
Bienvenido, soy Luis y aquí les traigo otro tutorial.
Índice
En menos de 5 minutos
Si estás leyendo esto, probablemente sepas lo que estás buscando 🤷. Así que iré directo a ello y asumiré que está familiarizado con lo que significa la segmentación de imágenes, la diferencia entre la segmentación semántica y la segmentación de instancias, y diferentes modelos de segmentación como U-Net, Mask, R-CNN, etc.
Si no, yo altamente recomiendo la lectura de este excelente artículo sobre Analítica Vidhya para una amplia introducción al tema, con un ejemplo en el final utilizando Máscara R-CNN.
La mayoría de los tutoriales de segmentación de imágenes en línea, utilizan conjuntos de datos preprocesados y etiquetados con imágenes y máscaras de verdad generadas.
Esto casi nunca ocurre en proyectos reales cuando se quiere trabajar en una tarea similar. Me he enfrentado a este mismo problema y he pasado horas INCONTABLES tratando de encontrar un ejemplo lo suficientemente simple y COMPLETO mientras trabajaba en un proyecto de Segmentación de Instancias . No pude y por lo tanto decidí escribir el mío propio 🙂
Aquí hay una visualización simple de lo que haremos en este artículo 🙂
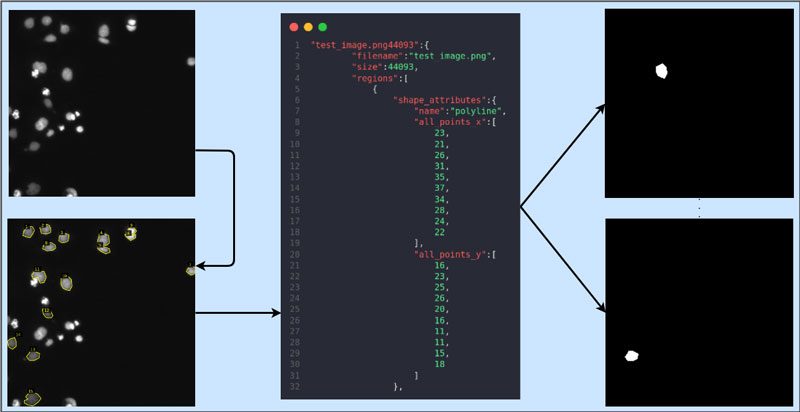
Anotador de imágenes VGG (VIA)
VIA es un anotador extremadamente ligero con soporte tanto para imágenes como para videos. Puedes pasar por el página de inicio del proyecto para saber mas. Mientras usa VIA, tiene dos opciones: V2 o V3. Intentaré explicar las diferencias a continuación:
V2es mucho más antiguo pero adecuado para tareas básicas y tiene una interfaz simple.- A diferencia de
V2,V3admite anotador de video y audio. V2es preferible si su objetivo es la segmentación de imágenes con múltiples opciones de exportación comoJSONyCSV.- Los proyectos
V2no son compatibles con los proyectosV3.
Usaré V2 para este artículo. Puede descargar los archivos necesarios aquí. O, si desea probar VIA en línea, puede hacerlo aquí.
Cómo
Usaré el Kaggle Conjunto de datos de núcleos y anote una de las imágenes de prueba para generar una máscara de segmentación.
Divulgación completa, NO soy un profesional médico certificado, y las anotaciones que estoy haciendo son solo por el bien de este artículo. También puede adaptar rápidamente el proceso a otros tipos de objetos.
El árbol de la carpeta raíz se muestra a continuación. via.html es el archivo que usaremos para anotar nuestras imágenes. Se encuentra en el enlace de descarga ZIP VIA V2 proporcionado arriba.
Coloque todas las imágenes que se van a anotar en el images carpeta. maskGen.py es un script para convertir las anotaciones en máscaras.
├── images │ └── test_image.png ├── maskGen.py └── via.html
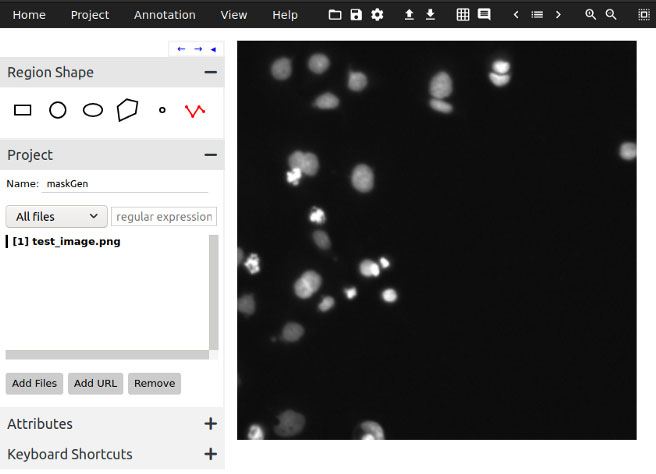
Se abrirá en su navegador predeterminado. Debajo Forma de la región, seleccione la herramienta Polilínea (última opción) y asigne un nombre a su proyecto.
Luego haga clic en Agregar archivos y seleccione todas las imágenes que desee anotar. En este punto, su pantalla debería verse como la Figura 1.
Haga clic en el borde de un objeto y dibuje un polígono alrededor del objeto. Puede terminar el polígono presionando Enter, o si ha cometido un error, presione Retroceso. Repita esto para todos los objetos. Una vez que haya terminado, su pantalla debería verse como la Figura 2.

Una vez que haya terminado, haga clic en la pestaña Anotación en la parte superior y seleccione Exportar anotaciones (como JSON). Se guardará un archivo JSON en su dispositivo.
Busque este archivo y transfiéralo a la carpeta raíz según el árbol que se muestra arriba.
Ahora, su carpeta raíz debería verse así.
├── images │ └── test_image.png ├── maskGen_json.json ├── maskGen.py └── via.html
maskGen.py se da en la esencia a continuación. Lee el archivo JSON, recuerda las coordenadas del polígono para cada objeto de máscara, genera máscaras y las guarda en formato .png.
Para cada imagen en la carpeta images, el script crea una nueva carpeta con el nombre de la imagen, y esta carpeta contiene subcarpetas tanto de la imagen original como de los archivos de máscara generados.
Asegúrese de actualizar la variable json_path al nombre de su archivo JSON y establezca la altura y el ancho de la máscara. Algunas de las máscaras generadas se muestran después de la esencia.
import os
import cv2
import json
import numpy as np
source_folder = os.path.join(os.getcwd(), "images")
json_path = "maskGen_json.json" # Relative to root directory
count = 0 # Count of total images saved
file_bbs = {} # Dictionary containing polygon coordinates for mask
MASK_WIDTH = 256 # Dimensions should match those of ground truth image
MASK_HEIGHT = 256
# Read JSON file
with open(json_path) as f:
data = json.load(f)
# Extract X and Y coordinates if available and update dictionary
def add_to_dict(data, itr, key, count):
try:
x_points = data[itr]["regions"][count]["shape_attributes"]["all_points_x"]
y_points = data[itr]["regions"][count]["shape_attributes"]["all_points_y"]
except:
print("No BB. Skipping", key)
return
all_points = []
for i, x in enumerate(x_points):
all_points.append([x, y_points[i]])
file_bbs[key] = all_points
for itr in data:
file_name_json = data[itr]["filename"]
sub_count = 0 # Contains count of masks for a single ground truth image
if len(data[itr]["regions"]) > 1:
for _ in range(len(data[itr]["regions"])):
key = file_name_json[:-4] + "*" + str(sub_count+1)
add_to_dict(data, itr, key, sub_count)
sub_count += 1
else:
add_to_dict(data, itr, file_name_json[:-4], 0)
print("\nDict size: ", len(file_bbs))
for file_name in os.listdir(source_folder):
to_save_folder = os.path.join(source_folder, file_name[:-4])
image_folder = os.path.join(to_save_folder, "images")
mask_folder = os.path.join(to_save_folder, "masks")
curr_img = os.path.join(source_folder, file_name)
# make folders and copy image to new location
os.mkdir(to_save_folder)
os.mkdir(image_folder)
os.mkdir(mask_folder)
os.rename(curr_img, os.path.join(image_folder, file_name))
# For each entry in dictionary, generate mask and save in correponding
# folder
for itr in file_bbs:
num_masks = itr.split("*")
to_save_folder = os.path.join(source_folder, num_masks[0])
mask_folder = os.path.join(to_save_folder, "masks")
mask = np.zeros((MASK_WIDTH, MASK_HEIGHT))
try:
arr = np.array(file_bbs[itr])
except:
print("Not found:", itr)
continue
count += 1
cv2.fillPoly(mask, [arr], color=(255))
if len(num_masks) > 1:
cv2.imwrite(os.path.join(mask_folder, itr.replace("*", "_") + ".png") , mask)
else:
cv2.imwrite(os.path.join(mask_folder, itr + ".png") , mask)
print("Images saved:", count)
Si ha hecho todo bien, el árbol de la carpeta raíz final debería verse así. El número de archivos en cada mask.
La carpeta corresponde al número de objetos que ha anotado en la imagen de verdad del terreno.
├── images │ └── test_image │ ├── images │ │ └── test_image.png │ └── masks │ ├── test_image_10.png │ ├── test_image_11.png │ ├── test_image_12.png │ ├── test_image_13.png │ ├── test_image_14.png │ ├── test_image_15.png │ ├── test_image_1.png │ ├── test_image_2.png │ ├── test_image_3.png │ ├── test_image_4.png │ ├── test_image_5.png │ ├── test_image_6.png │ ├── test_image_7.png │ ├── test_image_8.png │ └── test_image_9.png ├── maskGen_json.json ├── maskGen.py └── via.html

sugerencia / aclaración.
Espero que te sea de utilidad. Gracias por leer este artículo.






Añadir comentario