
Muy buenas, me llamo Miguel y hoy les traigo otro post.
¿Se ha preguntado alguna vez qué hace que Power BI sea tan rápido y potente en lo que respecta al rendimiento? Tan potente que realiza cálculos complejos en millones de filas en un abrir y cerrar de ojos.
En esta serie de artículos, profundizaremos para descubrir qué hay «bajo el capó» de Power BI, cómo se almacenan, comprimen, consultan y, finalmente, se devuelven a su informe sus datos.
Una vez que termine de leer, espero que comprenda mejor el arduo trabajo que ocurre en segundo plano y aprecie la importancia de crear un modelo de datos óptimo para obtener el máximo rendimiento del motor Power BI.
Como recordará, en el artículo anterior analizamos la superficie de VertiPaq, un potente motor de almacenamiento, que es «responsable» del rendimiento ultrarrápido de la mayoría de sus informes de Power BI (siempre que utilice el modo de importación o el modelo compuesto).
Índice
3, 2, 1… ¡Abróchense los cinturones de seguridad!
Una de las características clave de VertiPaq es que es una base de datos en columnas. Aprendimos que las bases de datos en columnas almacenan datos optimizados para el escaneo vertical, lo que significa que cada columna tiene su propia estructura y está físicamente separada de otras columnas.
Ese hecho permite a VertiPaq aplicar diferentes tipos de compresión a cada una de las columnas de forma independiente, eligiendo el algoritmo de compresión óptimo en función de los valores de esa columna específica.
La compresión se logra codificando los valores dentro de la columna. Pero, antes de profundizar en una descripción detallada de las técnicas de codificación.
Sólo tenga en cuenta que esta arquitectura no está relacionada exclusivamente con Power BI; en el fondo hay un modelo tabular, que también está «bajo el capó» de SSAS Tabular y Excel. Power Pivot.
Este es el tipo de codificación de valor más deseable ya que funciona exclusivamente con enteros y, por lo tanto, requiere menos memoria que, por ejemplo, cuando se trabaja con valores de texto.
¿Cómo se ve esto en la realidad? Digamos que tenemos una columna que contiene una cantidad de llamadas telefónicas por día, y el valor en esta columna varía de 4.000 a 5.000.
Lo que haría el VertiPaq es encontrar el valor mínimo en este rango (que es 4.000) como punto de partida, luego calcular la diferencia entre este valor y todos los demás valores en la columna, almacenando esta diferencia como un nuevo valor.

A primera vista, 3 bits por valor puede no parecer un ahorro significativo, pero multiplique esto por millones o incluso miles de millones de filas y apreciará la cantidad de memoria ahorrada.
Como ya destaqué, la codificación de valor se aplica exclusivamente a columnas de tipo de datos enteros (el tipo de datos de moneda también se almacena como un número entero).
Este es probablemente el tipo de compresión más utilizado por VertiPaq. Usando la codificación Hash, VertiPaq crea un diccionario de los valores distintos dentro de una columna y luego reemplaza los valores «reales» con valores de índice del diccionario.
Aquí está el ejemplo para aclarar las cosas:
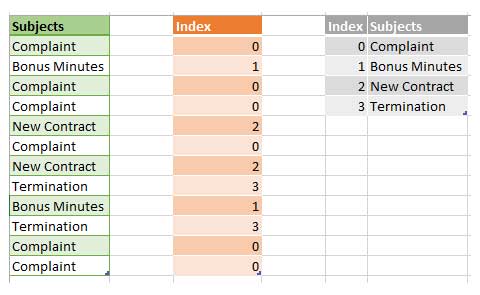
Como puede notar, VertiPaq identificó valores distintos dentro de la columna Temas, construyó un diccionario asignando índices a esos valores y finalmente almacenó valores de índice como indicadores a valores “reales”.
Supongo que sabe que los valores enteros requieren mucho menos espacio de memoria que el texto, por lo que esa es la lógica detrás de este tipo de compresión de datos.
Además, al poder construir un diccionario para cualquier tipo de datos, VertiPaq es prácticamente independiente del tipo de datos.
Esto nos lleva a otra toma de control clave: no importa si su columna es de tipo de datos text, bigint o float, desde la perspectiva de VertiPaq es lo mismo.
Necesita crear un diccionario para cada una de esas columnas, lo que implica que todas estas columnas proporcionarán el mismo rendimiento, tanto en términos de velocidad como de espacio de memoria asignado.
Desde luego, asumiendo que no hay grandes diferencias entre los tamaños de diccionario entre estas columnas.
Por tanto, es un mito que el tipo de datos de la columna afecte su tamaño dentro del modelo de datos. Por el contrario, el número de valores distintos dentro de la columna, que se conoce como cardinalidad, influyen principalmente en el consumo de memoria de la columna.
El tercer algoritmo (RLE) crea una especie de tabla de mapeo, que contiene rangos de valores repetidos, evitando almacenar cada valor (repetido) por separado.
Nuevamente, echar un vistazo a un ejemplo ayudará a comprender mejor este concepto:
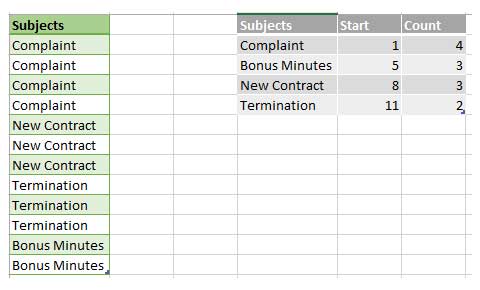
En la vida real, VertiPaq no almacena los valores de inicio, porque puede calcular rápidamente dónde comienza el siguiente nodo sumando los valores de recuento anteriores.
Por poderoso que pueda parecer a primera vista, el algoritmo RLE depende en gran medida del orden dentro de la columna. Si los datos se almacenan de la manera que ve en el ejemplo anterior, RLE funcionará muy bien.
Sin embargo, si sus depósitos de datos son más pequeños y rotan con más frecuencia, entonces RLE no sería una solución óptima.
Una cosa más a tener en cuenta con respecto a RLE: en realidad, VertiPaq no almacena datos como se muestra en la ilustración anterior.
Primero, realiza la codificación Hash y crea un diccionario de los temas y luego aplica el algoritmo RLE, por lo que la lógica final, en su forma más simplificada, sería algo como esto:

Entonces, RLE ocurre después de Value o Hash Encoding, en aquellos escenarios en los que VertiPaq “piensa” que tiene sentido comprimir datos adicionalmente (cuando los datos se ordenan de esa manera, RLE lograría una mejor compresión).
No importa cuán “inteligente” sea VertiPaq, también puede tomar algunas decisiones incorrectas, basadas en suposiciones incorrectas. Antes de explicar cómo funciona el código, permítanme repetir brevemente el proceso de compresión de datos para una columna específica:
- VertiPaq escanea una muestra de filas de la columna
- Si el tipo de datos de la columna no es un número entero, no buscará más y usará la codificación Hash
- Si la columna es de tipo de datos enteros, se están evaluando algunos parámetros adicionales: conforme los números en la muestra aumentan linealmente, VertiPaq asume que probablemente es una clave primaria y elige la codificación de valor
- Conforme los números de la columna están razonablemente cerca unos de otros (el rango de números no es muy amplio, como en nuestro ejemplo anterior con
4.000–5.000llamadas telefónicas por día). - VertiPaq utilizará la codificación Value. Por el contrario, cuando los valores fluctúan significativamente dentro del rango (por ejemplo, entre
1.000y1.000.000), la codificación del valor no tiene sentido y VertiPaq aplicará el algoritmo Hash.
Sin embargo, a veces puede suceder que VertiPaq tome una decisión sobre qué algoritmo utilizar en función de los datos de muestra, pero luego aparecen algunos valores atípicos y es necesario volver a codificar la columna desde cero.
Usemos nuestro ejemplo anterior para la cantidad de llamadas telefónicas: VertiPaq escanea la muestra y elige aplicar la codificación Value.
Luego, después de procesar 10 millones de filas, de repente encontró un valor de 50.000 (puede ser un error o lo que sea). Ahora, VertiPaq vuelve a evaluar la elección y puede decidir volver a codificar la columna utilizando el algoritmo Hash.
Sin duda, eso afectaría a todo el proceso en términos de tiempo necesario para el reprocesamiento.
Conclusión
En esta parte de la serie sobre el «cerebro y los músculos» detrás de Power BI, nos sumergimos en los diferentes algoritmos de compresión de datos que VertiPaq realiza para optimizar nuestro modelo de datos.
Finalmente, aquí está la lista de parámetros (en orden de importancia) que VertiPaq considera al elegir qué algoritmo usar:
- Número de valores distintos en la columna (cardinalidad).
- Distribución de datos en la columna: la columna con muchos valores repetidos se puede comprimir mejor que una que contiene valores que cambian con frecuencia (se puede aplicar RLE).
- Número de filas en la tabla.
- Tipo de datos de columna: solo afecta al tamaño del diccionario.
En el siguiente artículo, presentaré algunas técnicas para reducir el tamaño del modelo de datos y, en consecuencia, obtener el mejor rendimiento general de su informe de Power BI.
Gracias por leer este post.






Añadir comentario