
Muy buenas, les saluda Luis y esta vez les traigo otro tutorial.
Si se trata de la implementación del modelo ML, los servidores en la nube se vuelven imprescindibles … ¿verdad?
Las aplicaciones basadas en NLP generalmente requieren la implementación en servidores en la nube para un procesamiento fluido y un rendimiento perfecto. El intercambio de datos entre los dispositivos y servidores provoca un aumento de la latencia, mayores costos de Internet, restricción de la funcionalidad fuera de línea y, por último, la llamada pérdida de datos del usuario privado.
Debido a la potencia computacional limitada y al enorme tamaño de los modernos modelos complejos de PNL, la implementación del modelo únicamente en dispositivos móviles es un tema de investigación avanzada, tras lo cual Google introdujo un modelo basado en proyecciones llamado PRADO en septiembre de 2019 para realizar la clasificación de texto del dispositivo sin necesidad de un servidor en la nube. PRADO ha resultado ser útil en el desarrollo de configuraciones de IoT y aplicaciones móviles desde el tamaño del modelo cuantificado es ~ 200 KB y tiene solo varios miles de parámetros entrenables.
Índice
Enfoque utilizado en PRADO
Dado que la mayoría de los modelos de PNL de última generación utilizan tokenizadores previamente entrenados para la generación de incrustaciones de palabras de cada palabra en la oración, el modelo general se vuelve más complejo y computacionalmente costoso cuando nuestro objetivo es hacer un modelo para una tarea comparativamente fácil como Clasificación de texto. Si hubiera sido una tarea como la traducción automática, la generación de incrustaciones de palabras para cada palabra (incluidos artículos, pronombres y puntuación) habría valido la pena de no ser por los problemas como el modelado de temas y la clasificación de sentimientos, que dependen de pocas palabras importantes y menos frecuentes. de la oración, la conversión de la oración completa en vectores no es la mejor idea. En cambio, podemos enfocarnos en esas palabras importantes que llevan la semántica de la oración.
Aprovechando este pensamiento, PRADO se centra en un subconjunto de la oración para la vectorización y la clasificación final. Combina proyecciones entrenables con capas de atención y convolución para capturar dependencias de largo alcance. Este cambio en la estrategia y el enfoque permite a PRADO ofrecer resultados comparables a BERT y LSTM complejos, con solo 175.000 parámetros para entrenar.
La huella digital semántica es el proceso de representación de cada palabra del texto en formato binario. Esto se logra creando una matriz 2D donde un eje contiene los parches de texto analizados de todo el documento y el otro eje contiene una lista de palabras. La aparición de una palabra en cualquier número de parches se marca como «1» y el resto como «0».
Aquí hay una imagen que muestra la toma de huellas dactilares de «Perro» a partir de una determinada información.

Arquitectura y trabajo
En la capa de incrustación de proyección, cada palabra se imprime semánticamente usando vectores de tamaño de bits «2B» y luego un operador del proyector asigna cada palabra a un vector ternario, es decir, se representa usando -1,0,1. Estos vectores ternarios luego se pasan a través de una red neuronal entrenable para producir incrustaciones de palabras. Estas proyecciones entrenables no almacenan el vocabulario, sino que actualizan los pesos de proyección durante el tiempo de entrenamiento. ¡Esto les proporciona una ventaja sobre los tokenizadores existentes que almacenan todo el vocabulario!
En este método basado en proyecciones, el tamaño de incrustación final es mucho más pequeño que el formado por un gran vocabulario previamente entrenado.
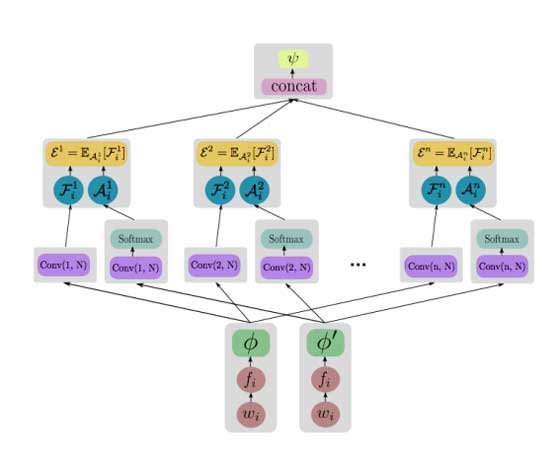
Operación de convolución y atención
- Red de características proyectadas «F» se usa para capturar las características o palabras de la oración que podría ser útil para la tarea de clasificación. Implica una operación de convolución en toda la oración.
- F = conv (e, n, N)
«e»es la secuencia de incrustaciones de palabras proyectadas recibidas desde la última capa
«n» es el tamaño del kernel
«N» es el tamaño de salida - Ahora, un La capa de atención se utiliza para ponderar la importancia de cada incrustación.
- W = conv (e, n, N)
Softmax de la salida ‘W’ se calcula para obtener una distribución probabilística. - E = softmax (W) .F
Esta operación genera una codificación de longitud fija de la oración con importantes características de decisión que tienen mayor peso. - La incrustación final «E» se pasa a través de una red neuronal entrenable para realizar la clasificación.
Notas finales
La versión cuantificada de 8 bits de PRADO funciona extremadamente bien y puede ser una opción de referencia para desarrollar aplicaciones móviles independientes basadas en PNL. El modelo también ofrece la opción de aprendizaje por transferencia y ha proporcionado un buen rendimiento con pocas compensaciones.
En septiembre de 2020, Google lanzó una versión actualizada de PRADO llamada pQRNN que ha adaptado la técnica de la capa de proyección para la generación de incrustaciones, pero tiene un enfoque diferente y mucho más avanzado en capas adicionales. Sería muy informativo para usted si también pasara por eso.
¡¡Gracias por leer!!
Recursos y documentos:





Añadir comentario