
Bienvenido, les saluda Miguel y en esta ocasión les traigo este post.
Índice
Un enfoque de aprendizaje profundo compatible con códigos para principiantes
Soy muy de la opinión de que es crucial construir proyectos si uno realmente quiere aprender deep learning. Entonces, si está buscando comenzar a hacer sus propios proyectos de aprendizaje profundo, está en el lugar correcto. ¡Quédese hasta el final del tutorial y tendrá su primer proyecto de aprendizaje profundo!
Les voy a mostrar un proyecto simple que implementa redes neuronales de avance en el famoso conjunto de datos CIFAR-10, usando PyTorch.
Prerrequisitos
- Se requiere un conocimiento superficial de las redes neuronales para seguir este tutorial.
- Sería útil estar familiarizado con Python.
Sobre el conjunto de datos
De acuerdo con la página web oficial del conjunto de datos CIFAR-10:
“El conjunto de datos CIFAR-10 consta de 60000 imágenes en color de 32×32 en 10 clases, con 6000 imágenes por clase. Hay 50000 imágenes de entrenamiento y 10000 imágenes de prueba. El conjunto de datos se divide en cinco lotes de entrenamiento y un lote de prueba, cada uno con 10000 imágenes. El lote de prueba contiene exactamente 1000 imágenes seleccionadas al azar de cada clase. Los lotes de entrenamiento contienen las imágenes restantes en orden aleatorio, pero algunos lotes de entrenamiento pueden contener más imágenes de una clase que de otra. Entre ellos, los lotes de capacitación contienen exactamente 5000 imágenes de cada clase «.
Como luce :

Entonces, este es básicamente un problema de clasificación de clases múltiples donde nuestra red neuronal va a tomar una imagen de entrada y predecir a qué clase pertenece esa imagen de entrada entre las 10 clases que se muestran arriba.
¡Vamos a codificar!
Comenzaremos importando todos los paquetes necesarios:
import torch import torchvision import numpy as np import matplotlib.pyplot as plt import torch.nn as nn import torch.nn.functional as F from torchvision.datasets import CIFAR10 from torchvision.transforms import ToTensor from torchvision.utils import make_grid from torch.utils.data.dataloader import DataLoader from torch.utils.data import random_split %matplotlib inline
Ahora tendremos que descargar el conjunto de datos. Torchvision de PyTorch ya nos proporciona un montón de conjuntos de datos, incluido el conjunto de datos Cifar10 que usaremos aquí. Por lo tanto, descargaremos el tren y los conjuntos de datos de prueba por separado de torchvision.datasets.
dataset = CIFAR10(root='data/', download=True, transform=ToTensor()) test_dataset = CIFAR10(root='data/', train=False, transform=ToTensor())
Observe que transformamos nuestro conjunto de datos de imágenes en tensores usando –
transform=ToTensor()
Ahora que tenemos nuestro conjunto de datos listo, podemos realizar algunos análisis de datos.
# size of train data
dataset_size = len(dataset)
dataset_size
#output : 50,000
# size of test data
test_dataset_size = len(test_dataset)
test_dataset_size
#output : 10,000
# classes or categories present inside the dataset
classes = dataset.classes
classes
''' output :
['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
'''
# total no of classes
num_classes = len(classes)
num_classes
#output : 10
# image shape
img, label = dataset[0]
img_shape = img.shape
img_shape
#output : torch.Size([3, 32, 32])
# no of images present in each class
freq={}
for i in classes:
freq[i]=0
for imgs,labels in dataset:
freq[classes[labels]] +=1
for k,v in freq.items():
print('Class {} contains {} images'.format(k,v))
'''ouput :
Class airplane contains 5000 images
Class automobile contains 5000 images
Class bird contains 5000 images
Class cat contains 5000 images
Class deer contains 5000 images
Class dog contains 5000 images
Class frog contains 5000 images
Class horse contains 5000 images
Class ship contains 5000 images
Class truck contains 5000 images
'''
También podemos visualizar una imagen aleatoria del conjunto de datos como:
# Visualise a random image data
img, label = dataset[11]
plt.imshow(img.permute((1, 2, 0)))
print('Label (numeric):', label)
print('Label (textual):', classes[label])
# Output: Label (numeric): 7 Label (textual): horse
La imagen está muy borrosa y es difícil incluso para un ojo humano decir con certeza lo que contiene la imagen.
Dividamos nuestro conjunto de datos en conjuntos de datos de entrenamiento y validación.
# set the train and validation sizes torch.manual_seed(43) val_size = 5000 train_size = len(dataset) - val_size # train/valid split train_ds, val_ds = random_split(dataset, [train_size, val_size]) len(train_ds), len(val_ds) #Output : (45000, 5000)
Ahora establezcamos un tamaño de lote (que es un hiperparámetro) y visualicemos un solo lote de imágenes.
# set the batch size
batch_size=128
# put the data into dataloaders
train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4,
pin_memory=True)
val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size*2, num_workers=4,
pin_memory=True)
# visualise a batch of images
for images, _ in train_loader:
print('images.shape:', images.shape)
plt.figure(figsize=(16,8))
plt.axis('off')
plt.imshow(make_grid(images, nrow=16).permute((1, 2, 0)))
break
# Output: images.shape: torch.Size([128, 3, 32, 32])

Se utilizan algunos hiperparámetros, como batch_size, shuffle, num_workers y pin_memory. Puede jugar con estos valores y comprobar cuál funciona mejor para usted.
En este punto, comenzaremos a construir nuestro modelo base de clasificación de imágenes que contendrá todas las funciones auxiliares que necesitaremos y también la función de ajuste que se llamará en la fase de entrenamiento.
# define an accuracy function
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
# prepare a base class for training and validation
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], val_loss: {:.4f}, val_acc: {:.4f}"
.format(epoch, result['val_loss'], result['val_acc']))
# define an evaluation function
def evaluate(model, val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
# define the fit function
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
model.epoch_end(epoch, result)
history.append(result)
return history
También asegurémonos de que nuestra GPU esté habilitada y se use durante el entrenamiento.
torch.cuda.is_available()
#output: True
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
device
#Output : device(type='cuda')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
Algunas funciones de ayuda más:
# define function for plotting the losses
def plot_losses(history):
losses = [x['val_loss'] for x in history]
plt.plot(losses, '-x')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Loss vs. No. of epochs');
# define function for plotting the accuracies
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs');
# move the dataloaders to device, which is gpu preferably
train_loader = DeviceDataLoader(train_loader, device)
val_loader = DeviceDataLoader(val_loader, device)
test_loader = DeviceDataLoader(test_loader, device)
Ahora el modelo de entrenamiento:
# set the input and output sizes of the network input_size = 3*32*32 output_size = 10 ''' Extend the ImageClassificationBase class to complete the model definition. Here, we define our network's architecture. ''' class CIFAR10Model(ImageClassificationBase): def __init__(self): super().__init__() self.linear1 = nn.Linear(input_size, 2020) self.linear2 = nn.Linear(2020, 505) self.linear3 = nn.Linear(505, 125) self.linear4 = nn.Linear(125, output_size) def forward(self, xb): # Flatten images into vectors out = xb.view(xb.size(0), -1) out = self.linear1(out) out = F.relu(out) out = self.linear2(out) out = F.relu(out) out = self.linear3(out) out = F.relu(out) out = self.linear4(out) return out
Como está claro, tenemos 4 capas lineales de avance con capas: 10 -> 2020, 2020 -> 505, 505 -> 125 y 125 -> 10. Luego, en el método directo, después de cada capa lineal, se utiliza una función de activación de ReLU.
# move the model to gpu device model = to_device(CIFAR10Model(), device)
'''evaluate the model before training to check the validation loss & accuracy with the initial set of weights. ''' history = [evaluate(model, val_loader)] history
#Output : ['val_acc': 0.1067095622420311, 'val_loss': 2.3030261993408203]
Ahora, entrenaremos el modelo usando la función de ajuste para reducir la pérdida de validación y mejorar la precisión. Experimentaremos con diferentes no. de épocas y tasas de aprendizaje para lograr la mayor precisión posible.
Comencemos con una tasa de aprendizaje bastante alta y un alto no. de épocas para permitir que nuestro modelo explore la naturaleza de la red. Siempre es una buena idea comenzar con una alta tasa de aprendizaje para que podamos tener una buena idea de la red en su conjunto y, en base a eso, podamos planificar nuestros próximos pasos. Eventualmente, bajaremos la tasa de aprendizaje para una convergencia más rápida.
history += fit(45, 7e-2, model, train_loader, val_loader)
Salida:
Epoch [0], val_loss: 1.9024, val_acc: 0.3116 Epoch [1], val_loss: 1.9146, val_acc: 0.3141 Epoch [2], val_loss: 1.7534, val_acc: 0.3651 Epoch [3], val_loss: 1.6731, val_acc: 0.3953 Epoch [4], val_loss: 1.6696, val_acc: 0.3959 Epoch [5], val_loss: 1.6071, val_acc: 0.4267 Epoch [6], val_loss: 1.6354, val_acc: 0.4146 Epoch [7], val_loss: 1.6794, val_acc: 0.4037 Epoch [8], val_loss: 1.5566, val_acc: 0.4397 Epoch [9], val_loss: 1.5156, val_acc: 0.4454 Epoch [10], val_loss: 1.5073, val_acc: 0.4579 Epoch [11], val_loss: 1.5743, val_acc: 0.4325 Epoch [12], val_loss: 1.4422, val_acc: 0.4819 Epoch [13], val_loss: 1.4832, val_acc: 0.4732 Epoch [14], val_loss: 1.4635, val_acc: 0.4793 Epoch [15], val_loss: 1.4615, val_acc: 0.4825 Epoch [16], val_loss: 1.4626, val_acc: 0.4765 Epoch [17], val_loss: 1.6189, val_acc: 0.4308 Epoch [18], val_loss: 1.4110, val_acc: 0.5007 Epoch [19], val_loss: 1.4181, val_acc: 0.5061 Epoch [20], val_loss: 1.5151, val_acc: 0.4843 Epoch [21], val_loss: 1.5199, val_acc: 0.4658 Epoch [22], val_loss: 1.4862, val_acc: 0.4893 Epoch [23], val_loss: 1.4905, val_acc: 0.4982 Epoch [24], val_loss: 1.3613, val_acc: 0.5252 Epoch [25], val_loss: 1.4618, val_acc: 0.5094 Epoch [26], val_loss: 1.3896, val_acc: 0.5219 Epoch [27], val_loss: 1.4939, val_acc: 0.5064 Epoch [28], val_loss: 1.4625, val_acc: 0.4968 Epoch [29], val_loss: 1.4153, val_acc: 0.5235 Epoch [30], val_loss: 1.4081, val_acc: 0.5321 Epoch [31], val_loss: 1.5119, val_acc: 0.5188 Epoch [32], val_loss: 1.7090, val_acc: 0.4417 Epoch [33], val_loss: 1.5500, val_acc: 0.4975 Epoch [34], val_loss: 1.5853, val_acc: 0.5010 Epoch [35], val_loss: 1.5117, val_acc: 0.5197 Epoch [36], val_loss: 1.5295, val_acc: 0.5257 Epoch [37], val_loss: 1.6850, val_acc: 0.5104 Epoch [38], val_loss: 1.7531, val_acc: 0.4895 Epoch [39], val_loss: 1.6858, val_acc: 0.5139 Epoch [40], val_loss: 1.7323, val_acc: 0.5090 Epoch [41], val_loss: 1.6911, val_acc: 0.5080 Epoch [42], val_loss: 2.0147, val_acc: 0.4776 Epoch [43], val_loss: 1.8985, val_acc: 0.4761 Epoch [44], val_loss: 1.7531, val_acc: 0.5275
Podemos ver que nuestro modelo comenzó desde el 31% y terminó con una precisión de validación de aproximadamente 52%, con una disminución significativa en la pérdida de validación también. Ahora, podemos reducir gradualmente la tasa de aprendizaje para que nuestro modelo encuentre los mínimos globales y converja más rápidamente.
history += fit(5, 1e-2, model, train_loader, val_loader)
Salida:
Epoch [0], val_loss: 1.6501, val_acc: 0.5639 Epoch [1], val_loss: 1.6819, val_acc: 0.5683 Epoch [2], val_loss: 1.7120, val_acc: 0.5721 Epoch [3], val_loss: 1.7336, val_acc: 0.5673 Epoch [4], val_loss: 1.7580, val_acc: 0.5670
history += fit(5, 3e-3, model, train_loader, val_loader)
Epoch [0], val_loss: 1.7671, val_acc: 0.5703 Epoch [1], val_loss: 1.7728, val_acc: 0.5695 Epoch [2], val_loss: 1.7765, val_acc: 0.5688 Epoch [3], val_loss: 1.7908, val_acc: 0.5666 Epoch [4], val_loss: 1.7943, val_acc: 0.5701
Puede continuar con esto y verificar si puede alcanzar una precisión de validación superior al 57%. Voy a detenerme aquí mismo y trazar mis gráficos.
# plot the losses plot_losses(history)
Salida:

# plot the accuracies plot_accuracies(history)
Salida:
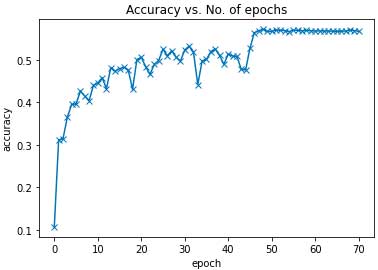
Claramente, tanto la pérdida como la precisión llegan a un nivel constante a medida que las épocas aumentan hasta cierto límite. Entonces podemos decir que nuestro modelo ha alcanzado su límite computacional y los parámetros aprendebles han convergido.
evaluar ( modelo , cargador_prueba )
# Output : 'val_acc': 0.571093738079071, 'val_loss': 1.7442058324813843
# guarde el modelo para uso futuro antorcha . guardar ( modelo . state_dict (), 'cifar10-feedforward.pth' )
Conclusión
- Exploración del conjunto de datos CIFAR-10
- Análisis de datos en el conjunto de datos
- Visualizaciones de imágenes individuales y lotes
- Modelo base de clasificación de imágenes de construcción
- Creación de una arquitectura de modelo de entrenamiento con redes neuronales de avance
- Entrenamiento de modelos en múltiples épocas con ajustes de hiperparámetros
- Evaluación del rendimiento del modelo utilizando nuestra función de precisión y la función de pérdida de entropía cruzada.
- Trazar gráficos de precisión y pérdida para visualizar los resultados.
Más lejos de aquí
Este era un modelo básico de red de alimentación directa que solo podía llegar hasta 57% de precisión de validación. Para el próximo proyecto, podría intentar agregar algunas redes neuronales convolucionales en lugar de redes neuronales simples de avance para comprobar cómo aumenta la precisión. Aún mejor, intente agregar algunas regularizaciones en la arquitectura del modelo CNN para lograr resultados de vanguardia en el conjunto de datos CIFAR-10.
Gracias por leer.





Añadir comentario