
Bienvenido, soy Luis y para hoy les traigo este artículo.
Una guía rápida para extraer las tablas de archivos PDF en Python usando la biblioteca Camelot
Índice
Instalación
Si está en Windows, asegúrese de instalar Ghostscrip desde aquí. Todavía puedes instalar camelot sin la instalación previa de Ghostscript. Pero nos encontraremos con errores al intentar usar camelot.
conda install -c conda-forge camelot-py
o
pip install "camelot-py[cv]"
o
git clone https://www.github.com/camelot-dev/camelot cd camelot pip install ".[cv]"
Uso
Primero importaremos camelot y luego proporcione la ruta del archivo pdf. los read_pdf viene con muchos parámetros que podemos explorar. El pdf de muestra utilizado para el siguiente ejemplo se encuentra aquí.
import camelot
tables = camelot.read_pdf('https://trade.indiabulls.com/pdf/NSE_Holidays_Equity.pdf')
Número de tablas: Imprime el número de tablas extraídas. El artículo anterior tiene 2 tablas.
tables.n >>> 2
Informe de análisis: Ejecute a continuación para obtener el informe de análisis de cada tabla extraída. Si estamos interesados en ver este informe para cada tabla, debemos recorrer todas las tablas.
print (tablas [0] .parsing_report) >>> {'precisión': 100.0, 'espacios en blanco': 0.0, 'orden': 1, 'página': 1} for i in range (tables.n): print (tables [i] .parsing_report) >>> {'precisión': 100.0, 'espacio en blanco': 0.0, 'orden': 1, 'página': 1} >>> {'precisión': 100.0, 'espacios en blanco': 0.0, 'orden': 2, 'página': 1}
Forma de la mesa: El siguiente código da la forma de todas las tablas extraídas. Aquí forma significa el número de filas y el número de columnas.
print(tables[0]) >>> <Table shape=(13, 4)>for i in range(tables.n): print(tables[i]) >>> <Table shape=(13, 4)> >>> <Table shape=(8, 4)>
Exportar las tablas: Podemos exportar todas las tablas a formato CSV, Excel, JSON, HTML y SQLite. Consulte el siguiente ejemplo para exportar tablas a formato CSV.
Del mismo modo, podemos usar to_excel, to_json, to_html y to_sqlite.
tables[0].to_csv(‘nse_holiday_list_table1.csv’) tables[1].to_csv(‘nse_holiday_list_table2.csv’)
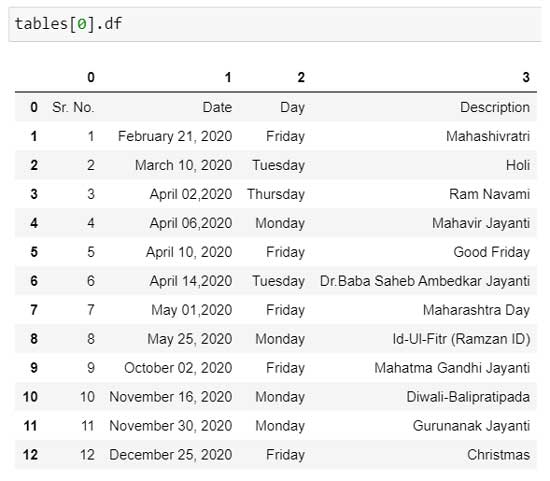
Convierta a pandas DataFrame: Podemos exportar todas las tablas a Pandas DataFrame. El código tables[0].df convertirá la tabla a DataFrame, pero como podemos ver en la siguiente captura de pantalla, el encabezado no se muestra correctamente.
Necesitamos corregir esto para que las tablas se muestren con los encabezados de DataFrame adecuados.
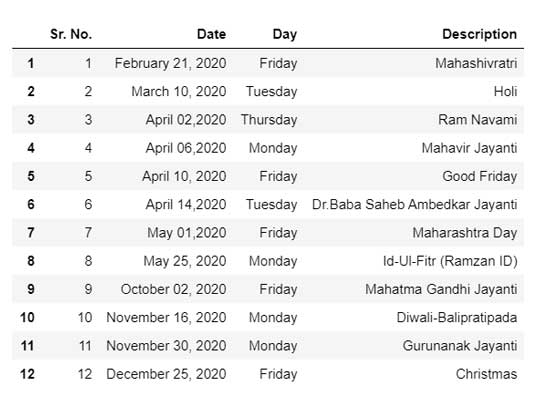
Después de realizar los cambios a continuación, ahora se ve perfecto con el encabezado adecuado DataFrame.
temp_df = tables[0].df temp_df.rename(columns=temp_df.iloc[0]).drop(temp_df.index[0])
Puede encontrar el código completo en esta dirección:
Camelot también proporciona CLI. Uno puede pasar por esta enlace para comandos CLI.
También hay una interfaz web para esta increíble biblioteca y se llama Excalibur.
Después de escuchar los nombres Camelot & Excalibur Ahora entiendo por qué se llama ‘Extracción de tablas PDF para Humanos’ ¡¡Espero que tú también puedas adivinar !!
Para el uso avanzado de Camelot, consulte esta.
Ventajas de Camelot
- Camelot proporciona mucha flexibilidad a la hora de extraer las tablas mediante el número de parámetros.
- Las tablas que no se extraen correctamente se pueden descartar en función de métricas como la precisión y los espacios en blanco. Esto lo podemos obtener analizando el método de informe.
- Cada tabla se puede convertir en un
DataFramede pandas que podemos usar para un análisis o procesamiento adicional. - Camelot brinda la flexibilidad de exportar tablas a múltiples formatos como
CSV, Excel, JSON, HTML y Sqlite.
Hemos entendido camelot biblioteca para extraer las tablas de archivos PDF que puede utilizar en su próximo proyecto.
Agradezco que hayas llegado hasta el final.






Añadir comentario