Muy buenas, soy Luis y para hoy les traigo otro tutorial.
Índice
Paralelización de la validación cruzada de series temporales y la optimización de hiperparámetros con Dask (ejemplo aplicado con código)
La validación cruzada de Prophet con Dask se realiza de la misma manera que la validación cruzada de Prophet sin Dask, pero pasas parallel=’dask’ en el cross_validation() funcionar como;
En esta historia, usaremos Prophet para pronosticar la distancia promedio de un viaje en taxi amarillo a Nueva York por día. Para juzgar rápidamente el rendimiento de nuestro modelo, recurriremos a Dask para paralelizar la validación cruzada en las CPU de su sistema.
Después, aplicaremos este paralelizado cross_validation() para realizar la optimización de hiperparámetros (HPO) y ajustar ese modelo.
Contorno
- El conjunto de datos
- Modelo básico (ejecución de un profeta predeterminado)
- Paralelizar la validación cruzada con Dask
- Optimización de hiperparámetros con Dask (aplicación de validación cruzada)
El conjunto de datos
Nuestros datos van desde enero de 2009 hasta diciembre de 2019. Todos los datos se han derivado de Datos de registro de viaje de TLCy se puede leer directamente desde GitHub;
También hagamos un ETL simple (por ejemplo, asegurándonos de que las fechas estén establecidas .to_datetime() formato, eliminando algunos valores incorrectos) para formatear los datos para Prophet, luego .plot() para ver con qué estamos trabajando;

Modelo básico
Implementar un modelo Prophet básico es impresionantemente fácil. Solo importa, crea una instancia, .fit() y estás listo para empezar.
Debido a que los viajes en taxi se relacionan directamente con lo que la gente está haciendo, agreguemos también los días festivos en los Estados Unidos (estos están integrados en Prophet por defecto).
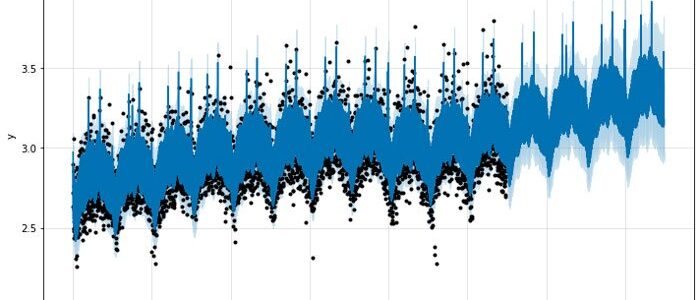
A partir de ahí, podemos simplemente hacer un marco de datos futuro de cualquier duración (4 años en nuestro caso), hacer predicciones y trazar el pronóstico del modelo en segundos;

Paralelizar la validación cruzada con Dask
Es un gráfico realmente bonito, pero ¿qué tan bueno es el modelo? Para averiguarlo, necesitamos realizar una validación cruzada.
Validación cruzada, a veces llamado estimación de rotación o prueba fuera de la muestra, es cualquiera de las diversas técnicas de validación de modelos similares para evaluar cómo los resultados de un análisis estadístico se generalizarán a un conjunto de datos independientes.Se utiliza principalmente en entornos en los que el objetivo es la predicción, y se desea estimar la precisión con la que un modelo predictivo funcionará en la práctica.
Conectémonos a nuestro Dask Client, luego hablemos sobre lo que significa;
Para garantizar la precisión de la IRL, la validación cruzada requiere que probemos nuestro modelo en una variedad de muestras de nuestros datos (tenemos muchos cálculos que realizar).
Nuestro cliente (client) nos permite tomar estos cálculos y ejecutarlos en paralelo en todas sus CPU, lo que significa que hacemos la tarea general mucho más rápido.
El profeta tiene incorporado .cross_validation() función que incluye:
- un modelo (
m) - el tiempo que debe cubrir cada pronóstico (
horizon) - con qué frecuencia hacer pronósticos (
period) - la cantidad de datos para entrenar antes de hacer predicciones (
initial)
Así como otros parámetros. Incluido en esos otros parámetros es un opcional parallel que está configurado para None por defecto. Simplemente configurando parallel=’dask’ permite la validación cruzada paralelizada.
Paralelizado (42 segundos) v. Predeterminado (1 min 19 segundos) – A tener en cuenta: al margen: solo 3% de MAPE listo para usar (oof)
Incluso en este breve ejemplo en el que hacemos solo 17 pronósticos, la paralelización con Dask me ahorró 37 segundos (su computadora puede ser más rápida).
A medida que crece el número de pronósticos, también debería aumentar la ventaja.
Optimización de hiperparámetros con Dask
Ahora busquemos el mejor modelo para nuestros datos. Podemos hacer esto con la optimización de hiperparámetros.
En el aprendizaje automático, optimización de hiperparámetros o tuning es el problema de elegir un conjunto de hiperparámetros óptimos para un algoritmo de aprendizaje.Un hiperparámetro es un parámetro cuyo valor se utiliza para controlar el proceso de aprendizaje. Por el contrario, se aprenden los valores de otros parámetros (normalmente ponderaciones de los nodos).
Existen varios hiperparámetros dentro de Prophet. Puede encontrar notas en las que se pueden afinar aquí. Por ahora, nos centraremos en 3:
change_point_prior_scale: Parámetro que modula la flexibilidad del
selección automática del punto de cambio. Los valores grandes permitirán muchos
puntos de cambio, los valores pequeños permitirán pocos puntos de cambio.seasonality_prior_scale: Parámetro que modula la fuerza del
modelo de estacionalidad. Los valores más grandes permiten que el modelo se ajuste a una temporada más grande.
fluctuaciones, valores menores amortiguan la estacionalidad. Se puede especificar
para estacionalidades individuales usando add_seasonality.seasonality_mode: ‘aditivo’ (predeterminado) o ‘multiplicativo’.
Podemos hacer un diccionario con estos y los valores de cada uno que queramos probar, luego generar todas sus combinaciones posibles con itertools.
Ahora solo llama a un simple for bucle y está realizando HPO con velocidad.
Con 4 opciones para cada prior_scaley 2 opciones para seasonality_mode, hay 32 combinaciones para probar. Cruce eso con nuestros 17 pronósticos y tenemos 544 pronósticos para calcular.
En total, esto tardó poco más de 20 minutos en ejecutarse en mi computadora portátil. Te reto a que lo corras con parallel=None y avíseme cuánto tiempo lleva.
Referencias
«Diagnóstico». Prophet, Facebook, 2020, facebook.github.io/prophet/docs/diagnostics.html.
«Pronóstico de series de tiempo». Pronóstico de series de tiempo: documentación de ejemplos de Dask, examples.dask.org/applications/forecasting-with-prophet.html.
¡Gracias por leer!
Puede encontrar el cuaderno de esta historia en GitHub .






Añadir comentario