Hola, me llamo Luis y para hoy les traigo este nuevo tutorial.
Kafka tiene una serie de diferencias fundamentales con los sistemas de mensajería tradicionales que hacen. Se ejecuta como un clúster y puede escalar para manejar todas las aplicaciones en incluso las empresas más masivas.
Antes de echar un vistazo a las partes iniciales del sistema Kafka, hablemos de la publicar / suscribir concepto de mensajería.
La mensajería es un patrón que se caracteriza porque el remitente (editor) de un dato (mensaje) no lo dirige específicamente a un receptor. En cambio, el editor clasifica el mensaje de alguna manera y ese receptor (suscriptor) se suscribe para recibir ciertas clases de mensajes.
Los sistemas de publicación / suscripción suelen tener un intermediario, un punto central donde se publican los mensajes, para facilitar esto.
La necesidad de tener un sistema de suscripción de mensajería distribuida en lugar de utilizar una conexión punto a punto y un trabajo duplicado para manejar todos los eventos provenientes de diferentes partes de los sistemas de la Organización, hizo de Kafka un gran enfoque para manejar los datos masivos producidos desde cada solicitud.
Índice
La unidad de datos:
La unidad de datos dentro de Kafka se llama mensaje, Un mensaje es simplemente una matriz de bytes. Un mensaje puede tener un bit opcional de metadatos, que se conoce como un llave.
La clave también es una matriz de bytes y, al igual que con el mensaje, las claves se utilizan cuando los mensajes deben escribirse en particiones de una manera más controlada.
El esquema más simple de este tipo es generar una hash de la clave y luego seleccione el número de partición para ese mensaje tomando el resultado del hash.
Por eficiencia, mensajes están escritos en Kafka en lotes. Un lote es solo una colección de mensajes, todos los cuales se producen al mismo tema y dividir.
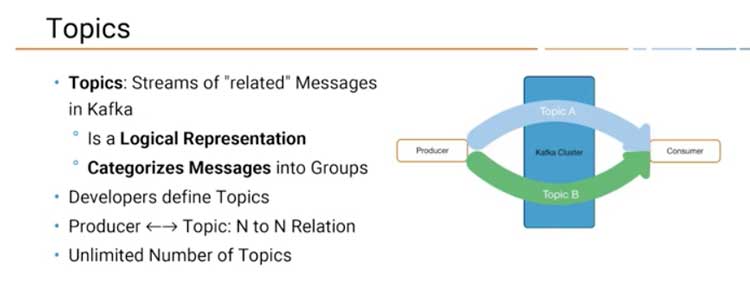
Temas y particiones
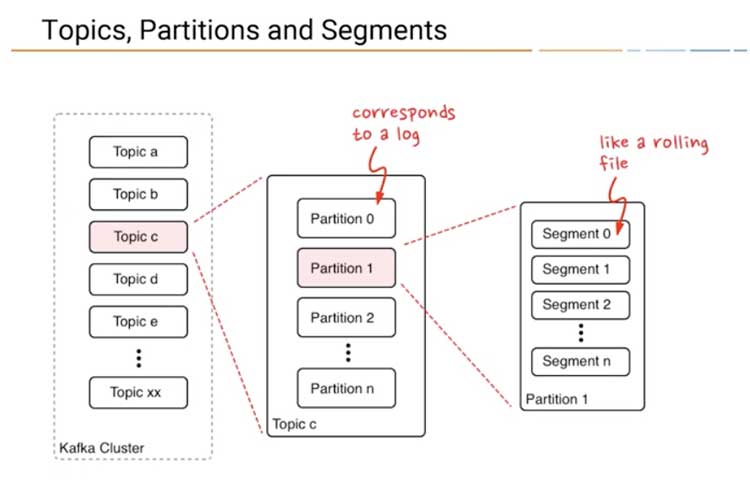
Los mensajes en Kafka se clasifican en temas, Los temas también se dividen en varios particiones.
- Una
particiones un solo registro. Los mensajes se escriben en él de forma de solo anexión y se leen en orden de principio a fin. - Las
particionesson también la forma en que Kafka proporciona redundancia y escalabilidad. - Cada
particiónse puede alojar en un servidor diferente, lo que significa que un solo tema se puede escalar horizontalmente en varios servidores. - Una
particiónes un grupo desegmentos. - Un
segmento: es un archivo individual en el disco delBroker.
- Una
secuencia: un solo tema de datos, independientemente del número de particiones.
Partes del sistema Kafka
Las aplicaciones y sistemas que producen o envían datos a Kafka, recibirán la señal "ack" o "nack" del sistema kafka.
Al productor no le importa en qué partición se escribe un mensaje específico y equilibrará los mensajes en todas las particiones de un tema de manera uniforme.

«Ack»: reconocido; el sistema kafka pudo recibir los datos.
«Nack»: reconocimiento negativo; el sistema kafka no pudo recibir los datos por alguna razón, la mayoría de los productores intentarán reenviar los datos nuevamente.
Leer mensajes.
El consumidor se suscribe a uno o más temas y lee los mensajes en el orden en que fueron producidos. El consumidor realiza un seguimiento de los mensajes que ya ha consumido al realizar un seguimiento del desplazamiento de mensajes.
Desplazamiento: un valor entero que aumenta continuamente, que Kafka agrega a cada mensaje a medida que se produce.
Los Consumidores trabajan como parte de un grupo de consumidores, que es uno o más consumidores que trabajan juntos para consumir un tema.
El grupo asegura que cada partición solo sea consumida por un miembro.

Un solo servidor Kafka se llama corredor. El corredor recibe mensajes de productores, asigna compensaciones a ellos, y envía los mensajes al almacenamiento en disco.
consumidores, respondiendo a las solicitudes de recuperación de particiones y responder con los mensajes que se han enviado al disco.Kafka corredores están diseñados para funcionar como parte de un clúster. Dentro un clúster de corredores, un corredor también funcionará como el controlador de clúster (elegido automáticamente entre los miembros activos del clúster).
El controlador es responsable de las operaciones administrativas, incluida la asignación de particiones a los intermediarios y la supervisión de las fallas de los intermediarios.

Una partición es propiedad de un solo corredor en el racimo, y ese corredor se llama líder de la partición. Se puede asignar una partición a varios intermediarios, lo que dará como resultado que la partición se replique.
Consumidores y Productores están desacoplados, lo que significa que los consumidores lentos no impactan a los productores, agregando más o las fallas de los consumidores sin impacto de los productores.
Por qué Kafka
Kafka puede manejar sin problemas varios productores, por lo que Kafka puede agregar datos de muchos sistemas frontend y hacerlos consistentes.
Kafka está diseñado para que varios consumidores lean cualquier flujo de mensajes sin interferir entre sí.
Los mensajes se envían al disco y se almacenan con configurables reglas de retención. Estas opciones se pueden seleccionar por tema, lo que permite que diferentes flujos de mensajes tengan diferentes cantidades de retención según las necesidades del consumidor.
La escalabilidad flexible de Kafka facilita el manejo de cualquier cantidad de datos. Las expansiones se pueden realizar mientras el clúster está en línea, sin impacto en la disponibilidad del sistema en su conjunto.
Esto también significa que un grupo de varios corredores puede manejar la falla de un corredor individual y seguir atendiendo a los clientes.
Gracias por leer este tutorial.






Añadir comentario