Bienvenido, me llamo Miguel y en esta ocasión les traigo este nuevo tutorial.
Índice
Guía completa sobre cómo trabajar con Protobuf en Apache Kafka
Desde la versión 5.5 de la plataforma Confluent, Avro ya no es el único esquema en la ciudad. Los esquemas Protobuf y JSON ahora son compatibles como ciudadanos de primera clase en el universo Confluent.
Pero antes de continuar explicando cómo usar Protobuf con Kafka, respondamos una pregunta frecuente …
¿Por qué necesitamos esquemas?
Cuando las aplicaciones se comunican a través de un sistema pub-sub, intercambian mensajes y esos mensajes deben ser entendidos y acordados por todos los participantes en la comunicación.
Además, le gustaría detectar y evitar cambios en el formato del mensaje que harían que los mensajes fueran ilegibles para algunos de los participantes.
Ahí es donde entra en juego un esquema: representa un contrato entre los participantes en la comunicación, al igual que una API representa un contrato entre un servicio y sus consumidores.
Y así como las API REST se pueden describir usando OpenAPI (Swagger), los mensajes en Kafka se pueden describir usando esquemas Avro, Protobuf o Avro.
Los esquemas describen la estructura de los datos mediante:
- Especificar qué campos están en el mensaje.
- Especificando el tipo de datos para cada campo y si el campo es obligatorio o no.
Además, junto con Schema Registry, los esquemas evitan que un productor envíe mensajes dudosos: datos con formato incorrecto que los consumidores no pueden interpretar.
Schema Registry detectará si el productor está a punto de introducir cambios importantes y se puede configurar para rechazar dichos cambios. Un ejemplo de un cambio importante sería eliminar un campo obligatorio del esquema.
Introducción a Protobuf
Similar a Apache Avro, Protobuf es un método para serializar datos estructurados. Un formato de mensaje se define en un .proto y puede generar código a partir de él en muchos lenguajes, incluidos Java, Python, C ++, C #, Go y Ruby.
A diferencia de Avro, Protobuf no serializa el esquema con el mensaje. Entonces, para deserializar el mensaje, necesita el esquema en el consumidor.
Aquí hay un ejemplo de un esquema de Protobuf que contiene un tipo de mensaje:
syntax = "proto3";package com.codingharbour.protobuf;message SimpleMessage { string content = 1; string date_time = 2; }
En la primera línea, definimos que estamos usando protobuf versión 3. Nuestro tipo de mensaje llamado SimpleMessage define dos campos de cadena: contenido y fecha_hora.
Google sugiere utilizar los números del 1 al 15 para los campos más utilizados porque se necesita un byte para codificarlos.
Protobuf admite tipos escalares comunes como string, int32, int64 (long), double, bool, etc. Para obtener la lista completa de todos los tipos escalares en Protobuf, consulte la documentación de Protobuf .
Además de los tipos escalares, es posible utilizar tipos de datos complejos. A continuación, vemos dos esquemas, Pedido y Producto, donde el Pedido puede contener cero, uno o más Productos:
message Order int64 order_id = 1; int64 date_time = 2; Product product = 3; message Product int32 product_id = 1; string name = 2; string description = 3; }
Ahora, veamos cómo terminan estos esquemas en el Registro de esquemas.
Registro de esquemas y Protobuf
Schema Registry es un servicio para almacenar un historial versionado de los esquemas utilizados en Kafka. También apoya la evolución de esquemas de una manera que no rompa a los productores ni a los consumidores.
Hasta hace poco, el registro de esquemas solo era compatible Esquemas avro, pero desde Confluent Platform 5.5 el soporte se ha extendido a esquemas Protobuf y JSON.
KafkaProtobufSerializer y KafkaProtobufDeserializer.El trabajo de este serializador es convertir el objeto Java a un formato binario protobuf antes de que el productor escriba el mensaje en Kafka.
El trabajo adicional del serializador es verificar si el esquema protobuf existe en el Registro de esquemas. De lo contrario, escribirá el esquema en Schema Registry y escribirá el ID de esquema en el mensaje (al principio del mensaje).
Luego, cuando el registro de Kafka llega al consumidor, el consumidor utilizará KafkaProtobufDeserializer para obtener el esquema del Registro de esquemas en función del ID de esquema del mensaje.
Una vez que se obtiene el esquema, KafkaProtobufDeserializer lo usará para deserializar el mensaje. De esta forma, el consumidor no necesita conocer el esquema de antemano para poder consumir mensajes de Kafka.
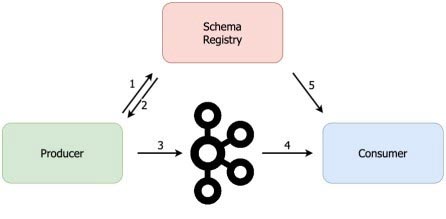
Es por eso que, cuando usamos KafkaProtobuf (De) Serializer en un productor o consumidor, necesitamos proporcionar la URL del Schema Registry.
Generación de código en Java
Bien, ahora sabemos cómo se ve un esquema protobuf y sabemos cómo termina en Schema Registry. Veamos ahora cómo usamos los esquemas protobuf de Java.
Lo primero que necesita es una biblioteca protobuf-java. En estos ejemplos, estoy usando maven, así que agreguemos la dependencia de maven:
<dependencies> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.12.2</version> </dependency> </dependencies>
Lo siguiente que debe hacer es usar el Protocolo compilador para generar código Java desde .archivos proto. Pero no vamos a invitar al compilador manualmente, usaremos un complemento de maven llamado protocol-jar-maven-plugin:
<plugin>
<groupId>com.github.os72</groupId>
<artifactId>protoc-jar-maven-plugin</artifactId>
<version>3.11.4</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>run</goal>
</goals>
<configuration>
<inputDirectories>
<include>${project.basedir}/src/main/protobuf</include>
</inputDirectories>
<outputTargets>
<outputTarget>
<type>java</type>
<addSources>main</addSources>
<outputDirectory>${project.basedir}/target/generated-sources/protobuf</outputDirectory>
</outputTarget>
</outputTargets>
</configuration>
</execution>
</executions>
</plugin>
Las clases de protobuf se generarán durante la fase de generar fuentes. El complemento buscará archivos proto en el src / main / protobuf carpeta y el código generado se creará en la carpeta target / generate-sources / protobuf.
Para generar la clase en la carpeta de destino, ejecute:
mvn clean generate-sources
Bien, ahora que tenemos nuestra clase generada, enviémosla a Kafka usando el nuevo serializador Protobuf.
Ejecución de un clúster de Kafka local
Antes de comenzar, iniciemos un clúster de Kafka local con Schema Registry, para que podamos probar nuestro código de inmediato. Ejecutaremos nuestro clúster usando docker-compose.
¿No tienes docker-compose? Cheque: cómo instalar docker-compose.
He preparado un archivo docker-compose con un Zookeeper, un corredor de Kafka y el Registro de esquemas. Puedes agarrarlo de https://github.com/codingharbour/kafka-docker-compose.
Navegue a la carpeta de un solo nodo-avro-kafka y ejecute:
docker-compose up -d
La salida debería verse similar a esto:
Starting sna-zookeeper ... done Starting sna-kafka ... done Starting sna-schema-registry ... done
Su clúster de Kafka local ya está listo para usarse. Mediante la ejecución docker-compose ps, podemos ver que el corredor de Kafka está disponible en el puerto 9092, mientras que el Registro de esquema se ejecuta en el puerto 8081.
Tome nota de eso, porque lo necesitaremos pronto.
Escribiendo un productor de Protobuf
Con el clúster de Kafka en funcionamiento, es el momento de crear un productor de Java que enviará nuestro SimpleMessage a Kafka. Primero, preparemos la configuración para Producer:
Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaProtobufSerializer.class); properties.put(KafkaProtobufSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");Producer<String, SimpleMessage> producer = new KafkaProducer<>(properties);
Tenga en cuenta que estamos usando KafkaProtobufSerializer como la clase de serializador de valor. Este es el nuevo serializador disponible en Confluent Platform desde la versión 5.5.
Funciona de manera similar a KafkaAvroSerializer: al publicar mensajes, verificará con Schema Registry si el esquema está disponible allí. Si el esquema aún no está registrado, lo escribirá en Schema Registry y luego publicará el mensaje en Kafka.
Para que esto funcione, el serializador necesita la URL del Registro de esquema y en nuestro caso, eso es http: // localhost: 8081.
A continuación, preparamos KafkaRecord, utilizando la clase SimpleMessage generada a partir del esquema protobuf:
SimpleMessage simpleMessage = SimpleMessage.newBuilder()
.setContent("Hello world")
.setDateTime(Instant.now().toString())
.build();
ProducerRecord<String, SimpleMessage> record
= new ProducerRecord<>("protobuf-topic", null, simpleMessage);
Este registro se escribirá en el tema llamado protobuf-topic. Lo último que debe hacer es escribir el registro a Kafka:
producer.send(record); producer.flush(); producer.close();
Por lo general, no llamarías enjuagar(), pero dado que nuestra aplicación se detendrá después de esto, debemos asegurarnos de que el mensaje se escriba en Kafka antes de que eso suceda.
Escribir un consumidor de Protobuf
Dijimos que el consumidor no necesita conocer el esquema de antemano para poder deserializar el mensaje, gracias a Schema Registry.
Pero tener el esquema disponible de antemano nos permite generar la clase Java a partir de él y usar la clase en nuestro código. Esto ayuda con la legibilidad del código y hace que un código se escriba fuertemente.
He aquí cómo hacerlo. Primero, generará una (s) clase (s) java como se explica en Generación de código en la sección Java. A continuación, preparamos la configuración para el consumidor de Kafka:
Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "protobuf-consumer-group"); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
Aquí definimos la URL de un corredor, el grupo de consumidores de nuestro consumidor y le decimos que manejaremos los compromisos de compensación nosotros mismos.
A continuación, definimos deserializador para los mensajes:
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaProtobufDeserializer.class); properties.put(KafkaProtobufDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081"); properties.put(KafkaProtobufDeserializerConfig.SPECIFIC_PROTOBUF_VALUE_TYPE, SimpleMessage.class.getName());
Usamos deserializador de cadenas para la clave, pero para el valor, estamos usando el nuevo KafkaProtobufDeserializer. Para el deserializador protobuf, necesitamos proporcionar la URL del registro de esquema, como hicimos para el serializador anterior.
La última línea es la más importante. Le dice al deserializador a qué clase deserializar los valores de registro. En nuestro caso, es la clase SimpleMessage (la que generamos a partir del esquema protobuf usando el complemento protobuf maven).
Ahora estamos listos para crear nuestro consumidor y suscribirlo a protobuf-topic:
KafkaConsumer<String, SimpleMessage> consumer
= new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("protobuf-topic"));
Y luego sondeamos Kafka en busca de registros y los imprimimos en la consola:
while (true)
ConsumerRecords<String, SimpleMessage> records
= consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, SimpleMessage> record : records)
System.out.println("Message content: " +
record.value().getContent());
System.out.println("Message time: " +
record.value().getDateTime());
consumer.commitAsync();
}
Aquí consumimos un lote de registros y solo imprimimos el contenido en la consola.
¿Recuerda cuando configuramos el consumidor para que nos dejara manejar la confirmación de compensaciones estableciendo ENABLE_AUTO_COMMIT_CONFIG en falso?
Eso es lo que estamos haciendo en la última línea: sólo después de que hayamos procesado completamente el grupo actual de registros confirmaremos la compensación del consumidor.
Eso es todo lo que hay que hacer para escribir un simple consumidor de protobuf. Veamos ahora una variante más.
Consumidor de Protobuf genérico
¿Qué sucede si desea manejar mensajes de forma genérica en su consumidor, sin generar una clase Java a partir de un esquema protobuf? Bueno, puede usar una instancia de la clase DynamicMessage de la biblioteca protobuf.
DynamicMessage tiene una API reflectante, por lo que puede navegar por los campos de mensajes y leer sus valores. Así es como puede hacerlo …
Primero, configuremos el consumidor. Su configuración es muy similar al ejemplo anterior:
Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "generic-protobuf-consumer-group"); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaProtobufDeserializer.class); properties.put(KafkaProtobufDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
Lo único que falta es la configuración SPECIFIC_PROTOBUF_VALUE_TYPE. Como queremos manejar los mensajes de forma genérica, no necesitamos esta configuración.
Ahora estamos listos para crear nuestro consumidor y suscribirlo a protobuf-topic tema, como en el ejemplo anterior:
KafkaConsumer<String, SimpleMessage> consumer
= new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton("protobuf-topic"));
Y luego sondeamos Kafka en busca de registros y los imprimimos en la consola:
while (true) ConsumerRecords<String, DynamicMessage> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, DynamicMessage> record : records) for (FieldDescriptor field : record.value().getAllFields().keySet()) System.out.println(field.getName() + ": " + record.value().getField(field)); consumer.commitAsync(); }
Sin SPECIFIC_PROTOBUF_VALUE_TYPE configurado en nuestro consumidor, el consumidor siempre devolverá la instancia de DynamicMessage en el valor del registro.
Entonces usamos el método DynamicMessage.getAllFields () para obtener la lista de FieldDescriptors. Una vez que tenemos todos los descriptores, simplemente podemos recorrerlos e imprimir el valor de cada campo.
Consulte JavaDoc para obtener más información sobre Mensaje dinámico.
Eso envuelve nuestra guía de Kafka Protobuf. Ahora está listo para comenzar a escribir productores y consumidores que envían mensajes de Protobuf a Apache Kafka con la ayuda de Schema Registry.
Gracias por leer este tutorial.






Añadir comentario