
Hola, soy Luis y hoy les traigo otro nuevo post.
La Universidad de Michigan ofrece una especialización en Python en Coursera llamada Python for Everybody. Charles Severance, que es gracioso e ingenioso, enseña estos cursos usando Python 3. El segundo curso, Estructuras de datos, explora el lenguaje Python aprendiendo a navegar por archivos de texto y tratando de manipular o recuperar datos para lograr el resultado deseado (cómo encontrar las palabra más comunes en el archivo).
Haciendo listas
El profesor compara las listas con piezas de equipaje con varios elementos en su interior, y cada pieza de equipaje tiene un nombre. Para crear una lista de marcadores, por ejemplo, los programadores pueden usar el siguiente código:
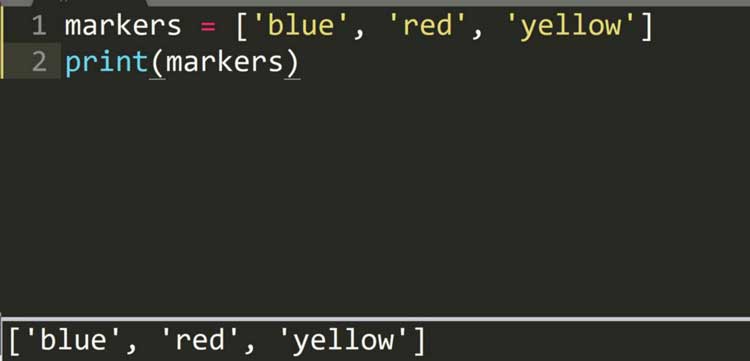
>>>markers = [‘blue’, ‘red’, ‘yellow’]
>>>print(markers[1])
red
Las listas son mutables. Por ejemplo, la cadena ‘rojo’ se puede cambiar a ‘verde’:
>>>markers[1] = ‘green’
>>>print(markers[1])
green
Para construir una lista de marcadores desde cero, los programadores pueden usar el siguiente código que crea una lista vacía y agrega elementos con el método append:
>>>markers = list()
>>>markers.append(‘brown’)
>>>markers.append(‘black’)
>>>print(markers)
[‘brown’, ‘black’]

Usando el método de división
Una vez que los programadores pueden crear sus propias listas, pueden comenzar a hacer algunas cosas interesantes al explorar archivos de texto. Antes de convertir un archivo de texto en una lista de cadenas, los principiantes pueden querer comenzar a dividir una cadena simple en una lista. Haga esto usando el método de división:
>>>words = ‘Here it is’
>>>wordparts = words.split()
>>>print(wordparts)
[‘Here’, ‘it’, ‘is’]
En el ejemplo anterior, el texto se divide según los espacios entre palabras. Los programadores también pueden dividir un texto según otras características. Digamos que nos gustaría dividir las palabras según el símbolo @ en una dirección de correo electrónico:
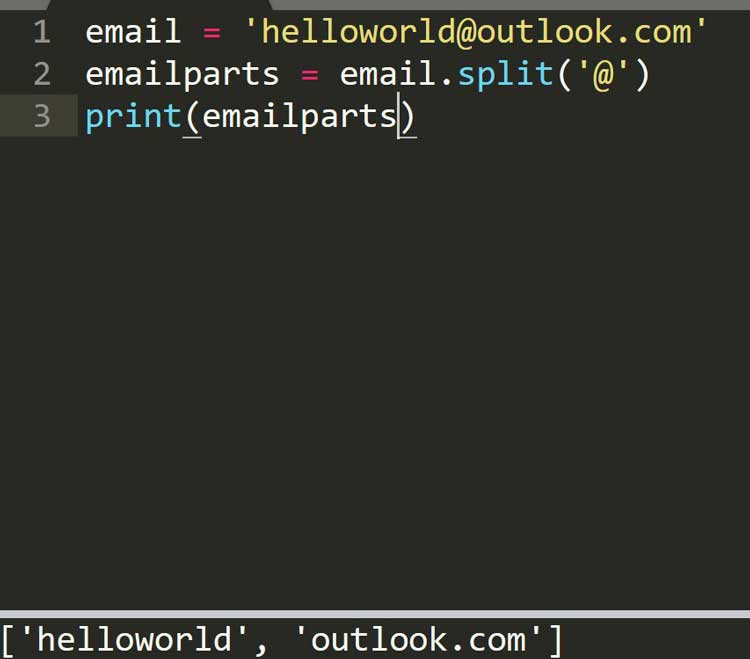
>>>email = ‘helloworld@outlook.com’
>>>emailparts = email.split(‘@’)
>>>print(emailparts)
[‘helloworld’, ‘outlook.com’]
Digamos que al programador le gustaría recorrer cada palabra en una lista e imprimirla.
>>>for parts in wordparts:
>>>>>>print(parts)
Here
it
is
Recuerde, la sangría en Python es importante. Sin una sangría en los lugares apropiados, recibirá un error de sangría.
Aplicación práctica
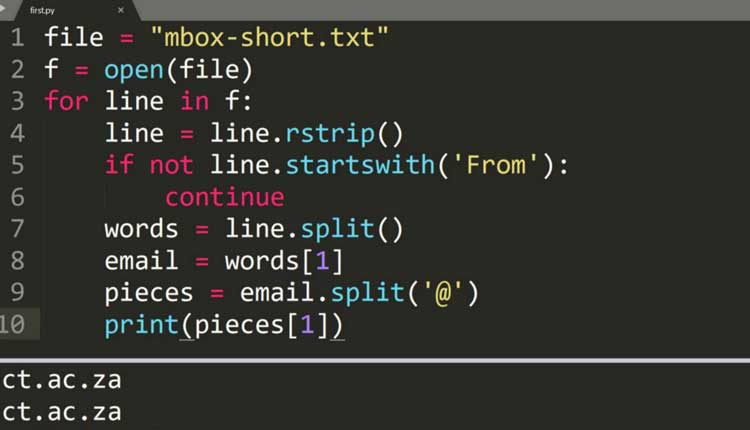
Ahora, ¿qué puedo hacer como programador con la información anterior? Bueno, digamos que tengo un texto largo con miles de correos electrónicos. Quizás me gustaría imprimir correos electrónicos con «gmail.com» y excluir todos los demás correos electrónicos que pertenecen a otros servicios de correo electrónico, como Yahoo Mail o Outlook. Supongamos que estos correos electrónicos en particular que estamos buscando comienzan en líneas que tienen «De» como su primera palabra, muy parecido a esto:
“From helloworld@gmail.com Fri Aug 12th”
Los programadores deben abrir primero el archivo de texto.
>>>fhand = open(‘atextfile.txt’)
Después de esto, necesitamos un bucle for para ver cada línea del texto:
>>>for line in fhand:
También necesitamos eliminar cualquier espacio en blanco al final de cada línea usando el método de la tira:
>>>>>>line = line.rstrip()
A continuación, saltamos cualquier línea que no comience con «De»:
>>>>>>if not line.startswith(‘From’):
>>>>>>>>>continue
Dividimos cada palabra en la oración que estamos buscando («De helloworld@gmail.com viernes 12 de agosto») en una lista:
>>>>>>words = line.split()
La lista debería verse así si la imprime:
[‘From’, ‘helloworld@gmail.com’, ‘Fri’, ‘Aug’, ‘12th’]
Ahora necesitamos tomar la dirección de correo electrónico. En la lista anterior tenemos cinco elementos, pero nuestra lista comienza con 0, así que, dado que este es el caso, necesitamos usar sub uno:
>>>>>>email = words[1]
¡Ahora tenemos nuestro correo electrónico!
>>>>>>print(email)
helloworld@gmail.com
¿Y si queremos hacer otra división? Esto se llama patrón de división doble.
>>>>>>emailparts = email.split(‘@’)
Si tuviera que imprimir partes de correo electrónico en este punto, tendría el siguiente resultado:
[‘helloworld’, ‘gmail.com’]
Ahora puede imprimir las partes individuales del correo electrónico:
>>>>>>print(emailparts[1])
gmail.com
Cuando todo está dicho y hecho, el patrón de doble división se ve así:
Gracias por leer.






Añadir comentario