
Bienvenido, les saluda Miguel y hoy les traigo este post.
Antes de profundizar en los detalles, debemos comprender cómo representamos los datos.
Índice
Libro
Las publicaciones sobre “Planificación y actuación automatizadas” aquí están basadas en el libro con el mismo título de Malik Ghallab, Danau Nau y Paolo Traverso.
Dominio de planificación
En la publicación anterior, discutimos sobre modelos descriptivos de acciones que describen los estados que pueden suceder como resultado de la realización de acciones.
Los modelos a menudo se llaman Dominio de planificación o Sistema de transición de estado (piense en la máquina de estados finitos).
Un dominio de planificación es una tupla de 4:
Σ = (S, A, γ, costo)
Dónde:
S: un conjunto de estados
A: un conjunto de acciones
γ: función de transición de estado o función de predicción
costo: el costo de realizar una acción
Para la función de transición de estado, podemos escribir de la siguiente forma:
γ (s₀, a) = s₁
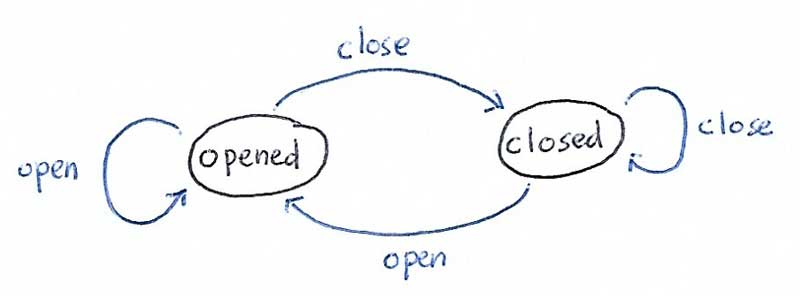
Ejemplo
Un ejemplo es un sistema de puerta simple.
S = {abierto, cerrado}
A = {abrir, cerrar}
Hay 4 funciones de transición:
γ (abierto, abrir) = abierto
γ (abierto, cerrar) = cerrado
γ (cerrado, abrir) = abierto
γ (cerrado, cerrar) = cerrado
Para este ejemplo simple, supongamos que el costo es uniforme, 1.
Objetos y variables de estado
Para comprender las variables de estado, comenzamos con el significado del estado en nuestro modelo.
Estado es una descripción de las propiedades de varios objetos en el entorno – Planificación y actuación automatizadas
Eso significa que si tenemos varios objetos en el entorno, tendremos un estado único si cambia una de las propiedades del objeto.
Hay dos tipos diferentes de propiedad:
- Rígido
Si sigue siendo el mismo en diferentes estados, por ejemplo, la adyacencia de habitaciones en un plano de planta - Variado
Si puede diferir en un estado y en otro
Variable de estado
La variable de estado se representa como x = sv (b₁,…, bᴋ), donde:
- sv: nombre de la variable de estado
- b: nombre del objeto
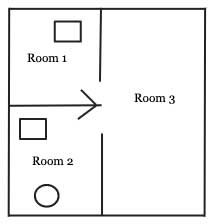
Veamos un ejemplo. En nuestro plano de planta a continuación, tenemos 3 objetos:
- robot (círculo)
- objetos (rectángulo)
- habitaciones

Las relaciones rígidas se pueden representar como:
Adjacent = [(Room1, Room2), (Room1, Room3), (Room2, Room1), (Room2, Room3), (Room3, Room1), (Room3, Room2)]
Esto no cambiará porque son rígidos.
Las variables de estado se pueden representar de la siguiente manera (supongamos que el rectángulo en la Habitación 1 es el objeto 1):
location(robot) = Room2 location(object1) = Room1 location(object2) = Room2 occupied(Room1) = True occupied(Room2) = True occupied(Room3) = False
Entonces, el estado actual de nuestro mundo es:
current_state = [location(robot) = Room2, location(object1) = Room1, location(object2) = Room2, occupied(Room1) = True, occupied(Room2) = True, occupied(Room3) = False]
Si una de las variables de estado en estado actual cambios, es otro estado.
El fragmento de código es solo para ilustración, cuando codificamos es mejor crear una clase para representar el «mundo».
Acciones y plantillas de acciones
La siguiente parte de nuestro dominio de planificación es la acción. La acción es una parte importante del modelo de dominio porque este es el componente donde predecimos cuál será el próximo estado.
La acción tiene tres partes:
- parámetros de entrada
- condiciones previas
- efectos
La plantilla de acción es un formulario genérico, la acción es una instancia de la plantilla de acción.
La plantilla de acción está escrita en el siguiente formato:
action(*params): cost = 1 if preconditions(current_state): return effects(), cost else: return current_state, cost
Si preconditions () devuelve verdadero, los efectos de la acción se devuelven. De lo contrario, esta acción no es aplicable en el estado actual del mundo / medio ambiente.
Veamos un ejemplo. En Ejemplo 1 arriba podemos agregar una acción, llamémosla mover.
move(from, to): cost = 1 if preconditions(current_state, from, to): return effects(), cost else: return current_state, cost
Ahora, las condiciones previas:
preconditions(current_state, from, to): if current_state.door(from, to) == OPENED: return True else: return False
Los efectos:
effects(current_state, from, to): predicted_state = current_state predicted_state.location(robot, to) return predicted_state
Podemos ver en el ejemplo anterior cómo funciona la acción y la plantilla de acción, el estado predicho contendrá la ubicación del robot en la nueva habitación. Si la puerta no se abre, la acción no es aplicable.

Planes y problemas de planificación
La parte final son los planes y problemas de planificación.
Plan
La definición de plan es:
Una secuencia finita de acciones
plan = [action1, action2, action3]
En este ejemplo, la duración del plan es 3 y el costo es el costo total de todas las acciones.
plan_cost = 0 for action in plan: plan_cost = plan_cost + action.cost
Problema de planificación
El problema de planificación es la tupla de dominio de planificación, estado inicial y estado objetivo (deseado).
Problema de planificación es el problema que queremos resolver, el plan resuelve el problema de planificación.
planning_problem = PlanningProblem(planning_domain, initial_state, goal_state)
Recuerde que Planning Domain es nuestra tupla de:
- estados
- comportamiento
- funciones de transición de estado
- costo
Ahora que tenemos la comprensión completa de la representación, veamos un ejemplo.
Este es el estado inicial,
Este es nuestro estado objetivo,

Agregamos 3 acciones más:
grab(object) carry(object, from, to) place(object)
Entonces, podemos crear el plan de la siguiente manera para resolver este problema de planificación:
plan = [move(room2, room3), move(room3, room1), grab(object1), carry(object1, room1, room3), place(object1)]
Nosotros decimos eso plan es el solución para nuestro problema de planificación.
Por supuesto, este es un ejemplo simplificado en el que solo hay un actor, nuestro robot, y se supone que el mundo es estático.






Añadir comentario