
Hola, soy Luis y aquí les traigo un nuevo tutorial.
Índice
Mejore la velocidad y la eficiencia de la inferencia con Hugging Face, ONNX y Cortex
En el procesamiento del lenguaje natural, el estado del arte está dominado por grandes modelos de Transformer, que plantean desafíos de producción debido a su tamaño.
El parámetro GPT-2 de 1.500 millones, por ejemplo, tiene ~ 6 GB completamente entrenado y requiere GPU para cualquier cosa cercana a la latencia en tiempo real.
El T5 de Google tiene 11 mil millones de parámetros. Turing-NLG de Microsoft tiene 17 mil millones. GPT-3 tiene 153 mil millones de parámetros.
Para más contexto, recomendaría el escrito de Nick Walton sobre el desafíos de escalar AI Dungeon, que sirve de inferencia en tiempo real a partir de un GPT-2 ajustado.
Debido a estos desafíos, la optimización del modelo es ahora un enfoque principal para los ingenieros de aprendizaje automático. Descubrir cómo hacer que estos modelos sean más pequeños y rápidos es un requisito previo para que se puedan utilizar ampliamente.
En este artículo, voy a recorrer un proceso para optimizar e implementar modelos de Transformer usando Transformers de Hugging Face, ONNXy Cortex.
A modo de comparación, implementaré un PyTorch BERT previamente entrenado y una versión ONNX optimizada como API en AWS.
Optimización de un modelo de Transformer con Hugging Face y ONNX
Comenzaremos accediendo a un BERT previamente entrenado y convirtiéndolo a ONNX. ¿Por qué estamos convirtiendo BERT de PyTorch a ONNX? Por dos razones:
- Las optimizaciones de gráficos integradas de
ONNX Runtimeaceleran la inferencia de Transformer mejor que otros optimizadores populares, según los puntos de referencia. -
ONNX Runtimees capaz de realizar una cuantificación más eficiente (reduciendo el tamaño de un modelo convirtiéndolo en números enteros a partir de decimales de coma flotante).
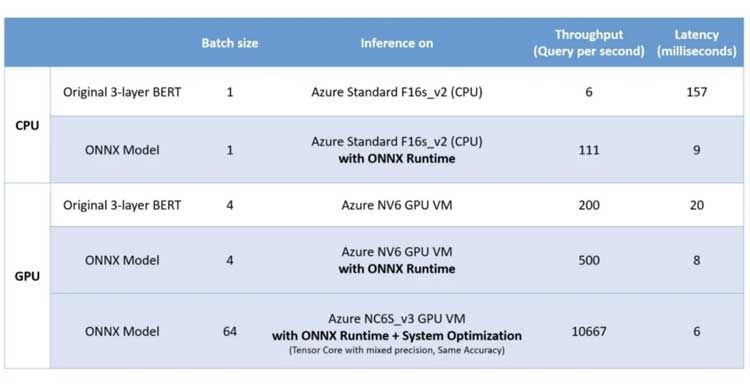
Según los datos publicados por Microsoft, vieron un aumento de 17 en la inferencia de la CPU mediante la optimización del BERT de 3 capas original en ONNX.
En realidad, realizar la optimización es bastante sencillo. Hugging Face y ONNX tienen herramientas de línea de comandos para acceder a modelos previamente entrenados y optimizarlos. Podemos hacerlo todo con un solo comando:
$ python -m transformers.convert_graph_to_onnx — framework pt — model bert-base-uncased — quantize bert-base-uncased.onnx
Con ese comando, hemos descargado un BERT previamente entrenado, lo convertimos a ONNX, lo cuantificamos y lo optimizamos para la inferencia.
Comparando rápidamente el tamaño de los dos modelos después de que nuestro modelo ONNX haya sido cuantificado:
Eso es aproximadamente un Reducción de tamaño 4x fuera de la puerta. Alentador, pero veamos cómo esto afecta la velocidad de inferencia.
Sirviendo modelos ONNX y Pytorch localmente
Ahora que tenemos un modelo optimizado, queremos servirlo. Para nuestros propósitos, esto significa envolverlo en una API de predicción.
Esta es nuestra API de predicción de PyTorch, que inicializa un BERT previamente entrenado utilizando la biblioteca Transformers y define un método predict () para él:
Nuestra API ONNX utilizará la misma lógica básica:
Una vez implementado, podemos enviar algo de tráfico de prueba a ambas API y verificar su rendimiento a través de la CLI de Cortex:
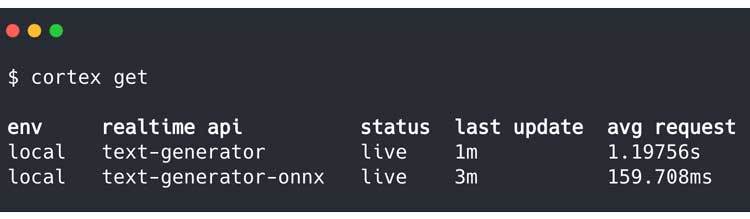
Si bien nuestro modelo PyTorch promedia 1.19756 segundos por solicitud, nuestro modelo ONNX funciona a 159.708 milisegundos por solicitud, un casi exactamente un aumento de 7.5x en la velocidad de inferencia.
Y, tenga en cuenta, estos solo se están implementando en mi MacBook que no es de primera línea. Implementados en un clúster de producción, lo que podemos hacer con solo unos pocos comandos con Cortex, estos modelos funcionarían significativamente más rápido.
Implementación de ONNX Runtime en producción
Ahora queremos ver cómo funcionan estos modelos en producción. Para probar, he creado un clúster de Cortex rápido y he implementado las API en la nube.

Actualmente, estas API se ejecutan en instancias c5n.xlarge, que utilizan subprocesos en un Intel Xeon Platinum 8000.
Después de enviar algo de tráfico a cada API, podemos comparar su rendimiento aquí:
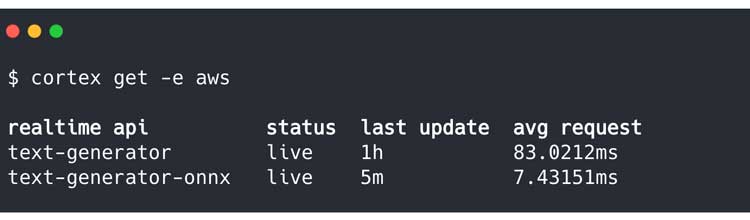
La aceleración es aún más extrema aquí: nuestro modelo ONNX aumentó la velocidad más de 10 veces.
Resultados finales
Al final, nuestro modelo ONNX optimizado es:
-
4veces más pequeño que enPyTorch. -
10veces más rápido que enPyTorch.
Eso es un aumento potencial de 40 veces en el rendimiento de inferencia.
Para poner estos números en una perspectiva un poco más, piénselo desde una perspectiva de costos. Cortex, por ejemplo, utiliza el ajuste de escala automático basado en solicitudes para escalar las API de predicción.
En un nivel muy alto, esto significa que Cortex calcula la cantidad de instancias necesarias comparando la longitud de la cola de solicitudes con las capacidades de concurrencia de una única API.
4x nos permite ajustar 3 API más en una sola instancia, y que acelerar la inferencia en un factor de 10 permite que cada modelo maneje 5 veces más solicitudes concurrentes (esta es una estimación conservadora).
Si actualmente mantiene un promedio de 25 instancias para manejar el tráfico de producción, estas optimizaciones llevarían la cuenta regresiva de su instancia a 2.
Si una instancia cuesta $ 0,80 la hora, ha pasado de gastar $ 175,200 por año a gastar $ 14,016 – un número que podría reducir en otro 50% aproximadamente mediante la implementación de instancias puntuales.
La mayoría de los modelos de Transformer pueden optimizarse e implementarse siguiendo estas mismas líneas utilizando ONNX Runtime y Cortex.
Gracias por leer este tutorial.






Añadir comentario