
Hola, me llamo Luis y en esta ocasión les traigo este nuevo post.
Índice
¿Qué es el aprendizaje automático y en qué se diferencia de la programación informática tradicional?
Lo entenderemos con la ayuda de los diagramas de bloques.
En cómputo tradicional r programación, alimentamos nuestro ordenador con los datos y el programa para obtener un software de calidad.
Tipos de aprendizaje automático
Para que sea fácil de entender, podemos clasificar el aprendizaje automático en las 3 categorías principales:
En esta categoría, los sistemas de aprendizaje automático se pueden clasificar según la cantidad y el tipo de supervisión requerida para la capacitación.
a) Aprendizaje supervisado
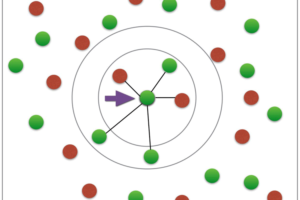
El aprendizaje supervisado se basa principalmente en la clasificación (ejemplo: un estudiante falla o no falla en el examen) pero también se puede utilizar para la regresión (ejemplo: predicción de ventas para una tienda).
Se prefiere este tipo de aprendizaje cuando los datos proporcionados están estructurados y etiquetados. El diagrama de bloques a continuación proporciona una idea de cómo se implementa este aprendizaje.
Algunos algoritmos importantes para el aprendizaje supervisado son:
-
k-Vecinosmás cercanos (KNN). - Máquinas de vectores de soporte (SVM).
- Árboles de decisión y bosques aleatorios.
- Regresión lineal.
- Regresión logística.
- Redes neuronales.
Algunos algoritmos de regresión como la regresión logística también se pueden utilizar para la clasificación.
b) Aprendizaje no supervisado
Este tipo de aprendizaje se prefiere cuando los datos proporcionados no están etiquetados, por lo que el sistema está programado para aprender sin las etiquetas.
Algunos algoritmos importantes para el aprendizaje no supervisado son:
- Agrupación (k-medias, análisis de agrupación jerárquica, maximización de expectativas).
- Visualización y reducción de dimensionalidad Incrustación de vecinos estocástica distribuida en t (t-SNE), Incrustación lineal local (LLE), Análisis de componentes principales (PCA), Análisis de componentes principales kernal.
- Aprendizaje de reglas de asociación (Apriori, Eclat).
Para separar un grupo de personas en subgrupos, se pueden utilizar diferentes métodos de agrupación.
c) Aprendizaje semi-supervisado
El aprendizaje semi-supervisado se utiliza para los datos mixtos (datos etiquetados + no etiquetados) que contiene.
- Una porción muy pequeña de datos etiquetados.
- Una gran parte de los datos no está etiquetada.
Para manejar tales tipos de datos, se pueden utilizar técnicas como Pseudo Labeling.
El pseudoetiquetado es una técnica en la que se predicen pseudoetiquetas para los datos no etiquetados utilizando parte etiquetada de los datos.
Ahora, los datos pseudoetiquetados y los datos etiquetados se utilizan juntos para generar un nuevo modelo. Este nuevo modelo se utiliza luego para hacer predicciones sobre los datos de prueba.
d) Aprendizaje reforzado
Entre todos los métodos de aprendizaje discutidos anteriormente, el aprendizaje por refuerzo funciona de manera diferente.
- El objetivo aquí es entrenar un sistema de aprendizaje (Agente) mediante prueba y error en un entorno desconocido.
- El agente es responsable de actuar según las observaciones y premia o penaliza según el entorno.
- Un agente tiene un algoritmo de aprendizaje y una política.
- Una política ayuda al agente a tomar la decisión correcta en un entorno desconocido.
- Y para maximizar las recompensas, el sistema necesita actualizar constantemente la política para manejar esta tarea, tenemos un algoritmo de aprendizaje.
a) Aprendizaje en línea
- El sistema es capaz de aprender de forma incremental
- Se alimentan pequeños grupos de datos (mini lotes) al sistema para permitir que el sistema aprenda secuencialmente (instancias individuales).
- Admite el aprendizaje fuera del núcleo (capaz de manejar datos que no caben en la memoria).
- La capacidad del sistema para aprender en un entorno nuevo o cambiante se denomina tasa de aprendizaje.
- Aquí, para lidiar con datos incorrectos, es necesario monitorear el sistema.
- Útil donde los datos se generan de forma continua.
b) Aprendizaje por lotes
- El sistema es capaz de aprender de forma incremental.
- También se denomina aprendizaje fuera de línea, ya que el sistema se entrena (el sistema ha aprendido) y luego se implementa en producción sin ningún proceso de aprendizaje adicional.
- El entrenamiento del sistema se realiza utilizando los datos disponibles.
- Lleva mucho tiempo, ya que se utiliza el conjunto de datos completo para entrenar el modelo.
- Requiere una gran cantidad de recursos informáticos para manejar grandes cantidades de datos.
- La aplicación es limitada.
a) Aprendizaje basado en instancias:
- No realiza generalizaciones explícitas.
- Compara las instancias que se ven en los datos de entrenamiento con los nuevos datos y establece similitudes entre los dos para tomar una decisión.
b) Aprendizaje basado en modelos
Un modelo se construye a partir del conjunto de ejemplos dados que luego se usa para hacer predicciones (inferencias).
Hay 6 pasos involucrados en la construcción del modelo:
- Definición del problema: en este paso identificamos el problema que buscamos resolver y tratamos de formular el problema matemáticamente.
- Generación de hipótesis: Es preferible realizar este paso antes de echar un vistazo a los datos para no sesgarlos.
- Extracción de datos: para recopilar datos de diversas fuentes.
- Exploración y transformación de datos:
- Modelado predictivo: esta es la parte donde seleccionamos el modelo (ejemplo: Regresión lineal) que debe implementarse para obtener los resultados deseados.
- Despliegue / Implementación del modelo: en este paso, entrenamos el modelo seleccionado en los datos de entrenamiento y hacemos predicciones. Se utilizan diferentes medidas de rendimiento para comparar y seleccionar el mejor modelo.
Gracias por leer este post.



Añadir comentario