
Muy buenas, me llamo Miguel y en esta ocasión les traigo otro tutorial.
Índice
Limpiar y transformar datos sin procesar en un formato ingerible usando Python
En este artículo, aprenderá a trabajar con archivos Excel / CSV en un entorno Python para limpiar y transformar datos sin procesar en un formato más ingerible. Esto suele ser útil para integración de datos.
Este ejemplo tocará muchas operaciones ETL comunes, como filtrar, reducir, explotar y aplanar.
Notas
El código de estos ejemplos está disponible públicamente en GitHub. aquí, junto con descripciones que reflejan la información que le explicaré.
Estas muestras se basan en dos paquetes Python de código abierto:
- pandas: una herramienta de manipulación y análisis de datos de código abierto ampliamente utilizada. Más información sobre su sitio y PyPi.
- gluestick: un pequeño paquete Python de código abierto que contiene funciones útiles para ETL mantenidas por pegamento caliente equipo. Más información sobre PyPi y GitHub.
Sin más preámbulos, ¡sumerjámonos!
Introducción
Este ejemplo aprovecha los datos de muestra de Quickbooks del entorno de Quickbooks Sandbox y se creó inicialmente en un pegamento caliente medio ambiente: una herramienta de integración de datos liviana para empresas emergentes.
Paso 1: lee los datos
Comencemos leyendo los datos.
Este ejemplo se basa en un entorno de hotglue con datos procedentes de Quickbooks. En hotglue, los datos se colocan en el local sync-output carpeta en formato CSV. Usaremos el barra de pegamento paquete para leer los datos sin procesar en la carpeta de entrada en un diccionario de marcos de datos pandas usando el read_csv_folder función.
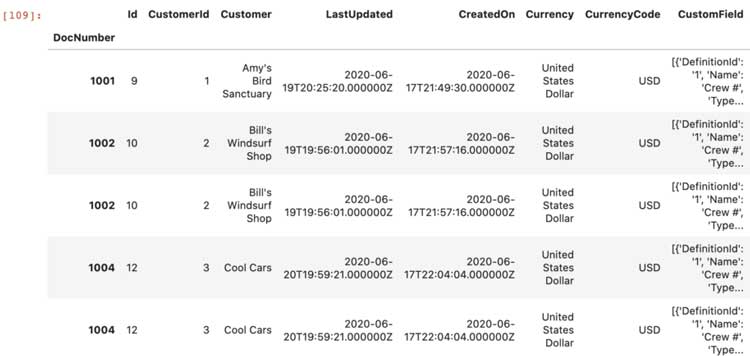
Especificando index_cols='Invoice': 'DocNumber' los Invoices el marco de datos utilizará el DocNumber columna como índice. Al especificar convertidores, podemos usar ast para analizar los datos JSON en las columnas Line y CustomField.
Echar un vistazo
Echemos un vistazo a los datos con los que estamos trabajando. Para simplificar, seleccioné las columnas con las que me gustaría trabajar y las guardé en input_df. Por lo general, en hotglue puede configurar esto usando un mapa de campo, pero lo he hecho manualmente aquí.

Paso 2: cambiar el nombre de las columnas
Limpiemos los datos cambiando el nombre de las columnas a nombres más legibles.
CustomerRef__value -> CustomerId CustomerRef__name -> Customer MetaData_LastUpdatedTime -> LastUpdated MetaData_CreateTime -> CreatedOn CurrencyRef__name -> Currency CurrencyRef__value -> CurrencyCode

Paso 3: extraer información
La Line column es en realidad un objeto JSON serializado proporcionado por Quickbooks con varios elementos útiles en él. Tendremos que empezar por aplanar el JSON y luego expandirlo en columnas únicas para que podamos trabajar con los datos.
Nuevamente, usaremos el barra de pegamento paquete para lograr esto. los explode_json_to_rows La función maneja el aplanamiento y la explosión en un solo paso. Para evitar explotar demasiados niveles de este objeto, especificaremos max_level=1
Aquí hay un fragmento de uno para darle una idea.
[{
'Id': '1',
'LineNum': '1',
'Amount': 275.0,
'DetailType': 'SalesItemLineDetail',
'SalesItemLineDetail': {
'ItemRef': {
'value': '5',
'name': 'Rock Fountain'
},
'ItemAccountRef': {
'value': '79',
'name': 'Sales of Product Income'
},
'TaxCodeRef': {
'value': 'TAX',
'name': None
}
},
'SubTotalLineDetail': None,
'DiscountLineDetail': None
}]

Paso 4: filtrar filas
Para nuestros propósitos, solo queremos trabajar con filas con un Line.DetailType de SalesItemLineDetail (no necesitamos líneas de subtotales). Esta es una operación ETL común conocida como filtración y se logra fácilmente con pandas.
Paso 5: más explosión
Mire algunas de las entradas del Line columna explotamos. A tener en cuenta:rá que son pares de nombre y valor en JSON.

Usemos Gluestick de nuevo para explotarlos en nuevas columnas a través del json_tuple_to_cols función. Necesitaremos especificar lookup_keys – en nuestro caso, el key_prop=name y value_prop=value

Paso 6: un poco más de explosión
Eche un vistazo al CustomField columna. A continuación se muestra un ejemplo de una entrada

['DefinitionId': '1', 'Name': 'Crew #', 'Type': 'StringType', 'StringValue': '102']
Puede ver que se trata de datos codificados en JSON, especificando un campo personalizado: Crew # con valor 102
Para explotar esto, necesitaremos reducir esto ya que solo nos preocupamos por el Name y StringValue. Podemos usar pegamento explode_json_to_cols funcionar con un array_to_dict_reducer para lograr esto.

Conclusión
Nuestros datos finales se parecen a los siguientes. En esta muestra, pasamos por varias operaciones ETL básicas usando un ejemplo del mundo real, todo con herramientas básicas de Python.
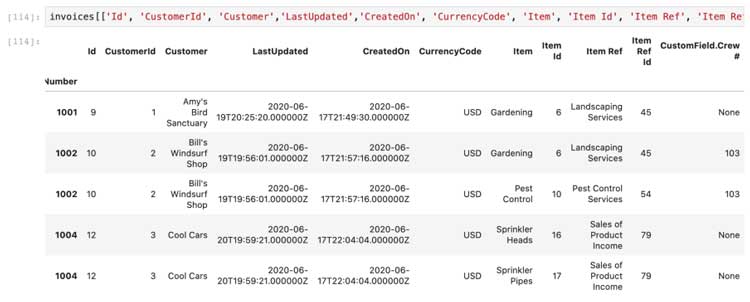
No dude en consultar el código abierto recetas de hotglue para obtener más muestras en el futuro.
Gracias por leer.






Añadir comentario