
Muy buenas, me llamo Miguel y aquí les traigo este artículo.
Índice
En Python con un conjunto de datos del mundo real
En el contexto de Aprendizaje Supervisado (Clasificación) , Naive Bayes o más bien Aprendizaje Bayesiano actúa como un estándar de oro para evaluar otros algoritmos de aprendizaje además de actuar como una poderosa técnica de modelado probabilístico.
En esta publicación, vamos a discutir el funcionamiento del clasificador Naive Bayes implementacionalmente con Python aplicándolo a un conjunto de datos del mundo real.
La publicación se divide de manera más amplia en las siguientes partes:
- Preprocesamiento de datos
- Entrenando el modelo
- Predecir los resultados
- Comprobación del rendimiento del modelo
Las partes anteriores se pueden dividir de la siguiente manera:
→ Preprocesamiento de datos
- Importando las bibliotecas
- Importando el conjunto de datos
- Dividir el conjunto de datos en el conjunto de entrenamiento y el conjunto de pruebas
- Escala de características
→ Entrenando el modelo
- Entrenamiento del modelo Naive Bayes en el set de entrenamiento
→ Predecir los resultados
- Predecir los resultados del conjunto de prueba
→ Comprobación del rendimiento del modelo
- Haciendo la Matriz de Confusión
→ Visualización
- Visualizando la Matriz de Confusión
Antes de empezar a profundizar en el código en sí, tenemos que hablar del conjunto de datos en sí. Para esta implementación, vamos a utilizar el conjunto de datos de texto de 20 grupos de noticias. Este conjunto de datos está disponible públicamente con el propósito de que la gente pueda aprender y perfeccionar sus habilidades de aprendizaje automático.
Vamos a utilizar scikit-learn (sklearn) como la biblioteca de aprendizaje automático y el repositorio del conjunto de datos en sí. Esto es lo que le dice el sitio web de sklearn sobre el conjunto de datos.
El conjunto de datos de 20 grupos de noticias comprende alrededor de 18000 publicaciones de grupos de noticias sobre 20 temas divididos en dos subconjuntos: uno para capacitación (o desarrollo) y el otro para pruebas (o para evaluación de desempeño). La división entre el tren y el conjunto de prueba se basa en mensajes publicados antes y después de una fecha específica.
Características del conjunto de datos

Nota: Dado que los datos sin procesar son texto en lenguaje natural, no podemos trabajar directamente con ellos. Necesitamos transformar los datos en números antes de que podamos empezar a trabajar en ellos. Hay varias formas de hacerlo, a saber:
Depende del diseñador de la solución y del problema en sí elegir el Vectorizador. Para el propósito de esta publicación, voy a usar CountVectorizer. He proporcionado el enlace a la documentación de sklearn para todos los vectorizadores. Ciertamente puede tener una vista detallada allí y también a través de Internet.
Ahora que hemos hablado un poco sobre el conjunto de datos, empecemos con el código en sí mismo, paso a paso.
→ Preprocesamiento de datos
Importando las bibliotecas
from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import GaussianNB from sklearn.metrics import confusion_matrix, plot_confusion_matrix import matplotlib.pyplot as plt
Las bibliotecas mencionadas anteriormente se utilizan / requieren (explicadas en orden) de la siguiente manera:
a) Importar el conjunto de datos desde sklearn.
b) Importar CountVectorizer para convertir texto en lenguaje natural sin procesar en números comprensibles por máquina
c) Importando el clasificador Naive Bayes, en este caso estamos usando Gaussian Naive Bayes
d) Importar los métodos de la matriz de confusión para comprobar el rendimiento del modelo y visualizarlo.
e) Para visualización de Matriz de confusión
2 y 3. Importación del conjunto de datos y división del conjunto de datos en el conjunto de entrenamiento y el conjunto de prueba
data_train = fetch_20newsgroups(subset='train', categories=None,
remove=('headers', 'footers',
'quotes'))
data_test = fetch_20newsgroups(subset='test', categories=None,
remove=('headers', 'footers',
'quotes'))
X_train = data_train.data
y_train = data_train.target
X_test = data_test.data
y_test = data_test.target
data_train contiene el conjunto de entrenamiento de los propios datos. Los parámetros pasados fetch_20newsgroups puede entenderse como:
1) subconjunto: para definir el conjunto de entrenamiento o prueba
2) categorías: el conjunto de datos contiene 20 categorías o etiquetas de clase. El subconjunto del conjunto de datos se puede utilizar proporcionando una lista de categorías en el parámetro de las siguientes:
from pprint import pprint pprint(list(newsgroups_train.target_names))
El resultado es:
[‘alt.atheism’,
‘comp.graphics’,
‘comp.os.ms-windows.misc’,
‘comp.sys.ibm.pc.hardware’,
‘comp.sys.mac.hardware’,
‘comp.windows.x’,
‘misc.forsale’,
‘rec.autos’,
‘rec.motorcycles’,
‘rec.sport.baseball’,
‘rec.sport.hockey’,
‘sci.crypt’,
‘sci.electronics’,
‘sci.med’,
‘sci.space’,
‘soc.religion.christian’,
‘talk.politics.guns’,
‘talk.politics.mideast’,
‘talk.politics.misc’,
‘talk.religion.misc’]
3) eliminar: el texto del conjunto de datos contiene encabezados, pies de página y comillas, pero queremos aplicar el modelo en el cuerpo de los datos.
Las variables independientes y dependientes se pueden separar llamando .data y .target sobre el data_train y data_test para obtener datos de prueba y entrenamiento bifurcados.

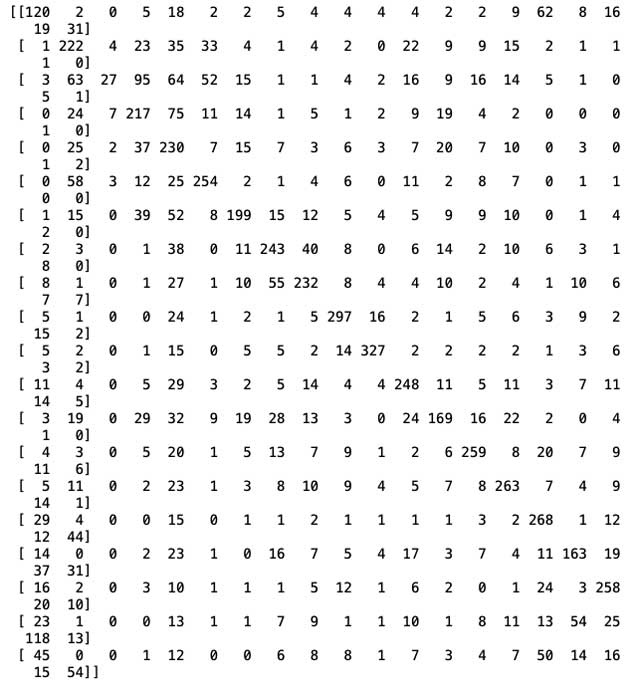
Los valores de la matriz representan el índice de la lista de categorías mencionada anteriormente.

4) Escala de funciones
vectorizer = CountVectorizer() X_train = vectorizer.fit_transform(X_train) X_test = vectorizer.transform(X_test)
Hacer un objeto de la clase CountVectorizer seguido de ajustar el objeto vectorizador en ambos X_trainy X_testdatos.
→ Entrenando el modelo
- Entrenamiento del modelo Naive Bayes en el set de entrenamiento
y_pred = classifier.predict(X_test.toarray())
Hacer un objeto de la clase GaussianNB seguido de ajustar el objeto clasificador en X_trainy y_train data. Aquí .toarray()con X_trainse usa para convertir una matriz dispersa en una matriz densa.
→ Predecir los resultados
- Predecir los resultados del conjunto de prueba
y_pred = classifier.predict(X_test.toarray())
Llamar al .predictmétodo en el objeto clasificador y pasar el X_testpara predecir los resultados del modelo entrenado en datos no vistos anteriormente. Aquí .toarray()con X_testse usa para convertir una matriz dispersa en una matriz densa.
→ Comprobación del rendimiento del modelo
- Haciendo la Matriz de Confusión
cm = confusion_matrix(y_test, y_pred) print(cm)
→ Visualización
- Visualizando la Matriz de Confusión
plot_confusion_matrix(classifier, X_test.toarray(), y_test, display_labels=['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware'], cmap=plt.cm.Blues)
Para fines de visualización, estoy limitando el número de categorías a 4 para que sea visible correctamente.

Ahora que todo el proceso de un modelo de aprendizaje automático está terminado, espero haber podido compartir algunos conocimientos. Esta es una canalización de aprendizaje automático muy básica, pero es bastante importante en términos de construir una base cuando desea construir modelos de aprendizaje automático mejores y más complejos. Espero traer modelos más dinámicos y complejos en el futuro, así que estad atentos.
Aquí hay un enlace al cuaderno completo de jupyter.
Gracias por leer. Comparta si siente que puede ayudar a otros.






Añadir comentario