
Hola, soy Miguel y esta vez les traigo un post.
Hay varias formas de hacer que los servicios se comuniquen, que generalmente implican una capa de transporte.
Nuestras aplicaciones a menudo dependen de él para proporcionar varias abstracciones y funciones, como equilibrio de carga, reintentos y alta disponibilidad.
Sin embargo, cuando se ejecuta un servicio en producción, obtenemos más errores relacionados con la red de los que nos gustaría.
Esta publicación tiene la intención de mostrar cómo mitigamos estos errores al usar gRPC para la comunicación de servicio a servicio.
Índice
¿Por qué gRPC?
En 2016, casi todos los servicios de InLoco utilizaban la pila HTTP1.1 / JSON para la comunicación. Funcionó bien durante mucho tiempo, pero, a medida que la empresa crecía, algunos servicios de alto tráfico comenzaron a requerir una forma más eficiente de comunicarse con los clientes internos.
La documentación de las API JSON también era engorrosa de mantener, ya que no estaban vinculadas al código en sí, lo que significa que alguien podría implementar código que cambia la API sin cambiar la documentación de forma adecuada.
En la búsqueda de una buena alternativa, buscamos en gRPC, que resuelve los problemas de rendimiento y definición de esquema descritos anteriormente, con las siguientes características:
- La superficie de la API se define directamente en los archivos Protobuf, donde cada método describe sus propios tipos de solicitud / respuesta
- Genere automáticamente código de cliente y servidor en muchos idiomas
- Utiliza
HTTP / 2en combinación con Protobuf, que son ambos protocolos binarios, lo que da como resultado una carga útil de solicitud / respuesta más compacta -
HTTP / 2también usa conexiones persistentes, eliminando la necesidad de crear / cerrar conexiones constantemente, como lo haceHTTP / 1.1.
Pero ejecutar servicios de gRPC también nos proporcionó algunos desafíos, principalmente debido al hecho de que HTTP / 2 usa conexiones persistentes.
Desafíos de gRPC en producción
Somos grandes usuarios de Kubernetes y, como tal, nuestros servicios de gRPC se ejecutan en clústeres de Kubernetes, en Amazon EKS.
Uno de los desafíos que enfrentamos fue asegurar el equilibrio de carga en nuestros servidores.
Como la cantidad de servidores cambia dinámicamente debido al ajuste de escala automático, los clientes deben poder hacer uso de los nuevos servidores y eliminar las conexiones a los que ya no están disponibles.
Mientras se asegura de que la cantidad de solicitudes esté bien equilibrada entre ellos siguiendo alguna política de equilibrio de carga.
Balanceo de carga
Hay algunas soluciones para este problema, como se indica en el blog de gRPC, incluido el equilibrio de carga de proxy y el equilibrio de carga del lado del cliente.
En las siguientes secciones, explicamos los enfoques que implementamos, en orden cronológico.
La primera forma en que implementamos fue usando un balanceador de carga proxy, a saber Linkerd 1.x, como muestra la Figura 1.
La carga de cliente a proxy aún estaba desequilibrada, lo que significa que algunas instancias de Linkerd manejaban una mayor cantidad de solicitudes que otras.
Posteriormente, el tráfico desequilibrado en el enlace de cliente a proxy resultó ser problemático. Las instancias de proxy sobrecargadas podrían agregar demasiada latencia, o incluso quedarse sin memoria a veces, volviéndose cada vez más difíciles de administrar.
Además, se demostró que esta solución agrega una sobrecarga considerable (ya que requiere un salto de red adicional), y también consume una cantidad considerable de recursos en nuestro clúster de Kubernetes.
Debido a que implementamos Linkerd como un Daemonset, lo que significa que un pod de Linkerd se ejecuta en cada nodo trabajador del clúster.
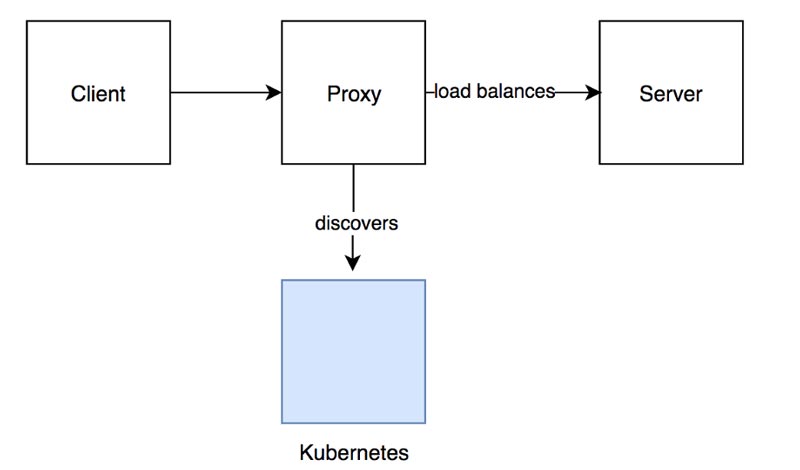
Intentando abordar los problemas con el primer enfoque, intentamos eliminar la capa de proxy, manejando la responsabilidad del equilibrio de carga en el código del cliente, que es nuestro propietario.
naming.NewDNSResolverWithFreq(time.Duration) en combinación con los servicios headless de Kubernetes (para manejar el descubrimiento de pods de servidor).
En esta solución, los clientes actualizan el grupo de hosts a los que pueden conectarse sondeando el DNS del servicio de destino cada pocos segundos.
Esto provocó que los clientes se conectaran directamente a los pods del servidor, lo que redujo nuestra latencia en comparación con el enfoque del equilibrador de carga de proxy. El siguiente diagrama muestra los componentes involucrados en este enfoque.
Sin embargo, el descubrimiento de servicios dinámicos mediante DNS se está obsoleto por la implementación de Go gRPC, a favor de otros protocolos como xDS. No solo eso, en otros idiomas, nunca se había implementado en primer lugar.
Aprendimos que, aunque este enfoque nos ofrece una comunicación estable y de alto rendimiento, confiar en implementaciones en el código del cliente puede ser frágil y difícil de administrar debido a la diversidad de implementaciones de gRPC.
Este punto es válido para otras funciones, como la limitación de velocidad y la autorización.
Después de probar estos diferentes enfoques, identificamos que necesitábamos una forma genérica, de baja sobrecarga e independiente del lenguaje para permitir el descubrimiento de servicios y el equilibrio de carga.
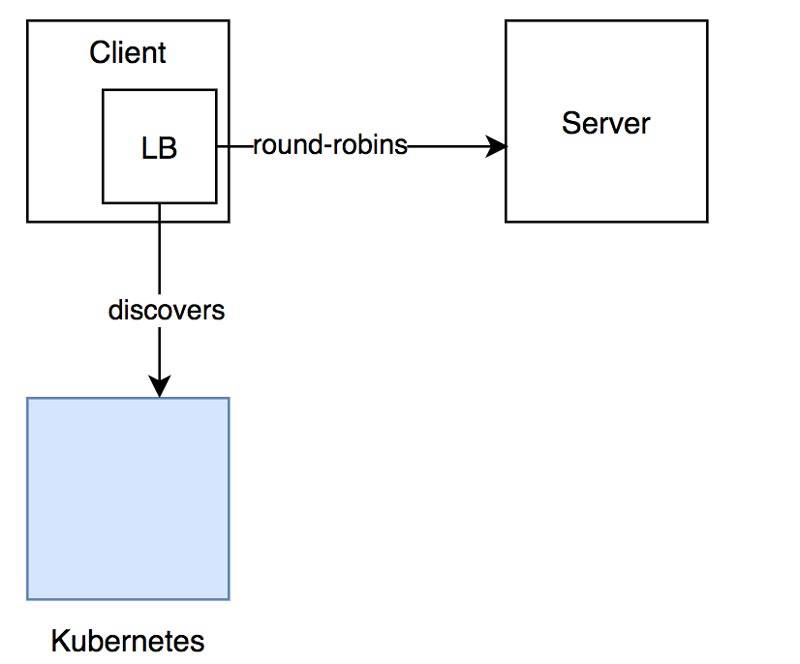
Después de investigar un poco sobre el tema, decidimos utilizar el patrón de sidecar, agregando otro contenedor al pod de cliente, que maneja el descubrimiento de servicios, balanceo de carga y proporciona cierta observabilidad a nuestras conexiones.
Elegimos usar Envoy, por su alto rendimiento y simplicidad de implementación.

En este enfoque, los contenedores del cliente se conectan al sidecar Envoy, que mantiene las conexiones con el servicio de destino.
Usando este enfoque, obtuvimos lo que estábamos buscando:
- Baja latencia, ya que la sobrecarga de Envoy es mínima en comparación con
Linkerd 1.x. - Sin código adicional en los clientes.
- Observabilidad, ya que Envoy exporta métricas en formato
Prometheus. - Capacidad para enriquecer la capa de red, ya que Envoy admite funciones como autorización y limitación de velocidad.
Descubrimiento de servicios y apagado ordenado
Con el equilibrio de carga adecuado configurado, todavía necesitamos una forma de que Envoy descubra nuevos objetivos y actualice su grupo de hosts.
Integrar el descubrimiento de servicios DNS en Kubernetes es bastante sencillo, ya que usamos externos-dns, pudiendo especificar el nombre de host y DNS TTL directamente en nuestro servicio de Kubernetes, de la siguiente manera:
Una complejidad oculta del uso de DNS como nuestro mecanismo de descubrimiento de servicios es que lleva algún tiempo propagarse.
gRPC cierto margen de maniobra para actualizar sus listas de hosts antes de que un backend que termina realmente deje de recibir conexiones.Con DNS, el flujo de cierre elegante es un poco más complicado, ya que los registros de DNS tienen un TTL asociado, lo que significa que Envoy almacena en caché los hosts durante este período.
El siguiente diagrama muestra un flujo básico que termina con una solicitud fallida:

DNS.En este escenario, la segunda solicitud del cliente falla, ya que el módulo del servidor ya no estaba disponible, mientras que la caché del Envoy aún tenía su IP.
Para resolver este problema, debemos observar cómo Kubernetes maneja la terminación de pod, que se describe en detalle aquí.
Consiste en 2 pasos que se ejecutan al mismo tiempo:
El pod se elimina de los puntos finales del servicio de Kubernetes (en nuestro caso, esto también hace que external-dns elimine la IP del pod de la lista de registros DNS) y al contenedor se le envía una señal TERM. , iniciando el elegante proceso de apagado.
Para resolver el problema del host de terminación, usamos los ganchos previos a la parada de Kubernetes para evitar que se envíe una señal TERM inmediata al pod, de la siguiente manera:
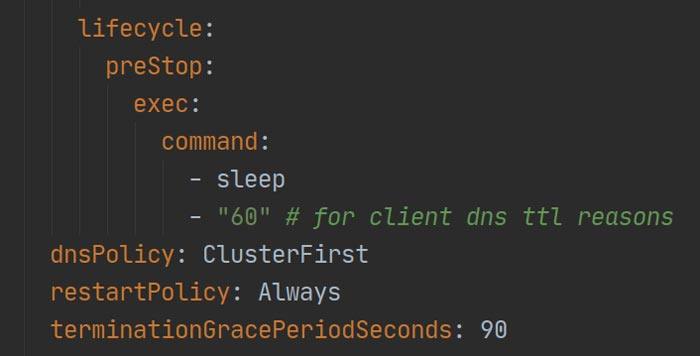
preStop.Con el gancho preStop configurado, nuestro flujo ahora tiene el siguiente aspecto:
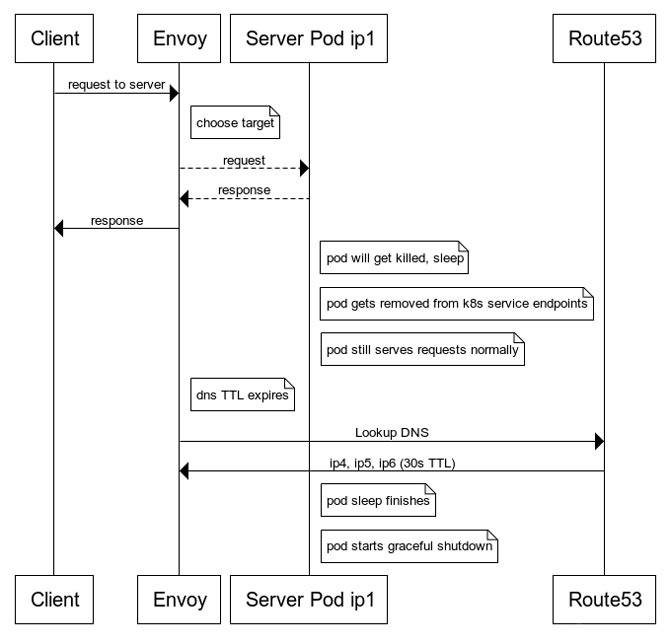
Con esta solución, damos suficiente tiempo para que caduque la caché de DNS de Envoy y realizamos una nueva búsqueda de DNS, que ya no incluye la IP del módulo inactivo.
Mejoras futuras
Si bien el uso de Envoy nos trajo muchas mejoras de rendimiento y simplicidad general, el descubrimiento del servicio DNS aún no es ideal.
No es tan robusto, ya que se basa en el sondeo, donde los clientes son responsables de actualizar el grupo de hosts cuando expira el TTL.
Una forma más robusta es utilizar Envoy's EDS, que es más flexible, agrega capacidades como implementaciones de canary y estrategias de equilibrio de carga más sofisticadas, pero aún necesitamos algo de tiempo para evaluar este enfoque y validarlo en un entorno de producción.
Gracias por leer este artículo.






Añadir comentario