
Hola, soy Miguel y en esta ocasión les traigo un nuevo post.
Índice
Apilar algoritmos fonéticos, métricas de cadenas e incrustación de caracteres para la coincidencia semántica de nombres
A menudo, cuando se trabaja con datos externos, ocurre que no existe un identificador común, como una clave numérica. En lugar de un identificador único, el nombre completo de una persona se puede usar como parte de una clave universal o compuesta para vincular datos; sin embargo, esta no es una solución a prueba de fallas.
Tomemos por ejemplo el nombre Alan Turing; fuentes de datos dispares podrían haber registrado el nombre de llamada Al Turing. La entrada de datos puede registrar inocentemente: Allan, Allen, o peor aún, errores tipográficos no detectados (Alam Turing) en sus bases de datos. Las soluciones empresariales de escaneo de documentos (OCR) también están plagadas de errores de lectura.
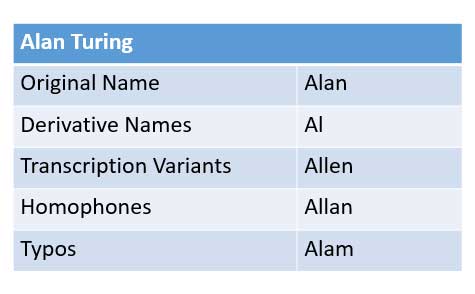
Un agente humano podría asignar intuitivamente estas variaciones a la misma entidad de Alan Turing a través del proceso cognitivo de aplicar lógica blanda para aproximar la ortografía y fonético características (sonoras). A menudo acortado hipocorismos no siempre tienen estas características y forman parte de las asociaciones aprendidas de los agentes, es decir Charles → Chip.
Lo que sigue es un estudio de la aplicación del aprendizaje automático para lograr una apariencia de lógica y semántica similares a las humanas para la identificación de nombres alternativos.
Recopilación de datos
Recogí varias listas de ortografías alternativas comunes para los nombres, alrededor de 17.500 pares. Los nombres están restringidos a ASCII e incluye muchos Unicode-Ejemplos transculturales codificados para evitar un ajuste excesivo a las convenciones de nombres occidentales.
La intuición de usar nombres como datos centrales para nuestro modelo es integrar métodos de conjunto en componentes de nombre, lo que requiere una coincidencia exacta o fonética de los apellidos para garantizar una mayor precisión / menos falsos positivos a costa de recordar algo.
Decidí desequilibrar las clases (1: 4) ya que un muestreo insuficiente de la clase negativa conduce a un sesgo artificial notable hacia la clase positiva. Es difícil aproximar las probabilidades a priori para cada clase, pero se supone que las clases están desequilibradas a favor de la clase negativa.
Selección de características
Hay muchas métricas de cadenas y algoritmos fonéticos para usar como características, el modelo de nivel base usa más de 20 características, que incluyen:
- Distancia de Levenshtein
- Similitud de bigrama
- Jaro distancia
- Distancia editex
- Codificación Soundex
Incorporación de personajes
Redes siamesas profundas LSTM han demostrado ser eficaces en aprender similitudes de texto. solía TensorFlow para entrenar estas redes en pares de nombres y usar predicciones fuera del pliegue como una característica del metamodelo.
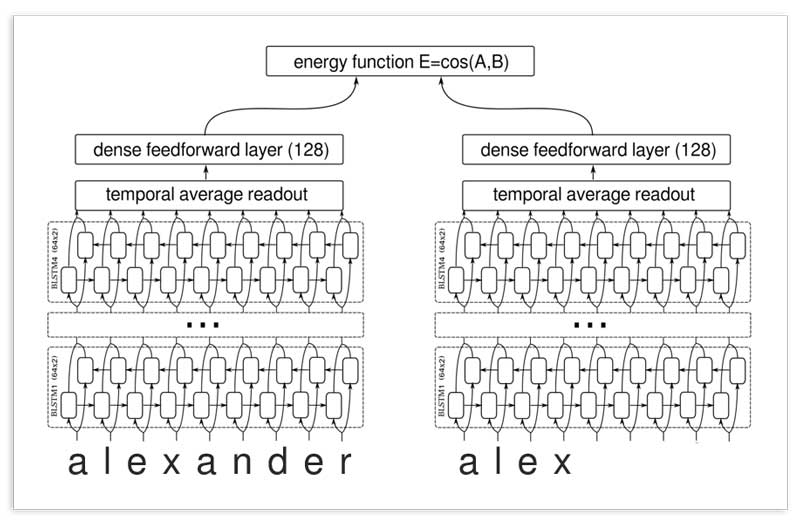
Transformaciones sin procesar
Los nombres se pueden transformar para ayudar a nuestro modelo a aprender nuevos patrones a partir de los mismos datos. Las transformaciones incluyen:
- Dividir nombres en sílabas para adquirir métricas significativas de cadenas de múltiples tokens (por ejemplo, clasificación de tokens y conjunto de tokens del paquete fuzzywuzzy)
- Eliminar terminaciones de nombres de alta frecuencia
- Eliminando vocales
- Convirtiendo a IPA (Alfabeto Fonético Internacional)
Construcción del modelo
Usé el paquete TPOT de AutoML para ayudar a seleccionar una canalización optimizada e hiperparámetros para un modelo de nivel base con F1 como métrica de puntuación.
El modelo base y las redes de incorporación de caracteres se apilaron mediante una validación cruzada estratificada de 10 veces para entrenar a un Regresión logística metamodelo. Se incluyeron algunas características del modelo base para proporcionar contexto y dimensionalidad adicionales para el metamodelo. Búsqueda de cuadrícula se utilizó para seleccionar los parámetros y características óptimos, dando prioridad a la precisión.
Evaluación
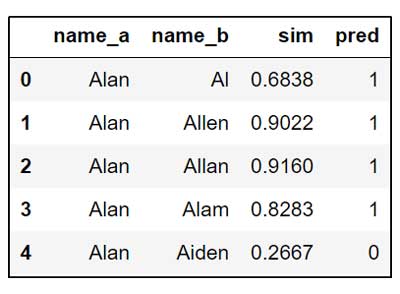
Métricas de evaluación para el conjunto de pruebas de nombres alternativos internacionales:


Este modelo fue entrenado específicamente para manejar nombres alternativos, pero se transfiere bien para clasificar correctamente todas las variantes antes mencionadas, incluidos los errores tipográficos.
Cómo utilizar HMNI en su proyecto
Instalar usando PIP a través de PyPI
pip install hmni
Guía de uso rápido: similitud de pares, vinculación de registros, deduplicación y normalización
Mantendré esta publicación actualizada con futuras versiones de HMNI; incluidos los modelos de mejor rendimiento, configuraciones específicas del idioma y optimizaciones de procesamiento de datos.
Gracias por leer este artículo.






Añadir comentario