
Hola, me llamo Luis y en esta ocasión les traigo otro artículo.
El mundo actual avanza rápidamente hacia el uso de la inteligencia artificial y el aprendizaje automático en todos los campos. La clave más importante para esto son los DATOS. Los datos son la clave de todo. Si como ingeniero de aprendizaje automático somos capaces de comprender y reestructurar los datos según nuestras necesidades, habríamos completado la mitad de la tarea.
Intentemos aprender a realizar EDA (Análisis de datos exploratorios) en datos.
Lo que aprenderemos en este tutorial:
- Recopile datos para nuestra aplicación.
- Estructura de los datos a nuestras necesidades.
- Visualice los datos.
Empecemos. Intentaremos obtener algunos datos de muestra: el conjunto de datos de IRIS, que es un conjunto de datos muy común que se utiliza cuando desea comenzar con el aprendizaje automático y el aprendizaje profundo.
1. Conjunto de datos
La fecha de cualquier aplicación se puede encontrar en varios sitios web como Kaggle, UCI, etc., o debe especificarse para alguna aplicación. Por ejemplo, si queremos clasificar entre un perro y un gato, no necesitamos crear un conjunto de datos mediante la recopilación de imágenes de perros y gatos, ya que hay varios conjuntos de datos disponibles. Aquí, intentemos inspeccionar el conjunto de datos Iris.
Busquemos los datos:
from sklearn.datasets import load_iris import pandas as pd data = load_iris() #3 df = pd.DataFrame(data.data, columns=data.feature_names) #4
Esto (# 3) obtendrá el conjunto de datos que sklearn tiene por defecto. La línea # 4 convierte el conjunto de datos en un marco de datos de pandas que se usa muy comúnmente para explorar conjuntos de datos con atributos de fila-columna.
Las primeras 5 filas de los datos se pueden ver usando:
df.head()
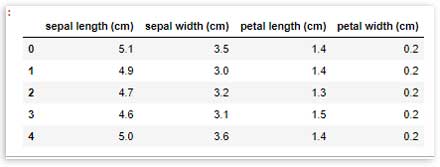
El número de filas y columnas, y los nombres de las columnas del conjunto de datos se pueden verificar con:
print(df.shape)
print(df.columns)
(150, 4)#Output
Index(['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)'],
dtype='object')#Output
Incluso podemos descargar el conjunto de datos directamente desde UCI desde aquí. El archivo CSV descargado se puede cargar en el df como:
df = pd.read_csv("path to csv file")
2. Estructurar los datos
Muy a menudo, el conjunto de datos tendrá varias características que no afectan directamente nuestra salida. El uso de tales funciones es inútil, ya que conduce a limitaciones de memoria innecesarias y, a veces, también a errores.
Podemos comprobar qué columnas son importantes o afectan más a la columna de salida comprobando la correlación de la columna de salida con las entradas. Probemos eso:
df.corr()

Claramente, puede ver arriba que la matriz de correlación nos ayuda a comprender cómo todas las características se ven afectadas entre sí. Para obtener más información sobre la matriz de correlación, haga clic en aquí.
Entonces, si nuestra columna de salida supusiera la longitud del sépalo (cm), mi salida y sería «longitud del sépalo (cm)» y mi entrada X sería ‘longitud del pétalo (cm)’,
‘ancho de pétalo (cm)’ ya que tienen una mayor correlación con y.
A tener en cuenta: Si ‘ancho del sépalo (cm)’ tuviera una correlación de -0,8, también lo tomaríamos como el valor de correlación, aunque es negativo, tiene un gran impacto en la producción y (inversamente proporcional).
A tener en cuenta: El valor de correlación en una matriz de correlación puede variar entre -1 (inversamente proporcional) y +1 (directamente proporcional).
3. Visualiza los datos
Este es un paso muy importante ya que puede ayudar de dos maneras:
- Ayudarle a comprender puntos importantes como cómo se divide la información, es decir, si se acerca a un rango pequeño de valores o más.
- Ayuda a comprender los límites de las decisiones.
- Preséntelo a las personas para que comprendan sus datos en lugar de mostrar algunas tablas.
Hay varios para trazar y presentar los datos como histogramas, gráficos de barras, diagramas de pares, etc.
Veamos cómo trazamos un histograma para el conjunto de datos de IRIS.
df.plot.hist( subplots = True, grid = True)

Al mirar el histograma, es más fácil para nosotros comprender cuál es el rango de valores para cada característica.
Simplemente tracemos los datos ahora.
df.plot(subplots=True)

Aparte de estos, hay varios otros gráficos que se pueden trazar fácilmente según la aplicación.
Por lo tanto, podemos concluir afirmando un hecho simple: un conjunto de datos bien estructurado es la clave inicial para un modelo de aprendizaje automático bueno y eficiente.
Gracias por leer.





Añadir comentario