
Bienvenido, me llamo Luis y hoy les traigo un artículo.
Índice
Manejo de errores y flujos de trabajo recursivos
Si aún no lo ha hecho, comience su viaje con la historia original de Trucos de función de paso de AWS para comenzar con algunos de los trucos básicos que puede hacer.
En este artículo, cubriremos cómo:
- Maneje los errores de una manera más concisa, manteniendo limpios nuestros flujos de trabajo
- Cree flujos de trabajo recursivos para trabajos secuenciales basados en fechas
Manejo de errores
Por tanto, en la mayoría de los estados de AWS Step Functions puede especificar un Catch sección para permitirle manejar errores. Por lo general, desea notificarse a sí mismo y a su equipo en caso de que ocurra algo inesperadamente durante su flujo de trabajo: los trabajos por lotes fallan, EMR Cluster muere, el contenedor Docker no se inicia, errores Lambda, etc., etc. Como tal, su flujo de trabajo puede verse así (trivial ) ejemplo donde para cada paso Hello, World, Foo, Bar está detectando los errores y notificándose antes de fallar el flujo de trabajo.
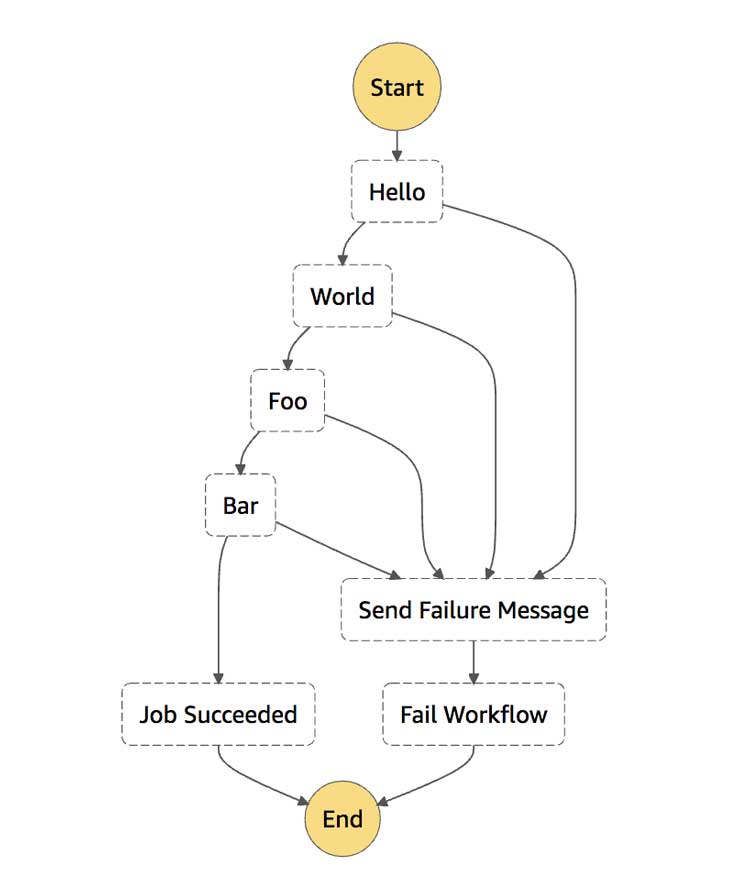
Como puede ver, esto se vuelve un poco más horrible con cada paso que tiene que agregar a este flujo de trabajo.
Aquí está la declaración de la función de paso que nos llevaría allí (NO COPIE ESTO):
{
"Comment": "One handler per state",
"StartAt": "Hello",
"States": {
"Hello": {
"Type": "Task",
"Resource": "<LAMBDA_FUNCTION_ARN>",
"Next": "World",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
]
},
"World": {
"Type": "Task",
"Resource": "<LAMBDA_FUNCTION_ARN>",
"Next": "Foo",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
]
},
"Foo": {
"Type": "Task",
"Resource": "<LAMBDA_FUNCTION_ARN>",
"Next": "Bar",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
]
},
"Bar": {
"Type": "Task",
"Resource": "<LAMBDA_FUNCTION_ARN>",
"Next": "Job Succeeded",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
]
},
"Job Succeeded": {
"Type": "Succeed"
},
"Send Failure Message": {
"Type": "Pass",
"Next": "Fail Workflow"
},
"Fail Workflow": {
"Type": "Fail"
}
}
}
Así que esto es genial, excepto que para cada paso adicional que agregamos, tenemos que agregar el componente de captura a cada paso. Agrega mucha hinchazón a nuestro ya horrible flujo de trabajo.
Si reestructuramos esto, podemos tener un flujo de trabajo que solo necesita capturarse una vez. Piense en ello como un controlador de excepciones externo que normalmente crearía en su código, excepto que estamos aplicando el mismo principio a los flujos de trabajo. Obviamente, la efectividad de esto aumenta una vez que tiene más de 2 estados en su flujo de trabajo. Podemos aprovechar el poder del estado Parallel para conseguirnos lo que queremos. Queremos algo más como esto:

La mejor declaración de función de paso de manejo de errores. Puede ver que los estados internos son mucho más concisos y más fáciles de administrar, y el diagrama lo es. mucho más agradable a los ojos también. (COPIAR ESTO)
{
"Comment": "Better error handling",
"StartAt": "ErrorHandler",
"States": {
"ErrorHandler": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Hello",
"States": {
"Hello": {
"Type": "Pass",
"Result": "Hello",
"Next": "World"
},
"World": {
"Type": "Pass",
"Result": "World",
"Next": "Foo"
},
"Foo": {
"Type": "Pass",
"Result": "World",
"Next": "Bar"
},
"Bar": {
"Type": "Pass",
"Result": "World",
"End": true
}
}
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
],
"Next": "Job Succeeded"
},
"Job Succeeded": {
"Type": "Succeed"
},
"Send Failure Message": {
"Type": "Pass",
"Next": "Fail Workflow"
},
"Fail Workflow": {
"Type": "Fail"
}
}
}
No más declaraciones Catch en todas partes 🤗; podemos agregar nuevos pasos sin tener que recordar vincular cada uno al manejo de errores.
Flujos de trabajo recursivos
Entonces AWS dice «no hagas esto». El gráfico que «se supone» que debe crear en lo que a ellos respecta es un gráfico acíclico dirigido. Bueno, eso está bien, excepto cuando realmente quiere hacer algo repetidamente hasta que haya completado su tarea. Un buen ejemplo de esto sería rellenar algunos datos desde la fecha A hasta la fecha B.
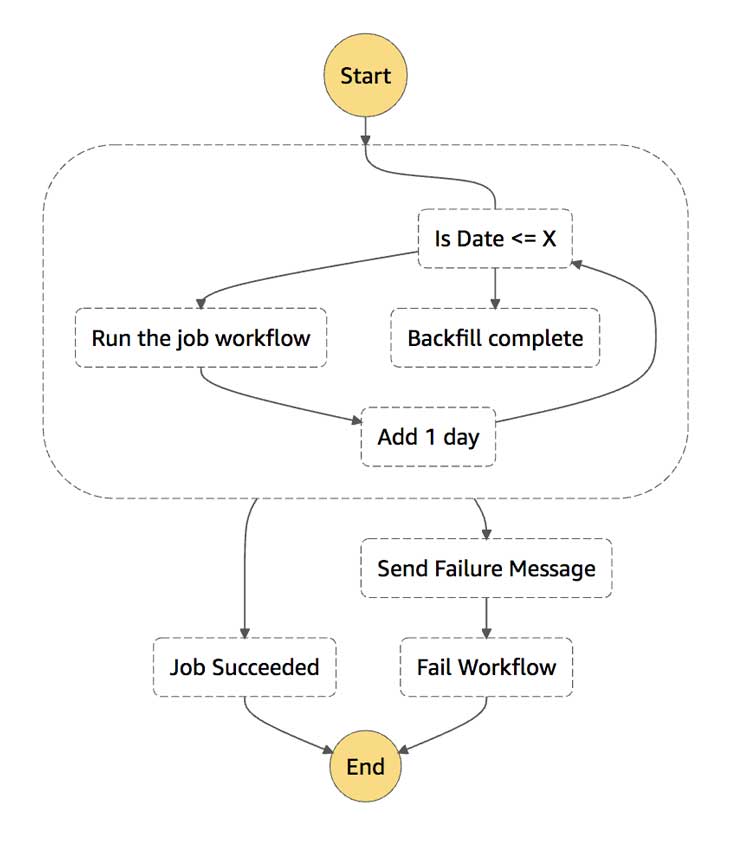
De manera práctica, hemos levantado el ejemplo de manejo de errores de anteriormente en este artículo y lo hemos construido sobre eso para que cualquier falla nos manifieste sus errores 😉. También vamos a hacer uso de una característica más nueva de las funciones de pasos de AWS (lanzada en agosto de 2020), el TimestampLessThanEqualsPathcomparador, para permitirnos comparar 2 variables diferentes en nuestra entrada. Aquí podemos utilizar una startDatey endDatepara delimitar el rango queremos que nuestro flujo de trabajo recursiva para operar de nuevo.
{
"Comment": "Better error handling",
"StartAt": "ErrorHandler",
"States": {
"ErrorHandler": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Is Date <= X",
"States": {
"Is Date <= X": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.startDate",
"TimestampLessThanEqualsPath": "$.endDate",
"Next": "Run the job workflow"
}
],
"Default": "Backfill complete"
},
"Backfill complete": {
"Type": "Pass",
"Result": "World",
"End": true
},
"Run the job workflow": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync",
"Parameters": {
"StateMachineArn": "<STATE_MACHINE_ARN>",
"Input": {
"date": "$.startDate",
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id"
}
},
"Next": "Add 1 day"
},
"Add 1 day": {
"Type": "Task",
"Resource": "<LAMBDA_FUNCTION_ARN>",
"Parameters": {
"date.$": "$.startDate"
},
"ResultPath": "$.startDate",
"Next": "Is Date <= X"
}
}
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Send Failure Message"
}
],
"Next": "Job Succeeded"
},
"Job Succeeded": {
"Type": "Succeed"
},
"Send Failure Message": {
"Type": "Pass",
"Next": "Fail Workflow"
},
"Fail Workflow": {
"Type": "Fail"
}
}
}
Simplemente inicie este flujo de trabajo con a {"startDate": "2020-09-01T00:00:00Z", "endDate": "2020-09-09T00:00:00Z"}y obtendrá 9 iteraciones de flujo de trabajo, cada una ejecutada con 1 día de diferencia.
Este flujo de trabajo se basa en una lambda disponible para restar 1 día de su entrada de fecha para sobrescribir el $.startDate, pero dejaré que usted lo implemente. Tengo que dejarte algo divertido que hacer 😜
Conclusión
Es posible tener un manejo de errores decente que no requiere mucho esfuerzo para implementar y detecta TODOS los errores dentro de sus flujos de trabajo. Ahora debería poder implementar flujos de trabajo recursivos para realizar operaciones basadas en el tiempo utilizando uno de los nuevos operadores disponibles.
Gracias por leer.






Añadir comentario