
Bienvenido, soy Luis y hoy les traigo otro nuevo artículo.
El aprendizaje por refuerzo es un campo en rápido movimiento. Muchas empresas se están dando cuenta del potencial de RL.
Recientemente, el éxito de DeepMind de Google en la formación del agente AlphaGo de RL para derrotar al campeón mundial de Go es asombroso.
El documental completo está disponible aquí:
Pero, ¿qué es RL? RL es una rama del aprendizaje automático en la que el agente aprende un comportamiento mediante prueba y error.
Eso significa que el agente interactúa con su entorno sin ninguna supervisión explícita, el comportamiento «deseado» se enfatiza mediante una señal de retroalimentación llamada recompensa.
El agente es recompensado cuando realiza una acción «buena» o puede ser «castigado» cuando realiza una acción «mala».
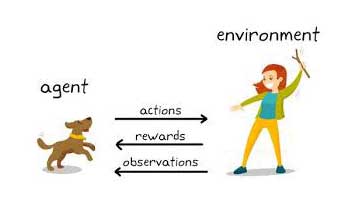
En la terminología de RL, las observaciones se conocen como estados. Por lo tanto, la ruta de aprendizaje del agente comprende una serie de acciones tomadas en los estados y la obtención de recompensas como retroalimentación.
En las primeras etapas del aprendizaje, el agente no sabe cuál es la mejor acción a realizar en un estado específico, después de todo, ese es el objetivo del aprendizaje.
Algunas de las recompensas pueden retrasarse. Este objetivo se describe cómo maximizar el rendimiento esperado que se expresa de la siguiente manera:

Cuando γ está más cerca de 0, el agente es miope (da más énfasis a la recompensa inmediata). Si el factor de descuento está más cerca de 1, el agente tiene más visión de futuro.
El objetivo de los algoritmos RL es estimar el rendimiento esperado cuando el agente realiza una acción en un estado dado mientras sigue una política. Estos se conocen como valores Q y estiman «qué tan bueno» es para el agente realizar una acción determinada en un estado determinado.
Q-learning es uno de los algoritmos RL más populares. QL permite que el agente conozca los valores de los pares estado-acción a través de actualizaciones continuas. Siempre que cada par de estado-acción se visite y actualice con una frecuencia infinita, QL garantiza una política óptima. La ecuación para actualizar los valores de los pares de acción de estado en QL se da como:

Tenga en cuenta que, en QL, el agente observa el estado actual, Sₜ, toma una acción, Aₜ, y observa la recompensa Rₜ₊₁ y observa el siguiente estado Sₜ₊₁. Mientras se actualiza, QL considera la mejor acción posible (el operador máximo ) en el siguiente estado independientemente de la acción que se tomará con la política actual, Aₜ₊₁.
QL se conoce como un algoritmo fuera de política. La tasa de aprendizaje, α, determina la magnitud del paso que está dando el agente al actualizar sus estimaciones de valor Q.Otro algoritmo comúnmente aplicado se conoce como SARSA. En SARSA, la actualización sigue la siguiente ecuación:

Tenga en cuenta la diferencia entre las reglas de actualización de QL y SARSA: en SARSA, se considera el valor de la acción elegida por la política actual en Sₜ₊₁. Por lo tanto, SARSA se conoce como un algoritmo de política.
Para obtener más detalles sobre los procedimientos de los algoritmos QL y SARSA, puede consultar «Aprendizaje por refuerzo: una introducción de RS Sutton y AG Barto» .
En primer lugar, el entorno de los cartuchos tiene observaciones (estados) que son continuos. Puede verificar esto usando el siguiente código:
Pero QL y SARSA son aplicables en espacios de acción de estado finitos, por lo tanto, las observaciones continuas sobre la posición, la velocidad, el ángulo y la velocidad angular deben descretizarse (se agregan valores similares en cubos similares).
Esto se puede hacer con el siguiente fragmento de código:
Una vez que los espacios de estado son finitos, podemos escribir el algoritmo para el entrenamiento de QL y SARSA. Las reglas de actualización de los algoritmos, siguiendo las ecuaciones anteriores, se muestran en el siguiente ejemplo de código:
Estos nos permiten hacer el entrenamiento según el procedimiento QL / SARSA. Aquí, muestro el fragmento de código de muestra para el entrenamiento de QL.
def QLtrain(self):
cum_reward = np.zeros((self.num_episodes))
for ep in range(self.num_episodes):
current_state = self.discretize_state(self.env.reset())
done = False
while not done:
#choosing action according to our exploration-exploitation policy
action = self.choose_action(current_state)
obs, reward, done, _ = self.env.step(action)
cum_reward[ep]+=reward
new_state = self.discretize_state(obs)
self.QLupdate(current_state, action, reward, new_state)
current_state = new_state
self.getEpsilon()
self.getLR()
return cum_reward
print('QL based training is finished!')
Tenga en cuenta que estamos almacenando las recompensas obtenidas (el agente recibe +1 recompensa en cada paso siempre que esté en posición vertical).
Las siguientes gráficas muestran la recompensa acumulada obtenida por QL y SARSA durante un entrenamiento de 5000 episodios.


Podemos ver que tanto en QL como en SARSA, el agente puede acumular más recompensas (aprende una mejor estrategia) a medida que avanza el entrenamiento. Se ha demostrado que QL supera a SARSA (acumula recompensas más rápido).
Gracias por leer hasta el final.






Añadir comentario