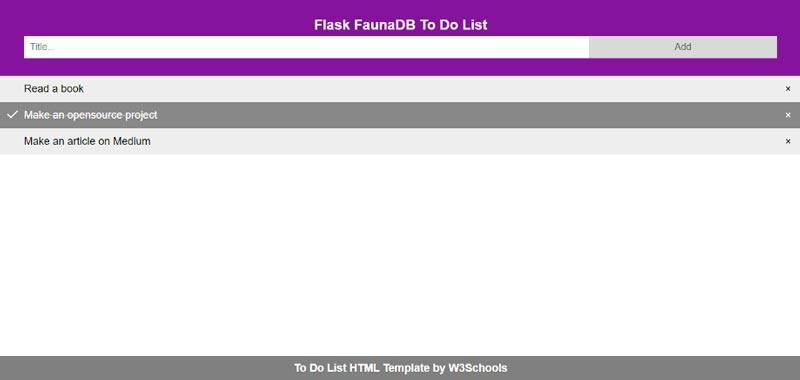
Plantilla de lista de tareas pendientes
Para este ejemplo, debido a que nos centraremos principalmente en cómo hacer la API, usaremos la plantilla W3School para la interfaz de la aplicación de lista de tareas pendientes.
Estructura básica del proyecto
Nuestro proyecto sería una implementación de un patrón de ayuda. Un esquema simple de nuestro proyecto sería así:
-/
|--app.py
|
|--services
|--todo_service.py
|--helpers
|--todo_helper.py
|--entities
|--faunadb_entity.py
Índices FaunaDB
Espera, ¿Qué son los índices?
Los índices son la forma de hacer declaraciones de «dónde» en FaunaDB. Le permite obtener documentos específicos basados en los valores de campo.
Para crear un nuevo índice, simplemente vaya a la sección Índices de su base de datos y haga clic en Nuevo índice.

Al crear un índice, elija la colección con la que le gustaría interactuar. Luego, defina el nombre del campo por el que desea buscar. Por último, defina el nombre de su índice y asegúrese de que sea único y legible.
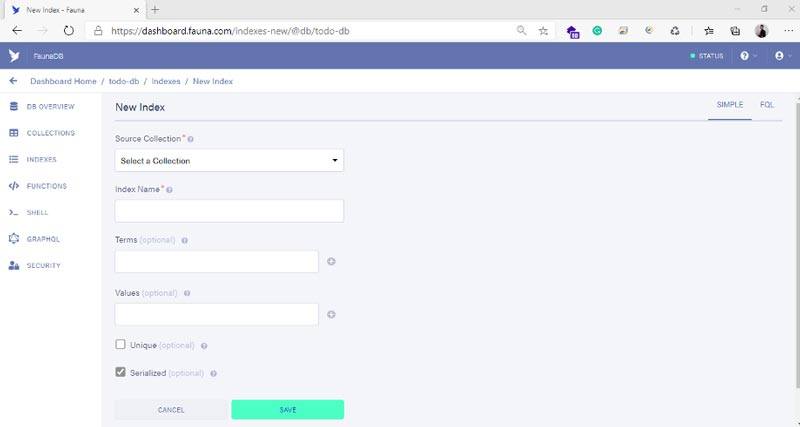
Por ejemplo, creemos un índice donde podamos obtener todos los datos de una colección existente.

Oh, ¿Qué tal un índice para obtener todos por correo electrónico del usuario? Fácil.
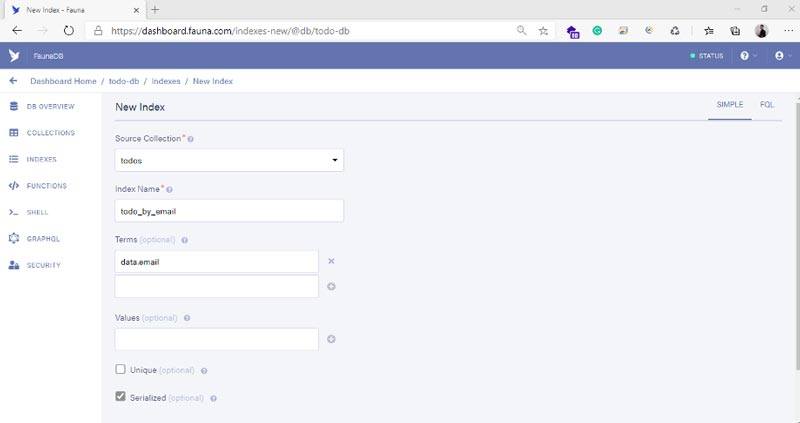
Si desea que los términos sean únicos, marque la casilla de verificación Único para agregar una restricción.

Para agregar restricciones a una colección determinada, debe crear índices con términos que contengan campos únicos.
Para ayudarlo a comprender mejor, aquí hay un artículo oficial de Fauna para ayudarlo a comprender los índices.
Hagamos la API
Hacer el archivo de inicio de Flask
Primero, escriba un archivo de Python que ejecute Flask.
Aplicación Basic Flask
Escriba el script de entidad FaunaDB
A continuación, antes de comenzar a escribir nuestros servicios y ayudantes, primero debemos definir un archivo de entidad para conectarnos a FaunaDB.
Esto se usa para obtener un documento de FaunaDB por índice. La función de obtención no devuelve varios documentos y solo puede devolver un solo documento a la vez.
Para obtener varios documentos, necesitamos usar una función de mapa para devolver varios datos por un índice determinado.
La función lambda pasará los datos necesarios en el índice mientras paginate buscará los documentos específicos en la colección, luego la función de mapa devolverá todos los documentos coincidentes como una lista.
Obtener documento por Id. De referencia es la única función que no usa un índice en lugar de utilizar el Id. De referencia del documento.
El código para crear, actualizar y eliminar documentos sería similar. Debido a que FaunaDB es una base de datos NoSQL, la estructura de los datos no importa siempre que se pase como un diccionario. La actualización y eliminación de documentos también necesitaría un parámetro de Id de referencia adicional, similar a la función Obtener documento por Id de referencia.
Haz el ayudante de tareas pendientes
Después de escribir el script de la entidad FaunaDB, escriba las funciones auxiliares para la colección. Las funciones auxiliares deben ser pequeñas funciones precisas que hagan exactamente una cosa.
Hacer el servicio To-Do
Cuando todos los ayudantes estén listos, escriba el archivo de servicio que se utilizará como puntos finales. Todas las solicitudes se analizan en el nivel de servicio, por lo que el nivel de ayuda solo recibirá los datos procesados.
Adjuntar las rutas a los puntos finales del servicio
Finalmente, cuando se establezcan los puntos finales, agregue los puntos finales al archivo app.py
¡Listo! No olvide probar las API con Postman antes de la implementación.
Resumen
En este tutorial, ha aprendido a crear una API usando Flask y FaunaDB.
Para recapitular, hemos hecho:
- Puntos finales de API usando Flask.
- Índices en FaunaDB.
- Un ayudante de entidad simple para FaunaDB.
- Un texto estándar legible para futuros proyectos de API.
Ahora tiene una configuración estándar rápida para usar cuando desee crear una aplicación rápida en cuestión de horas. Los planes futuros incluyen agregar una implementación de Swagger al modelo actual.
Espero que este sea un gran comienzo para ti, ¡que tengas un buen día!






Añadir comentario