
Bienvenido, me llamo Miguel y esta vez les traigo un artículo.
La vida de Linux no se trata solo ls y grep. Seguro, probablemente hayas usado esas herramientas para encontrar cosas rápidamente y resolver problemas simples, pero eso es solo el comienzo. La mayoría de las distribuciones de Linux tienen una gran cantidad de herramientas integradas que son fáciles de perder a primera vista. Bajo la superficie, Linux tiene algunos de los programas más específicos y concisos para lograr todo, desde la manipulación básica de texto hasta la compleja ingeniería de tráfico de red.
Si dedica tiempo a buscar en Google tutoriales o guías sobre cómo dominar Linux, se le presentará un excelente material que cubre los conceptos básicos. Aprender el conocimiento fundamental de cómo navegar en la línea de comandos usando cd y ls es imprescindible, pero hay mucho más que puede lograr sin tener que recurrir a otra herramienta o lenguaje de terceros.
Los ingenieros pueden ser demasiado rápidos para saltar a un lenguaje de programación de alto nivel cuando creen que algo no se puede lograr a través de programas y conductos enfocados. Claro, en la mayoría de los casos, cambiar a un lenguaje como Python puede ser más simple y rápido, pero hay algo que decir para lograr el mismo resultado sin él. Elimina una dependencia masiva, el lenguaje de programación, e inmediatamente obtiene una gama más amplia de compatibilidad. Es posible que no pueda garantizar que una versión de idioma en particular esté disponible en los diferentes sistemas con los que interactúa. Además, es posible que también tenga limitaciones en lo que puede instalar en estos sistemas. Aprender a trabajar con las herramientas nativas del sistema operativo que tiene es una habilidad aguda que le será de gran utilidad.
Índice
1. tc
Control de tráfico. Este es un conjunto de herramientas para manipular el tráfico de red dentro de Linux. Las cosas que puedes lograr con tc son impresionantes y nauseabundos. Esto no es para los débiles de corazón y configurar diferentes manipulaciones de tráfico no es de ninguna manera simple, pero aprenda a entenderlo y podrá aprovechar el poder de la ingeniería de tráfico dentro de Linux.
La página man7 no es exactamente fácil de usar, pero no se preocupe porque hay un desglose excelente con algunas de las formas tc que puede ser usado, disponible en Debian Wiki.
Un ejemplo común de tc el uso es aplicar un retraso de paquete a una conexión de red. Con tc puede manipular los paquetes entrantes y salientes para aplicar cosas como retrasos o incluso eliminar una cierta cantidad de ellos por completo. Echemos un vistazo a un ejemplo relativamente simple en el que aplicamos un retraso a nuestra propia conexión de red. Primero veamos cómo son nuestros pings a Google:
pi@raspberry:~ $ ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=13.6 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=10.9 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=117 time=15.5 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=117 time=13.8 ms
No está nada mal. Tenemos un buen retraso de ~ 13,5 ms entre nosotros y Google. ¿Qué pasaría si quisiéramos probar cómo funcionaría una aplicación con aún más retraso? Las aplicaciones de pruebas de estrés induciendo malas condiciones de la red es una práctica muy común e importante. Si no sabe cómo funcionará su aplicación en condiciones de red subóptimas, entonces realmente no sabe cómo funcionará para todos.
Induzcamos 100 ms de retraso con tc:
sudo tc qdisc add dev eth0 root netem delay 100ms pi@raspberry:~ $ ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=110 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=116 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=117 time=119 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=117 time=113 ms
¡Increíble! Ahora podemos ver nuestro 100ms de retraso además de nuestro retraso actual con Google. No olvide eliminar el impedimento una vez que haya terminado la prueba:
sudo tc qdisc del dev eth0 root
2. whiptail
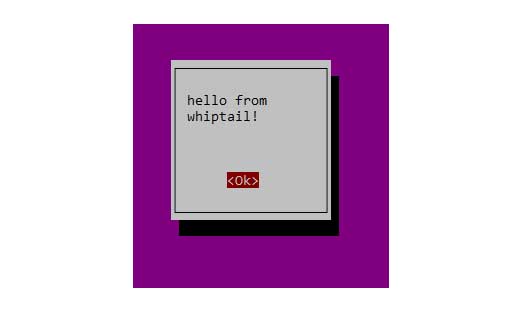
¿Siempre te has preguntado cómo se generaron esos bonitos mensajes emergentes de terminal durante las instalaciones? Con whiptail ¡por supuesto! Esta es una práctica utilidad de un solo propósito para mostrar cuadros de diálogo dentro de la terminal. Es posible que haya notado este mismo estilo utilizado durante la instalación de Ubuntu y otras instalaciones populares impulsadas por la línea de comandos.
Whiptail está ampliamente disponible y viene con la mayoría de las distribuciones para un uso rápido y fácil. Esta utilidad tiene una amplia gama de diferentes pantallas y entradas entre las que puede elegir:
- Cuadros de mensaje
- Cajas de entrada de texto
- Cuadros de entrada de contraseña
- Si o no hay opciones
- Listas de verificación
- … ¡y más!
Intentemos mostrar un simple cuadro de entrada de sí o no en la línea de comandos con whiptail:
whiptail --yesno "would you like to continue?" 10 40
Utilizando whiptail con la opción --yesno es increíblemente simple y directa. Pasas el tipo de display que deseas, el mensaje y luego el tamaño del cuadro a dibujar en la pantalla. Su salida debería verse similar a esto:

Para ver el valor de retorno de hacer clic en sí o no, puede repetir el resultado del último comando de ejecución en la consola. Si simplemente escribe echo $? entonces verás un 0 para ‘yes’ o un 1 para ‘no’. Esto se puede incorporar fácilmente en un script de shell usando un ejemplo como el siguiente:
#!/bin/bash whiptail --yesno "would you like to continue?" 10 40 RESULT=$? if [ $RESULT = 0 ]; then echo "you clicked yes" else echo "you clicked no" fi
3. shred
¿Cuándo fue la última vez que eliminó un archivo en Linux? ¿Cómo lo hiciste? ¿Uso rm y luego lo olvidó? Si había datos confidenciales en ese archivo, es posible que desee pensar dos veces antes de usar rm para ese tipo de cosas. Aquí es donde entra shred. Esta pequeña utilidad borrará un archivo de forma segura escribiendo datos aleatorios sobre el archivo varias veces.
Mediante el uso rm para eliminar un archivo, en realidad sólo está eliminando el «enlace» o la referencia al archivo que el sistema operativo conoce. Claro, el archivo desaparece y ya no puede verlo, pero los datos sin procesar aún existen en el disco duro del sistema durante un período de tiempo. Es posible recuperar dichos datos a través de algunos procesos forenses cuidadosos. Utilizando shred puede estar seguro de que los datos se eliminarán tanto como sea posible (sin incinerar la computadora, por supuesto).
Revisar la wiki en shred para obtener más detalles sobre cómo funciona.
La próxima vez que desee asegurarse de que un archivo se haya eliminado de forma segura, ejecute el siguiente comando (el -u flag elimina el archivo real, no solo lo sobrescribe):
shred -u <file>
4. split
Simple, eficaz e incluso más flexible que el comando de su lenguaje de programación de alto nivel con un nombre similar. Divida un archivo por cualquier número de características diferentes, desde el número de líneas hasta la longitud en bytes. Con split obtienes más flexibilidad que solo poder dividir cadenas o saltos de línea.
Veamos cómo podríamos dividir un archivo que contiene cuatro líneas. Digamos que queremos dividir nuestro archivo después de un cierto número de líneas; 2 en este caso. Usaremos echo para crear nuestro archivo de prueba y luego dividir se encargará del resto:
echo -e "line1nline2nline3nline4" > test_file split --lines 2 ./test_file test_file_split_cat test_file_split_aa && cat test_file_split_ab
En este caso, hemos producido dos archivos nuevos a partir de nuestro archivo de entrada original. El comando split le permite aplicar un nombre de prefijo a los archivos recién creados, que es lo que hemos hecho con el último argumento del comando. Los archivos recién divididos contienen un sufijo de aa y ab para mantener las cosas en orden.
Hay un montón de posibilidades para usos de split. Puede dividir archivos de registro grandes cuando alcancen un cierto tamaño o longitud de línea. También podrías usar split para separar las preocupaciones en los archivos de texto mediante la división en algún delimitador predefinido para mantener las cosas bien y organizadas.
5. nl
Alguna vez miró un archivo de registro o alguna otra salida de texto sin formato y pensó:
«¿No sería genial con los números de línea?»
La numeración de líneas hace que las cosas sean más fáciles de leer y mucho más simple para recordar su lugar o señalar una sección específica. De acuerdo con “la forma Linux” de hacer las cosas, existe una utilidad dedicada precisamente para este tipo de cosas. Utilizando nl literalmente puedes numerar rectas. Aceptando texto en stdin produce el mismo resultado, pero con números de línea. Échale un vistazo:
echo -e "onentwonthree" one two three echo -e "onentwonthree" | nl 1 one 2 two 3 three
Incluso puede hacer algunos pequeños ajustes en el margen de numeración y el separador si prefiere un formato diferente:
echo -e "onentwonthree" | nl -s ": " -w 1 1: one 2: two 3: three
Es fácil ver lo útil que podría ser esto con archivos más grandes que contienen cientos o incluso miles de líneas. La próxima vez que necesite algunos números de línea superpuestos, simplemente canalice a nl:
cat <file> | nl
Si te gusta usar less para ver archivos grandes también puede simplemente pasar el argumento -N al abrir el archivo para tener números de línea disponibles automáticamente. Esto evita la sobrecarga de tener que manipular el archivo sin procesar y aplicar números de línea ya que less no carga todo el archivo a la vez.
6. flock
Cerraduras. Ámalos u ódialos, en algún momento tendrás que lidiar con las cerraduras. El concepto de bloqueo es bastante simple. Si necesita realizar alguna operación en algún estado al que otros procesos podrían tener acceso, entonces su operación debería «bloquear» todas las demás acciones hasta que se complete. En ciertos casos esto se maneja automáticamente, en otros hay que establecer un sistema simple de bloqueos para asegurar que las condiciones de carrera no se presenten.
Utilizando flock puede generar diferentes tipos de bloqueos que se pueden obtener durante operaciones concurrentes. El bloqueo en sí mismo es realmente un archivo en Linux. Echemos un vistazo a cómo podríamos usar un bloqueo para evitar que varios procesos interactúen con un archivo:
LOCKFILE=/tmp/lockfile
already_locked() {
echo "lock is already held, exiting"
exit 1
}
exec 200>$LOCKFILE
flock -n 200 || already_locked
echo "lock obtained, proceeding"
sleep 10
echo "releasing lock, done"
Si ejecuta este script de shell, intentará obtener un bloqueo para el archivo /tmp/lockfile asignándole el descriptor de archivo 200 y luego utilizando un tipo de bloqueo «sin bloqueo». Cuando utiliza este tipo de estilo de bloqueo, si el bloqueo ya se ha obtenido, todos los demás intentos de obtenerlo fallarán en lugar de esperarlo.
Intente ejecutar el script (que duerme durante 10 segundos) en una ventana y luego en otra ventana, intente ejecutar una segunda instancia. A tener en cuenta:rá que la primera ejecución obtiene el bloqueo y la segunda falla porque el bloqueo ya se obtuvo. Con este ejemplo podrías reemplazar el simple sleep comando con un conjunto de comandos de procesamiento de datos de larga duración o actualizaciones de archivos que desea proteger.
¡Gracias por leer! Espero que te haya parecido interesante.





Añadir comentario