Muy buenas, les saluda Luis y aquí les traigo otro tutorial.
Índice
Predecir los precios de los alimentos mediante regresión lineal
¿Qué es la ciencia de datos?
La ciencia de datos es un campo de estudio interdisciplinario que se centra en el uso del proceso científico para analizar datos sin procesar y aprovechar el conocimiento adquirido al analizar los datos para tomar decisiones basadas en datos y crear soluciones.
La ciencia de datos combina la experiencia en el dominio, las matemáticas, las estadísticas y las habilidades de resolución de problemas para obtener información significativa o inferencias a partir de datos sin procesar y, como tal, los científicos de datos deben equiparse con las habilidades modernas necesarias que los guiarán en la realización de dichos análisis e inferencias de datos.
¿Por qué es importante la ciencia de datos?
La ciencia de datos es un campo realmente interesante y de rápido crecimiento. A lo largo de los años, la ciencia de datos ha permitido a muchas organizaciones tomar decisiones basadas en datos y crear soluciones que les han ayudado a aumentar drásticamente los ingresos, predecir resultados indeseables como la rotación de empleados y hacer los preparativos necesarios para el futuro. Aprender a convertirse en científico de datos no solo lo equipa con las habilidades esenciales para el éxito en la industria, sino que también lo convierte en un activo valioso en cualquier organización que se encuentre.
Cosas necesarias que un científico de datos debe saber
- Matemáticas
- Estadísticas
- Programación
- Procesamiento / disputa de datos
- Análisis exploratorio de datos
- Visualización de datos
- AI / ML
- Despliegue del modelo
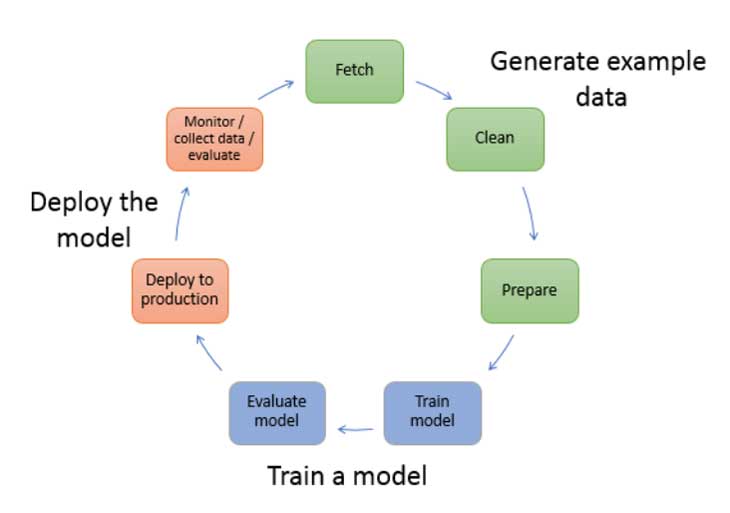
El flujo de un proyecto de ciencia de datos
Resolver un problema con la ciencia de datos, al igual que cualquier otra ciencia, requiere que utilice un enfoque sistemático o paso a paso para resolver el problema o construir la solución. Este proceso es muy similar al método científico. La razón de utilizar un enfoque sistemático para resolver problemas y crear soluciones utilizando la ciencia de datos es que podemos abordar el problema desde la raíz y, por lo tanto, crear soluciones o hacer predicciones basadas en datos que comprendemos profundamente.
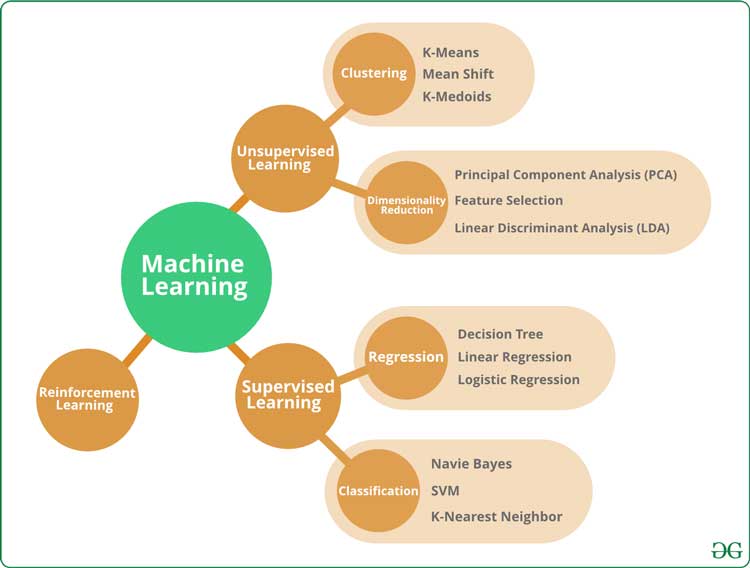
Aprendizaje automático
El aprendizaje automático es un subconjunto de la inteligencia artificial y es un concepto en el que las computadoras aprenden a hacer algo sin estar programadas explícitamente para hacerlo. En el nivel más básico, el aprendizaje automático es solo que las computadoras aprendan de los datos para resolver problemas, son demasiado complejos matemáticamente para ser resueltos con programación tradicional o convencional.
¿Qué son los algoritmos ML?
Para evitar una complejidad innecesaria, entendamos que los algoritmos de aprendizaje automático son funciones matemáticas preescritas y empaquetadas que manejan la computación que facilitan la construcción de modelos complejos para predicciones, identificación de patrones y manejan el aprendizaje basado en recompensas sin intervención humana.
Regresión lineal: un recorrido completo
La regresión lineal es un enfoque para modelar la relación que se encuentra entre una variable dependiente ‘y’ y otra o más variables independientes que se denotan como ‘x’ y se expresan en forma lineal. La palabra Lineal indica que la variable dependiente es directamente proporcional a las variables independientes. Hay que tener en cuenta otras cosas.
Tiene que ser constante como si x aumentara / disminuyera, entonces Y también cambia linealmente. Matemáticamente, la relación se basa y expresa en la forma más simple como y = Ax + B
A y B se consideran factores constantes. El objetivo oculto detrás del aprendizaje supervisado mediante la regresión lineal es encontrar el valor exacto de las constantes ‘A’ y ‘B’ con la ayuda de los conjuntos de datos. Luego, estos valores, es decir, el valor de las constantes, ayudarán a predecir los valores de ‘y’ en el futuro para cualquier valor de ‘x’. Ahora, los casos en los que hay una variable única e independiente se denomina regresión lineal simple, mientras que si existe la posibilidad de más de una variable independiente, este proceso se denomina regresión lineal múltiple.
Proyecto de demostración: predecir los precios de los alimentos mediante regresión lineal
Para comprender lo que hemos aprendido hasta ahora, intentaremos construir un modelo de aprendizaje automático para predecir los precios de las papas utilizando el algoritmo de aprendizaje supervisado, regresión lineal. Solo con fines de capacitación, nuestro conjunto de datos será bastante pequeño y simulado.
Google Colab se utilizará para este proyecto como una sustitución sin estrés para configurar nuestro entorno de codificación.
Necesitará una cuenta de Gmail para esto.
Se puede acceder al repositorio de GitHub que contiene las diapositivas, el código y los archivos de datos a través de este enlace.
Recursos para principiantes en ciencia de datos
Aquí hay una lista de recursos seleccionados para ayudar a los principiantes absolutos a aprender ciencia de datos y aprendizaje automático:
- Programa de ciencia de datos de código abierto.
- Manual de ciencia de datos de Python.
- 26 semanas del desafío de la ciencia de datos.
Este es un material didáctico preparado para llevar a los estudiantes de los clubes de estudiantes de desarrolladores de Google de KNUST y UG a través de una introducción a la ciencia de datos y ML. Creo que también puede ser igualmente útil para mis lectores que buscan comenzar a aprender ciencia de datos y ML.
Gracias por leer.





Añadir comentario