
Hola, soy Luis y para hoy les traigo otro nuevo post.
Índice
Diferentes tipos de pruebas
A lo largo de los años, hemos agregado muchas funciones nuevas. Y con cada nueva característica, la cantidad de pruebas también creció. En nuestra aplicación más grande, tenemos más de 30 mil pruebas de diferentes tipos:
- Pruebas unitarias (27,687x): este es el grupo más grande de pruebas que tenemos. Ellos prueban una sola unidad de nuestra base de código y no depende de servicios externos como una base de datos.
- Pruebas de integración (5,348x): en nuestras pruebas de integración probamos juntas partes más grandes del sistema. Las pruebas utilizan MySQL, Redis, RabbitMQ y Elasticsearch para asegurarse de que todo funcione y esté configurado correctamente.
- Pruebas sin cabeza (39x): estas pruebas confirman que el flujo de extremo a extremo funciona como se esperaba. Ponemos en marcha tres servidores: uno que sirve a la aplicación Mollie, otro que se burla de nuestros proveedores y otro que actúa como uno de nuestros clientes. También utilizamos un navegador Chromium sin cabeza para imitar al consumidor que completa una transacción. Luego verificamos que se realicen las llamadas correctas a proveedores, que llamemos correctamente a los webhooks a nuestros clientes, y muchas cosas más.
- Otras pruebas: también tenemos algunas pruebas más específicas para subsistemas más pequeños con herramientas específicas. Por ejemplo, probamos que nuestros activos frontend estén construidos correctamente y verificamos que nuestras imágenes SVG no contengan ningún código malicioso.

Por cada confirmación que enviamos a nuestro repositorio de Git, ejecutamos todas las pruebas en nuestra instancia de GitLab autohospedada. No solo para master, sino también en nuestras sucursales. Esto les da a nuestros desarrolladores de software comentarios inmediatos. Para que el ciclo de retroalimentación sea útil, siempre hemos intentado ejecutar todas las pruebas en menos de 5 minutos. A lo largo de los años, tuvimos que seguir mejorando nuestros canales de prueba para lograr este objetivo de 5 minutos. Usamos las siguientes técnicas para acelerar las cosas:
Paratest
Usamos el brianium / paratest herramienta para ejecutar nuestras pruebas PHPUnit en paralelo. Paratest es una extensión sobre PhpUnit que agrega soporte para pruebas paralelas. Para nuestras pruebas unitarias, simplemente podríamos agregar Paratest y ¡funciona sin ninguna configuración!
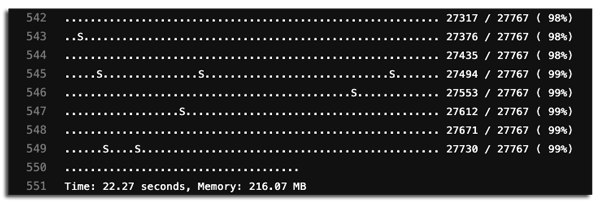
Debido a que nuestras pruebas de integración utilizan servicios externos, también tuvimos que duplicar estos servicios si queremos utilizar Paratest. Para MySQL y Redis usamos bases de datos separadas en el mismo servidor. Decidimos burlarnos del servicio RabbitMQ por completo, y con nuestro uso de Elasticsearch no fue un problema ejecutar múltiples pruebas en el mismo servidor al mismo tiempo.
Ejecutar las pruebas en paralelo realmente acelera sus pruebas, pero ahora configurar una base de datos limpia para cada hilo paralelo se estaba convirtiendo en un cuello de botella. Entonces, en lugar de crear todas las bases de datos desde cero ejecutando las migraciones de la base de datos, simplemente las ejecutamos una vez y usamos algo de bash foodoo para mysqldump en las otras bases de datos en paralelo también.
Aprendimos por las malas que tenemos que esperar explícitamente a que finalicen las importaciones de mysql. En el pasado, algunas pruebas fallaban al azar, porque no todas las tablas existían al comienzo de la suite de pruebas. Esto solo sucedió cuando los corredores de la tubería estaban ocupados, lo que provocó que las importaciones tomaran más tiempo de lo habitual.
Tuberías paralelas
Otra forma de ejecutar pruebas en paralelo es mediante el uso de pasos de canalización paralelos totalmente independientes. Cada tipo de prueba se ejecuta en su propio paso. Y nuestras pruebas de integración incluso se dividen en dos pasos separados. Creamos un corredor de Paratest personalizado que solo ejecuta 1 / Nth de las pruebas. Utilizando la parallel propiedad en .gitlab-ci.yml podemos especificar en cuántos pasos queremos dividir las pruebas.

parallel: 2 a nuestra configuración de canalización de GitLab ahora es suficiente para dividir las pruebas en varios pasos. Y podemos aumentar este número aún más a costa de más recursos.Transacciones MySQL
Ejecutamos todas nuestras pruebas de integración dentro de una transacción de base de datos. Esto nos permite revertir cualquier cambio realizado por las pruebas. Solo ejecutamos la consulta SQL BEGIN antes de comenzar una prueba y ejecutar ROLLBACK al final. Esto es mucho más rápido que correr TRUNCATE en todas las mesas que cambiaron.
Compruebe si hay pruebas lentas
Usamos un oyente PHPUnit de código abierto johnkary / phpunit-speedtrap que da como resultado cuál de las pruebas toma más tiempo que un umbral especificado. Es muy fácil de instalar y configurar. Nuestra salida se ve así:
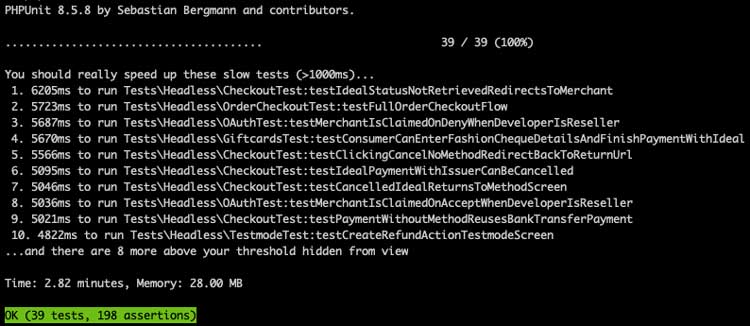
Cuando sepa qué pruebas son lentas, puede investigar cómo hacerlas más rápidas. Tal vez esté realizando solicitudes a servicios externos, o tal vez haya un sleep() método que necesita para burlarse.
Especificaciones del corredor de GitLab
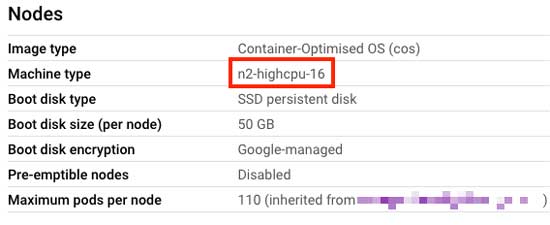
Debido a que alojamos nuestro propio GitLab en Google Cloud, tenemos la libertad de dar a los ejecutores de la canalización las especificaciones que queremos. Solíamos tener instancias del tipo n2-standard-16 para nuestros corredores (16 vCPU y 64 GB de ram), pero nos dimos cuenta de que para las pruebas solo necesitábamos las CPU. Cambiamos a instancias del n2-highcpu-16 type, que tiene 16 vCPU y solo 16 GB de RAM. Esto nos ahorró bastante dinero sin ralentizar las tuberías en absoluto. Con el escalado automático, intentamos tener siempre corredores disponibles para recoger nuevas canalizaciones, sin tener muchos recursos sin utilizar.
Almacenamiento en caché entre tuberías
Una forma sencilla de acelerar sus canalizaciones es utilizar el almacenamiento en caché siempre que sea posible. Guardamos nuestro vendor/ y node_modules/ directorios para nuestras dependencias PHP y Node, respectivamente.
En la rama maestra usamos la política de caché "pull-push" por lo que las nuevas dependencias también se envían al caché. Para las sucursales utilizamos la política de caché "pull" para evitar agregar dependencias a la caché que aún no están fusionadas con el maestro. La desventaja es que las nuevas dependencias siempre se descargarán cuando la canalización se ejecute en una rama, pero no agregamos nuevas dependencias con tanta frecuencia. El uso de una caché dedicada por rama ralentizaría todas las primeras canalizaciones para una nueva rama, y el almacenamiento en caché, por ejemplo, el directorio de caché de Composer ralentizaría todas las ejecuciones en master.
Cuando use cachés, no olvide que estos cachés también deben descargarse en el corredor. A veces es más rápido construir algo rápidamente que usar un caché.
Integre la ejecución de pruebas localmente con su IDE
Aunque las pruebas se ejecutan más rápido en las canalizaciones de CI, poder ejecutar solo un par de pruebas localmente puede ahorrar mucho tiempo. La mayoría de nuestros desarrolladores usan PhpStorm y la integración con PHPUnit y xDebug funciona de inmediato. Esto también ayuda a ahorrar recursos para otras canalizaciones.
Conclusión
Una de las mejores prácticas definidas por la programación extrema (XP) es mantener la compilación y las pruebas en menos de 10 minutos. Martin Fowler escribe:
«Vale la pena poner un esfuerzo concentrado para que esto suceda, porque cada minuto que reduce el tiempo de compilación es un minuto ahorrado para cada desarrollador cada vez que se compromete».
Espero que este artículo te haya dado algunas buenas sugerencias sobre cómo acelerar tu compilación.






Añadir comentario