
Hola, soy Miguel y aquí les traigo otro artículo.
En esta publicación, utilizaremos la biblioteca Pandas con Python para demostrar cómo limpiar los datos del mundo real para que estén listos para usarse en cualquier tarea de procesamiento. Francamente, la mayoría de los datos obtenidos de los sensores del mundo real contienen mucha basura y valores nulos. A menudo, los datos están en un formato que no es compatible con el análisis de datos o los algoritmos de aprendizaje automático. Por lo tanto, la limpieza de datos es casi siempre el primer paso en la mayoría de los trabajos de análisis de datos / ML / AI.
Pandas es una biblioteca inmensamente poderosa para la manipulación de datos. Anteriormente, era un gran fanático de Matlab y pensaba que no hay rival para Matlab cuando se trata de análisis de datos. Pero desde que me mudé a Pandas (Python en realidad), odio volver a Matlab nuevamente.
De todos modos, deje Matlab a un lado ahora y comencemos con Pandas.
Los datos que utilizaré son el registro de datos de llamadas del mundo real (CDR) que Telecom Italia hizo público como parte de una competencia de Big Data en 2014.
El conjunto de datos captura las llamadas, los SMS y el uso de Internet de los usuarios de Telecom Italia en la ciudad de Milán, Italia durante dos meses completos. Cada día se registra como un solo archivo. Sin embargo, para este blog, solo usaré los datos de un solo día (es decir, un solo archivo) de este CDR.
Importación de todos los paquetes necesarios
import pandas as pd from pandas import read_csv
Después de importar todos los paquetes necesarios, hagamos lo real. Los pandas proporcionan una función read_csv (…) (que hemos importado anteriormente) para leer diferentes tipos de archivos de datos. En nuestros archivos, los datos se almacenan en un formato delimitado por tabulaciones. Por lo tanto usaremos argumento <delimiter = ‘\ t’> para especificar durante el proceso de lectura para romper siempre que exista una pestaña ( t) en el archivo.
Siempre prefiero no meterme con la variable real que almacena datos. Por lo tanto, clonaremos datos en otro marco de datos y lo llamaremos df. El comando df.head () mostrará los primeros miembros del conjunto de datos.
dataset = pd.read_csv('D:/Research/dataset/sms-call-internet-mi-2013-11-1.txt', delimiter='t')
df = dataset
df.head()
Observe que el conjunto de datos está en formato sin procesar (consulte la Fig. 1 a continuación). Incluso no se mencionan los nombres de las columnas.
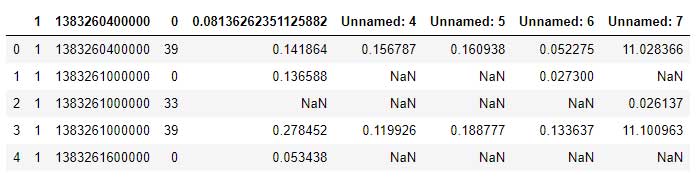
En primer lugar, daremos nombres apropiados a todas las columnas usando columnas df.. En este caso particular, el proveedor del conjunto de datos (es decir, Telecom Italia) ha proporcionado toda la información sobre las columnas. Por lo tanto, usaremos esta información para nombrar apropiadamente cada columna.
df.columns = ['Grid ID', 'Time Stamp','Caller ID','SMS in', 'SMS out','Call in','Call out','Internet']
Limpieza de datos
La limpieza de datos es un paso muy crucial y casi siempre necesario (como se mencionó anteriormente) cuando se trabaja con datos del mundo real, ya que los datos capturados pueden tener muchas discrepancias, valores perdidos, etc.
Por ejemplo, observe que en la Figura 1 anterior hay varios valores de NaN dentro del conjunto de datos sin procesar. Estos valores indican que los sensores de adquisición de datos no pudieron obtener ningún valor por cualquier motivo. Reemplazaremos todos los valores de NaN con cero (0). Para este propósito, los pandas proporcionan una función simple. fillna (…). Usaremos esta función para reemplazar NaN con Zeros (0). Además, tenga en cuenta que el uso inplace = True es equivalente a decir df = df.fillna (0). Esta es otra característica importante de los pandas que permite una versión más limpia y más corta del código.
La unidad de tiempo para cada entrada de registro se da en milisegundos. Por lo tanto, también cambiaremos la unidad de tiempo a minutos. Finalmente, mostraremos los datos formateados en la Figura 2 a continuación.
# Fill all the NaN values with 0 df.fillna(0,inplace = True) #The time is in milli-seconds. We will change it to minutes. df['Time Stamp'] = df['Time Stamp']/(1000*60) df.head()

Observe que todos los valores de NaN se reemplazan por 0. La marca de tiempo también se ha cambiado a minutos.
Finalmente, mostraremos la actividad de Internet para observar qué tipo de datos tenemos (también puede jugar con otras actividades como Llamar, Llamar a, etc.). También puede intentar insertar otras actividades.
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.plot(df['Internet'])
plt.grid()
plt.xlabel('Time (in 10-minute interval)', fontsize =12)
plt.ylabel('Activity', fontsize = 12)

Pararemos aquí esta semana. La próxima semana, usaremos esta versión más limpia de datos para predecir el tráfico celular usando Deep Neural Network (Recurrent Neural Net). Hasta entonces…
El código completo está presente aquí.






Añadir comentario