
Hola, les saluda Miguel y aquí les traigo otro post.
En realidad, los proyectos de ciencia de datos a menudo implican recopilar información de una variedad de fuentes que pueden requerir datos de varias tablas. Por lo tanto, para realizar el análisis, es necesario unirse a las mesas. Fusionar en Python Pandas es una forma muy eficaz de realizar con éxito esta operación.
Este tutorial tiene como objetivo guiarlo a través del proceso paso a paso de diferentes métodos para fusionar marcos de datos con la biblioteca pandas en Python utilizando el argumento «cómo».
Primero, importe conjuntos de datos y conviértalos en tablas
importar pandas como pd
df = pd.read_csv (‘enlace.csv’)
#convertir columna de año a objeto de fecha
df[‘Year’] = pd.to_datetime (df[‘Year’], formato = ‘% Y’). dt.year
#groupby country
df = pd.DataFrame (df1.groupby ([‘Country’, ‘Year’], as_index = False) .sum ())
imprimir (df)
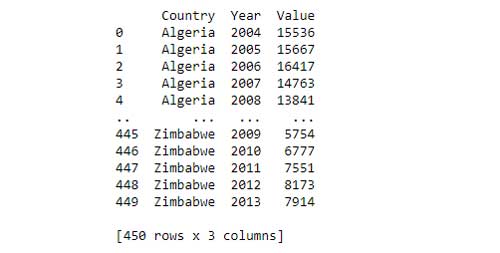
df1 = pd.read_excel (r’ruta donde el archivo está almacenado.xlsx ‘)
imprimir (df1)
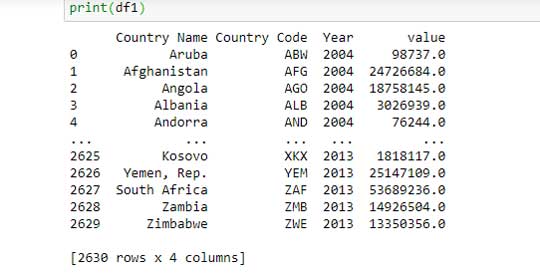
Entonces, tenemos dos tablas: df y df1
Columnas df = País, Año y Valor
Columnas df1 = nombre de país, código de país, año y valor
Para fusionar ambas tablas, se necesita una clave principal. Observe que la columna que significa País tiene nombres diferentes para ambas tablas. Por lo tanto, cambiemos el nombre de la columna ‘Country Name’ de la tabla df1 a ‘Country’ y agrupemos por la columna.
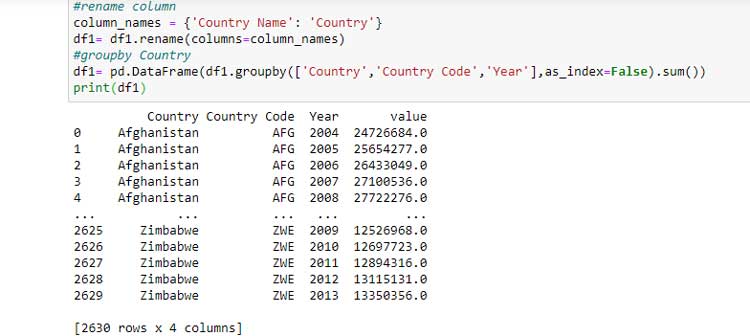
Ahora, fusionando ambos marcos de datos

Observe que fusionamos a la izquierda, esto implica que la tabla anterior contiene solo filas que coinciden con la tabla df solamente. Es decir, cualquier país adicional incluido en la tabla df1 que no esté en la tabla df no se incluye en la tabla df2 anterior.
Ahora usemos la combinación derecha, interna y externa



La combinación interna elimina las filas que no coinciden en ambos marcos de datos. Esta es la combinación de pandas predeterminada en Python si no especifica el tipo de combinación que desea.
Por favor, hágame saber cualquier comentario, sugerencia o pregunta que pueda tener 🙂






Añadir comentario