
Hola, me llamo Miguel y esta vez les traigo un nuevo post.
Índice
Comparación de velocidad y rendimiento
Recientemente terminé un problema de clasificación de clases múltiples dado como tarea para llevar a casa para un puesto de científico de datos.
Fue una buena oportunidad para comparar las dos implementaciones de última generación de árboles de decisión de aumento de gradiente que son XGBoost y LightGBM .
Ambos algoritmos son tan poderosos que se destacan entre los modelos de aprendizaje automático con mejor rendimiento.
El conjunto de datos contiene más de 60 mil observaciones y 103 características numéricas. La variable de destino contiene 9 clases diferentes.
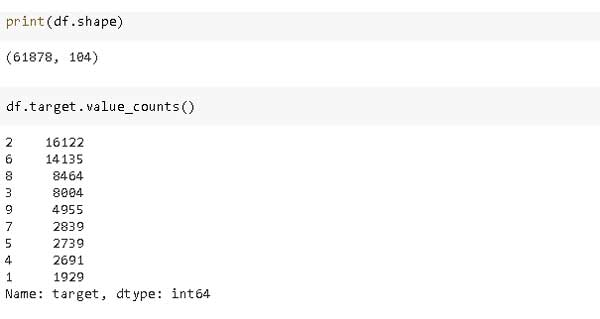
Desde el enfoque de este post es la comparación de XGBoost y LightGBM, pasaré por alto el análisis exploratorio de datos y datos disputas partes. He logrado eliminar 11 características y aproximadamente 2000 valores atípicos.
Es importante tener en cuenta que todas las técnicas aplicadas en el proceso de manipulación de datos se realizan después de que el tren y los conjuntos de prueba se separan. De lo contrario, tendríamos que lidiar con la fuga de datos, que es un problema grave en el aprendizaje automático.
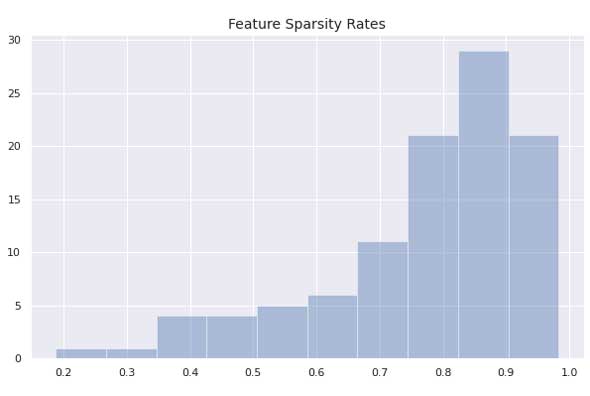
El espacio de características es muy escaso (es decir, las características consisten principalmente en ceros). A continuación se muestra un histograma que muestra las proporciones de escasez de características.
LightGBM
LightGBM, creado por investigadores de Microsoft, es una implementación de árboles de decisión impulsados por gradientes (GBDT).
Antes de LightGBM, las implementaciones existentes antes de GBDT se vuelven más lentas a medida que aumenta la cantidad de instancias o características. LightGBM tiene como objetivo resolver este problema de eficiencia , especialmente con grandes conjuntos de datos.
LightGBM utiliza dos técnicas para superar los problemas de eficiencia con grandes conjuntos de datos:
-
GOSS(muestreo de gradiente de un lado). -
EFB(paquete de funciones exclusivas).
Volvamos a nuestra implementación. LightGBM requiere que los datos estén en un formato específico, por lo que usamos la función Dataset.
import lightgbm as lgb lgb_train = lgb.Dataset(X_train, y_train) lgb_test = lgb.Dataset(X_test, y_test)
Los hiperparámetros juegan un papel fundamental en el rendimiento de LightGBM y XGBoost. Es posible que deba dedicar una buena cantidad de tiempo a ajustar los hiperparámetros. Eventualmente, creará su propio camino o estrategia que acelerará el proceso de ajuste.
Hay muchos hiperparámetros. Algunos son más importantes en términos de precisión y velocidad . Algunos de ellos se utilizan principalmente para evitar el sobreajuste.
Los hiperparámetros se pueden pasar como un diccionario al modelo. Aquí están los hiperparámetros que me dan los mejores parámetros.
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'metric': 'multi_logloss',
'num_class':9,
'max_depth':9,
'num_leaves': 100,
'min_data_in_leaf':300,
'learning_rate': 0.03,
'feature_fraction': 0.7,
'bagging_fraction':0.8,
'bagging_freq':10,
'lambda_l1': 1,
'verbose': 0
}
No existe una regla estricta para definir valores óptimos de hiperparámetros. Es más como un proceso educado de prueba y error.
Si sabe lo que hace un hiperparámetro en particular, el proceso de ajuste será mucho más eficiente que probar valores aleatorios.
-
Max_depth: la profundidad máxima de un solo árbol. -
Num_leaves: Controla el número de hojas de un árbol. LightGBM utiliza un algoritmo de crecimiento de árboles por hojas, por lo que num_leaves es el parámetro principal para controlar la complejidad del árbol. -
Min_data_in_leaf: Representa el número mínimo de muestras (es decir, observaciones) necesarias para estar en una hoja, lo cual es muy importante para controlar el sobreajuste. -
Feature_fraction: La proporción de características que se seleccionan al azar en cada nodo. -
Bagging_fractionybagging_freqtambién ayudan a evitar el sobreajuste.
La lista completa de hiperparámetros de LightGBM se puede encontrar aquí.
Ahora podemos entrenar el modelo . El siguiente bloque de código entrena el modelo con el conjunto de entrenamiento y evalúa el rendimiento del modelo en los conjuntos de entrenamiento y validación.%%timeitgbm = lgb.train(params, lgb_train, num_boost_round=700, valid_sets=[lgb_train, lgb_test], early_stopping_rounds=10)

Las pérdidas de registros en el tren y los conjuntos de validación son 0,383 y 0,418, respectivamente. Se necesitan 2 minutos y 26 segundos en promedio para ejecutar el entrenamiento.
Puede lograr una pérdida muy baja en estos modelos, pero provocará un ajuste excesivo. Es más importante tener un modelo equilibrado en términos de precisión del tren y la prueba. Además, el objetivo de la tarea era lograr una pérdida logarítmica de 0,41.
Es una buena práctica jugar con los valores de los hiperparámetros y ver sus efectos tanto en la precisión como en el sobreajuste.
XGBoost
XGBoost es una implementación del algoritmo GBDT. Es tan eficiente que dominó algunas competiciones importantes en Kaggle.
El conjunto de datos también debe formatearse de una manera particular para XGBoost.
XGBoost también tiene muchos hiperparámetros que deben ajustarse correctamente para crear un modelo sólido y preciso. Estos son los valores de hiperparámetros que he encontrado para alcanzar un resultado satisfactorio y, al mismo tiempo, minimizar el sobreajuste.
Hiperparámetros:
-
Max_depth: la profundidad máxima de un árbol. -
Min_child_weight: la suma mínima de peso de instancia necesaria en un niño. Mantenerlo alto evita que el niño sea demasiado específico y, por lo tanto, ayuda a evitar un ajuste excesivo. -
Gamma: Reducción de pérdida mínima requerida para hacer una partición adicional en un nodo hoja del árbol. Nuevamente, cuanto más grande sea el juego, es menos probable que el modelo se sobreajuste. -
Submuestra: La proporción de filas que se seleccionan al azar antes de cultivar árboles. También se puede utilizar una submuestra para evitar el sobreajuste. -
Eta: la tasa de aprendizaje. Mantenerlo alto hace que el modelo aprenda más rápido pero aumenta la posibilidad de sobreajuste al mismo tiempo. -
Alfa: plazo de regularizaciónL1.
La lista completa de hiperparámetros de XGBoost se puede encontrar aquí.
Ahora podemos entrenar nuestro modelo. Pasamos los parámetros, el conjunto de entrenamiento y el número de rondas a ejecutar. Puede aumentar el número de rondas y obtener una mayor precisión, pero siempre existe el riesgo de sobreajuste.
%%timeitbst = xgb.train( params_xgb, dtrain , 700, evals=[(dtrain,'eval'),(dtest, 'eval')], verbose_eval=True )

Las pérdidas de registros en el tren y los conjuntos de validación son 0,369 y 0,415, respectivamente. Se necesitan 3 minutos y 52 segundos en promedio para ejecutar el entrenamiento.


Las pérdidas están bastante cerca, por lo que podemos concluir que, en términos de precisión, estos modelos funcionan aproximadamente igual en este conjunto de datos con los valores de hiperparámetros seleccionados.
Cuando se trata de velocidad, LightGBM supera a XGBoost en aproximadamente un 40%.
Gracias por leer. Por favor, avíseme si tiene algún comentario.






Añadir comentario