
Muy buenas, me llamo Miguel y hoy les traigo un nuevo post.
Índice
La importancia de las buenas prácticas de codificación no es evidente cuando el equipo es pequeño. Con el tiempo, a medida que el equipo y las aplicaciones crecen, comencé a apreciar las buenas prácticas de codificación que se deben aplicar en todo el equipo, incluso a costa de esfuerzos y tiempo adicionales.
Compartiré con ustedes cinco prácticas esenciales que, según descubrí, a menudo se pasan por alto al comenzar en un equipo pequeño y joven. El contexto será desde la perspectiva de un desarrollador de API backend y trabajará en un entorno de arquitectura de microservicio / malla.
# 1: Validar entradas y manejar errores
Cuando su aplicación se activa, puede suceder cualquier cosa: un pirata informático puede estar tratando de penetrar en su sistema o pueden ser usuarios que desencadenan un caso de uso no deseado. Debería implementar prácticas para validar las entradas que ingresan a su sistema de manera que no afecten a sus sistemas posteriores.
Puede validar las entradas de backend en dos niveles:
- Puerta de enlace API – la validación de entradas a nivel de puerta de enlace API a través de políticas; principalmente validación genérica, es decir, esquema, formato.
- Microservicio – las validaciones de nivel de microservicio implican la verificación de la existencia de entidades, etc. Hay bibliotecas, por ejemplo Validador joi, que puede aprovechar para facilitar la validación de entrada según su pila de desarrollo.
Una vez que se han validado las entradas y se han descubierto los errores, es crucial manejar los errores correctamente, especialmente en una arquitectura de microservicios / malla, donde muchos servicios están interconectados. Siempre que uno de los servicios falle, puede desencadenar fácilmente un impacto sistémico; también puede hacer que los desarrolladores se esfuercen mucho en solucionar problemas.
Utilicé una combinación de dos métodos para manejar errores y mitigar el impacto posterior:
- Cortacircuitos – Evita la invocación repetida de servicios que probablemente fallen.. Hay bibliotecas disponibles y ejemplos para NodeJS, Springcloud, etc., que puede implementar el patrón rápidamente.
- Manejar excepciones con códigos de error – devuelve una respuesta sin bloquear el servicio con un código de error comercial o HTTP para facilitar la resolución de problemas.
Puede consultar un ejemplo de la documentación de códigos de error adecuada a continuación.
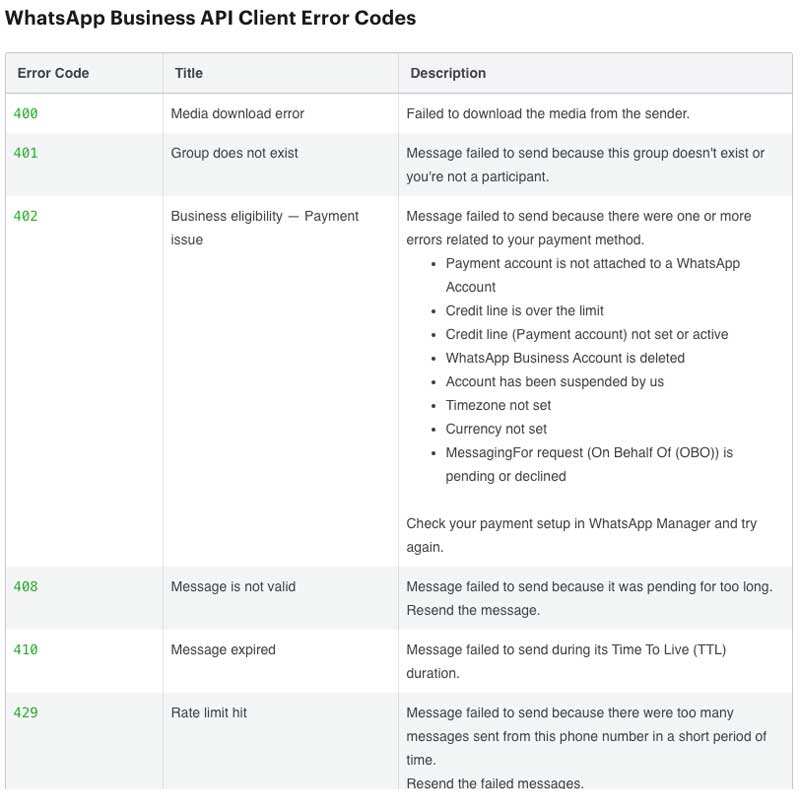
Con la validación de entradas y el manejo de errores adecuados, sus servicios se volverán más resistentes, lo que reduce la necesidad de solucionar problemas con frecuencia.
# 2: Separación de preocupaciones
La separación de preocupaciones es un elemento esencial de la arquitectura del software. Con la separación adecuada de preocupaciones, podrá mejorar la capacidad de mantenimiento de su código: son modulares; esto facilita que otros desarrolladores colaboren en la aplicación, lo que reduce la necesidad de que usted pierda tiempo innecesario para ponerlos al día.
Hay varias formas de estructurar sus códigos, p. Ej. Marco MVC. La idea es establecer un estándar de «mejores prácticas» que funcione para su equipo. Puede buscar en línea buenas referencias sobre la separación de preocupaciones y encontrar una que funcione para usted.
La implementación y el seguimiento de una arquitectura de software de «mejores prácticas» en todo su equipo reduce las barreras de entrada y la curva de aprendizaje para sus códigos, lo que se traduce en velocidad y eficiencia generales para el equipo.
#3: Implement health check endpoints and logging
Las verificaciones de estado ayudan a monitorear el tiempo de actividad de su servicio para que pueda resolver problemas rápidamente y mitigar el impacto antes de que se prolongue. Si las verificaciones de estado fallan y su servicio se interrumpe, deberá confiar en los registros para solucionar la causa raíz y resolver el problema rápidamente.
Compartiré los tres enfoques que he adoptado para esta implementación (en un nivel alto):
- Comprobaciones de estado (TCP) – Comprobaciones de estado básicas que garantizan que sus servicios estén en funcionamiento mediante ping / TCP. No es muy útil ya que no monitorea el estado del nivel de servicio. Estos servicios son disponible en la mayoría de las plataformas en la nube.
- Comprobaciones de estado (nivel de servicio) – verificaciones de estado avanzadas que invocan su servicio y validan el resultado previsto para garantizar que el servicio se esté ejecutando correctamente. Postman ofrece un monitoreo de servicios un poco más avanzado a un precio.
- Inicio sesión – registra acciones, es decir, consultas, solicitudes y respuestas de la base de datos en un sumidero de registros centralizado. Puedes ver algunos de los bibliotecas de registro y herramientas de gestión de registros allí afuera. Hay muchos artículos sobre buenas prácticas de tala que puede buscar en línea.
Tenerlos en su lugar le dará tranquilidad después de que su aplicación se active.
# 4: Implemente el control de versiones para sus servicios
El control de versiones le permite implementar y probar las actualizaciones posteriores de la aplicación mientras la versión actual aún se está ejecutando. Cuando su aplicación crece, los cambios se vuelven más frecuentes y tener un control de versiones adecuado le permite manejar esos cambios de manera eficiente.
Hay dos formas de versionar su servicio:
- URL – un ejemplo sería «/accounts/v2.1/id»
- Encabezamiento – incluido en el encabezado como «X-Version: 2.1».
Mi equipo sigue el enfoque de control de versiones de URL. Puede encontrar una ilustración de muestra a continuación.
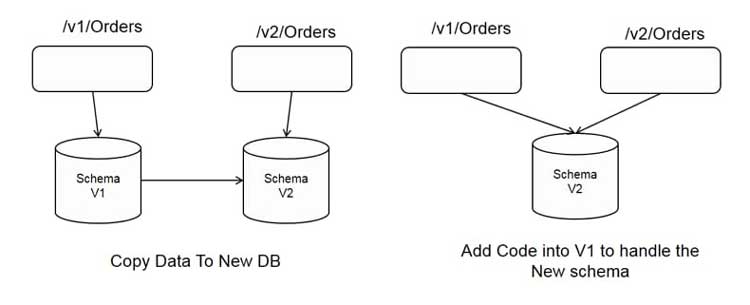
Existen pros y contras de cada opcióny depende de su equipo decidir cuál es mejor.
# 5: escribir casos de prueba y documentación
En mi experiencia, escribir casos de prueba antes del desarrollo ayuda a planificar y visualizar el producto final antes de pasar a la codificación; esto ayuda a minimizar los cambios posteriores que contribuyen a la eficiencia. Tener casos de prueba también le permitiría detectar el impacto posterior de cualquier cambio realizado en su código base, especialmente cuando se vuelve enorme.
Desarrollo impulsado por pruebas (TDD) es un enfoque popular que aboga por escribir casos de prueba antes de comenzar con el desarrollo. Mientras tiene su beneficios, también puede llevar mucho tiempo. Para los servicios críticos, se recomienda escribir un caso de prueba elaborado eventualmente. Existen marcos de prueba que puede seguir con buenos ejemplos En Internet.
No me di cuenta de la importancia de la documentación hasta que el equipo y la cantidad de aplicaciones en mi equipo crecieron. No teníamos ninguna documentación ya que estábamos produciendo software rápidamente; es principalmente una demostración de uno a dos desarrolladores. Posteriormente, el desarrollo se volvió más lento porque siempre nos acercábamos para aclarar los códigos cuando teníamos que colaborar entre proyectos. Pasamos mucho tiempo en recorridos y aclaraciones, lo que obstaculizó la productividad.
Después de probar varias formas de documentar nuestras API, hemos encontrado la Enfoque de documentación del cartero para ser el más efectivo para nosotros ya que la mayoría de nosotros usamos Postman para nuestro desarrollo de API.
Puede encontrar una muestra de la documentación de Postman a continuación.

Sobre todo, el Los principios de una buena documentación son aproximadamente los mismos. Tendrá que encontrar y adoptar un enfoque que funcione mejor para su equipo.
Conclusión
Es posible que algunos de los beneficios de estos consejos no sean evidentes cuando se comienza con un pequeño equipo de codificadores. Comencé a darme cuenta de la importancia de estas prácticas cuando mi equipo comenzó a crecer y tuve que hacer malabares con múltiples proyectos.
Es mejor comenzar temprano para incorporar estas prácticas, ya que uno de los principales desafíos que descubrí fue que los malos hábitos de codificación son más difíciles de cambiar en una etapa posterior.
Espero que te sirva. Gracias por leer.






Añadir comentario