
Bienvenido, les saluda Luis y para hoy les traigo otro post.
Índice
Ciencia de datos del tamaño de un bocado para la detección de anomalías
SVM de una clase: una introducción
Un experto o un novato en el aprendizaje automático, probablemente haya oído hablar de Support Vector Machine (SVM), un algoritmo de aprendizaje automático supervisado que se cita con frecuencia y se utiliza en problemas de clasificación. Las SVM utilizan hiperplanos en un espacio multidimensional para separar una clase de observaciones de otra. Naturalmente, SVM se utiliza para resolver problemas de clasificación de clases múltiples.
Sin embargo, SVM también se usa cada vez más en un problema de una clase, donde todos los datos pertenecen a una sola clase. En este caso, el algoritmo está entrenado para aprender qué es “normal”, de modo que cuando se muestre un nuevo dato el algoritmo pueda identificar si debe pertenecer al grupo o no. De lo contrario, los nuevos datos se etiquetan como anormales o fuera de lo común. Para obtener más información sobre SVM de una clase, consulte este extenso artículo de Roemer Vlasveld .
Una última cosa que mencionar, si está familiarizado con la sklearnbiblioteca, notará que hay un algoritmo diseñado específicamente para lo que se conoce como » detección de novedades «. Funciona de manera similar a la que acabo de describir en la detección de anomalías usando SVM de una clase. En mi opinión, es solo el contexto el que determina si llamarlo detección de novedades o detección de valores atípicos o algo así.
A continuación se muestra una demostración simple de SVM de una clase en el lenguaje de programación Python. Tenga en cuenta que estoy usando valores atípicos y anomalía indistintamente.
Importar bibliotecas
Para esta demostración, necesitamos tres bibliotecas principales: para la gestión de datos python y numpy, para construcción de maquetas sklearn y para visualización matlotlib.
# import libraries import pandas as pd from sklearn.svm import OneClassSVM import matplotlib.pyplot as plt from numpy import where
Preparar los datos
Estoy usando el famoso Conjunto de datos de iris de una fuente en línea, para que pueda practicar sin preocuparse de dónde obtener los datos y cómo limpiarlos.
# import data
data = pd.read_csv("https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv")# input data
df = data[["sepal_length", "sepal_width"]]
Modelado
En lugar del ajuste de hiperparámetros como en otros algoritmos de clasificación, SVM de una clase usa nu como un hiperparámetro que se usa para definir qué porción de datos deben clasificarse como valores atípicos. nu = 0.03 significa que el algoritmo designará datos del 3% como valores atípicos.
# model specification model = OneClassSVM(kernel = 'rbf', gamma = 0.001, nu = 0.03).fit(df)
Predicción
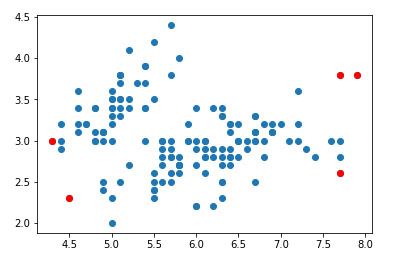
El conjunto de datos pronosticado tendrá valores 1 o -1, donde los valores -1 son valores atípicos detectados por el algoritmo.
# prediction y_pred = model.predict(df) y_pred

Filtrado de anomalías
# filter outlier index outlier_index = where(y_pred == -1) # filter outlier values outlier_values = df.iloc[outlier_index] outlier_values

Visualización de anomalías
# visualize outputs plt.scatter(data["sepal_length"], df["sepal_width"]) plt.scatter(outlier_values["sepal_length"], outlier_values["sepal_width"], c = "r")
Resumen
En este artículo, quería dar una breve introducción a One-Class SVM, un algoritmo de aprendizaje automático utilizado para la detección de fraudes / valores atípicos / anomalías. Mostré algunos pasos simples para construir la intuición, pero por supuesto, una implementación en el mundo real requeriría mucha más experimentación para descubrir qué funciona y qué no para un contexto e industria en particular.






Añadir comentario