Bienvenido, soy Miguel y aquí les traigo un nuevo post.
Índice
Algunos de los trucos de Pandas más útiles
Pandas es una biblioteca asombrosa que contiene amplias funciones integradas para manipular datos. Entre ellos, transform() es muy útil cuando buscas manipular filas o columnas.
En este artículo, cubriremos las siguientes características transform() de Pandas más utilizadas :
1. Transformando valores
Echemos un vistazo a pd.transform(func, axis=0)
- El primer argumento
funces especificar la función que se utilizará para manipular datos. Puede ser una función, un nombre de función de cadena, una lista de funciones o un diccionario de etiquetas de eje->funciones - El segundo argumento eje es especificar en qué eje
funces aplicado a.0para aplicar elfunca cada columna y1para aplicar elfunca cada fila.
Veamos cómo transform() funciona con la ayuda de algunos ejemplos.
Podemos pasar una función a func. Por ejemplo.
df = pd.DataFrame('A': [1,2,3], 'B': [10,20,30] )def plus_10(x):
return x+10df.transform(plus_10)

También puede utilizar una expresión lambda. A continuación se muestra el equivalente lambda para el plus_10() :
df.transform(lambda x: x+10)
Podemos pasar cualquier función de cadena de Pandas válida a func, por ejemplo 'sqrt':
df.transform('sqrt')
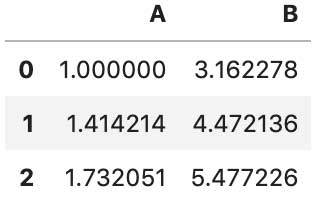
func puede ser una lista de funciones. Por ejemplo, sqrt y exp desde NumPy:
df.transform([np.sqrt, np.exp])

func puede ser un dictado de etiquetas de eje -> función. Por ejemplo.
df.transform( 'A': np.sqrt, 'B': np.exp, )

2. Combinar groupby()resultados
Uno de los usos más atractivos de Pandas, transform() está combinando resultados grouby().
Veamos cómo funciona esto con la ayuda de un ejemplo. Supongamos que tenemos un conjunto de datos sobre una cadena de restaurantes.
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})
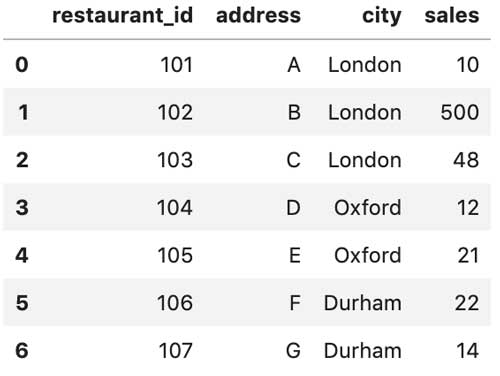
Podemos ver que cada ciudad tiene varios restaurantes con rebajas. Nos gustaría saber “Cuál es el porcentaje de ventas que representa cada restaurante en la ciudad” . El resultado esperado es:

La parte complicada de este cálculo es que necesitamos obtener un city_total_sales y volver a combinarlo con los datos para obtener el porcentaje.
Hay 2 soluciones:
groupby(),apply()ymerge()groupby()ytransform()
La primera solución es dividir los datos con groupby() y usando apply() para agregar cada grupo, luego fusionar los resultados en el DataFrame original usando merge()
Paso 1: utilizar groupby() y apply() para calcular las city_total_sales
city_sales = df.groupby('city')['sales']
.apply(sum).rename('city_total_sales').reset_index()

Groupby('city') divida los datos agrupándolos en la columna de la ciudad. Para cada uno de estos grupos, la función sum se aplica a la ventas columna para calcular la suma de cada grupo.
Finalmente, la nueva columna cambia de nombre a city_total_sales y el índice se restablece (A tener en cuenta: reset_inde() es necesario para borrar el índice generado porgroupby('city')).
Además, Pandas tiene una función sum() y lo siguiente sum() equivalente de Pandas:
city_sales = df.groupby('city')['sales']
.sum().rename('city_total_sales').reset_index()
Paso 2: utilizar merge() función para combinar los resultados
df_new = pd.merge(df, city_sales, how='left')

Los resultados del grupo se fusionan nuevamente en el DataFrame original usando merge() con how='left' para unión externa izquierda.
Paso 3: calcula el porcentaje
Finalmente, el porcentaje se puede calcular y formatear.
df_new['pct'] = df_new['sales'] / df_new['city_total_sales'] df_new['pct'] = df_new['pct'].apply(lambda x: format(x, '.2%'))

Esto ciertamente hace nuestro trabajo. Pero es un proceso de varios pasos y requiere código adicional para obtener los datos en la forma que necesitamos.
Podemos resolver esto de manera efectiva usando la función transform().
Esta solución es un cambio de juego. Una sola línea de código puede resolver la aplicación y la combinación.
Paso 1: utilizar groupby() y transform() para calcular las city_total_sales
La función de transformación retiene el mismo número de elementos que el conjunto de datos original después de realizar la transformación.
Por lo tanto, un paso de una línea usando groupby seguido de un transform(sum) devuelve la misma salida.
df['city_total_sales'] = df.groupby('city')['sales']
.transform('sum')

Paso 2: calcula el porcentaje
Finalmente, este es el mismo que el de la solución para obtener el porcentaje.
df['pct'] = df['sales'] / df['city_total_sales'] df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
3. Filtrado de datos
transform() también se puede utilizar para filtrar datos. Aquí estamos tratando de obtener registros donde las ventas totales de la ciudad sean superiores a 40.
df[df.groupby('city')['sales'].transform('sum') > 40]

4. Manejo de valores perdidos a nivel de grupo
Otro uso de Pandas transform() es manejar los valores perdidos a nivel de grupo. Veamos cómo funciona esto con un ejemplo.
Aquí hay un DataFrame para demostración.
df = pd.DataFrame({
'name': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'value': [1, np.nan, np.nan, 2, 8, 2, np.nan, 3]
})

En el ejemplo anterior, los datos se pueden dividir en tres grupos por nombre, y cada grupo tiene valores faltantes. Una solución común para reemplazar los valores perdidos es reemplazar NaN con la media.
Echemos un vistazo al valor medio de cada grupo.
df.groupby('name')['value'].mean()
name
A 1.0
B 5.0
C 2.5
Name: value, dtype: float64
Aquí podemos usar transform() para reemplazar los valores perdidos con el valor promedio del grupo.
df['value'] = df.groupby('name')
.transform(lambda x: x.fillna(x.mean()))

Espero que te haya sido de utilidad. Gracias por leer este artículo.





hola, tienes errores de sintáxis, revisalo por favor