
Muy buenas, soy Miguel y para hoy les traigo este nuevo artículo.
A veces, deberías
Pandas es una de las herramientas más útiles que puede utilizar un científico de datos. Proporciona varias funcionalidades útiles para extraer información. Desafortunadamente, el uso de Pandas requiere que los datos se carguen en DataFrames, que no son excelentes para manejar cantidades masivas de datos, cantidades de datos comunes en una empresa donde necesitaría tales habilidades de manipulación de datos.
Si tuviera que descargar un conjunto de datos completo y masivo, tal vez almacenarlo como un archivo .csv, necesitaría pasar al menos varios minutos esperando que el archivo se complete la descarga y se convierta en un DataFrame por Pandas. Además de esto, cualquier operación que realice será lenta porque Pandas tiene problemas para manejar estas cantidades masivas de datos y necesita ejecutar cada fila.
¿Una mejor solución? Primero, consulte la base de datos con SQL, el lenguaje de procesamiento nativo y eficiente en el que probablemente se ejecuta, luego descargue un conjunto de datos reducido, si es necesario, y use Pandas para operar en las tablas de menor escala en las que está diseñado para trabajar. Si bien SQL es muy eficiente con grandes bases de datos, no puede reemplazar el valor de la integración de gráficos de Panda con otras bibliotecas y con el lenguaje Python en general.
Sin embargo, en el caso en el que solo necesitamos encontrar respuestas numéricas, como el costo promedio de un artículo o cuántos empleados reciben una comisión, pero no un salario por hora superior a $ 40, (generalmente) no es necesario tocar Pandas y un entorno Python en todas.
Si bien el conocimiento de SQL de la mayoría de las personas se detiene en SELECT * FROM table WHERE id = ‘Bob’, uno se sorprendería de las funcionalidades que ofrece SQL.
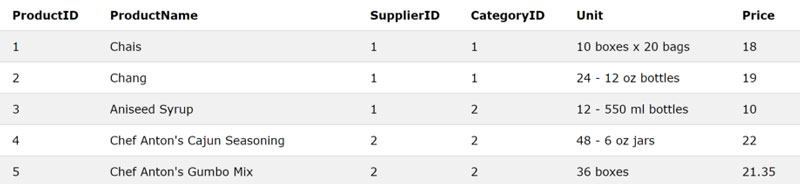
Como ejemplo, trabajaremos en la base de datos SQL Tryit Editor proporcionada por w3schools. Este sitio le permite ejecutar consultas SQL en una base de datos ficticia. La tabla Clientes (puede ver la lista completa de tablas en el panel derecho) tiene 7 columnas con datos numéricos y de texto:

Digamos que queremos enviar una declaración preparada en forma de «Nombre VIVE EN Dirección, Ciudad». Esto es simple: el operador de tubos dobles || actúa como una concatenación. Luego, podemos agregar valores de columna y cadenas, y guardar el resultado con un alias, o el nombre de columna del resultado, usando AS.

Tenga en cuenta que dado que especificamos adicionalmente Country=’Mexico’, nuestros resultados son todas direcciones y ciudades dentro de México. Este tipo de operación sería más difícil y menos fácil de realizar en Python.
Tenga en cuenta que no todas las bases de datos admiten la misma sintaxis. Este artículo usa sintaxis para PostgreSQL, aunque cada operación discutida tiene operaciones en bases de datos DB2, Oracle, MySQL y SQL Server, a veces con la misma sintaxis, a veces con sintaxis diferentes. StackOverflow o Google pueden ayudarlo a encontrar estas palabras clave específicas de la base de datos.
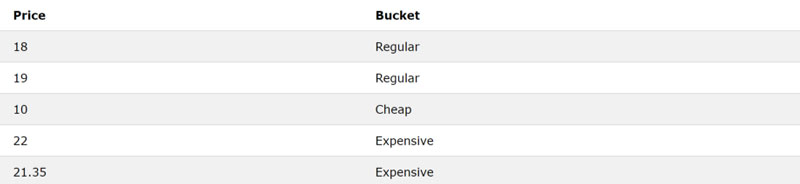
Di eso, en el Products tabla, queremos agrupar los productos en tres categorías de precios: Cheap, Regulary Expensive, para precios inferiores a $ 12, entre $ 12 y $ 21, y superiores a $ 21, respectivamente.
¡No hay problema! los CASE la palabra clave puede ayudar. Esta palabra clave actúa como una declaración if / else if / else en otros lenguajes como Python.
los CASE palabra clave usa la sintaxis WHEN condition THEN value. Cuando múltiples WHENs están apilados, asumen una relación «si no». Por último, un ELSE value se puede agregar si no se cumple la condición. Finalmente, END está escrito para indicar el final de la CASE declaración, y los resultados se guardan (con alias) en una columna denominada Bucket mediante AS Bucket.
Esto también se puede hacer en Pandas con .apply(), con una velocidad mucho más lenta.
Digamos que queremos muestrear al azar 5 filas de Products. Aunque no existe un método directo para hacer esto, podemos ser creativos utilizando tanto ORDER BY y LIMIT palabras clave. ORDER BY ordena los datos en un formato determinado; por ejemplo, usando ORDER BY Price ASC ordenaría los datos de manera que el precio estuviera en formato ascendente. Utilizando DESC usa descendente, y ORDER BY trabaja con cadenas ordenándolas alfabéticamente.
ORDER BY random() ordena los datos al azar, y LIMIT x devuelve las primeras x filas en el subconjunto de datos seleccionado. De esta forma, se seleccionan cinco filas aleatorias de los datos (* significa todas las columnas).
A tener en cuenta: Desafortunadamente, SQL Tryit Editor no admite random (), pero las bases de datos reales sí (o usan una variante, como rand()).
Al igual que esta tarea de muestreo aleatorio, la mayor parte de SQL se trata de encadenar varios comandos más simples como SELECT e integrarlos con funciones incorporadas para producir resultados asombrosamente complejos.
Además, SQL proporciona todas las funciones estadísticas que pueda necesitar. Con todo desde MIN() a MAX() a COUNT() a SUM() a AVG() a ASIN() (arcoseno), estás listo. Puede utilizar extensiones de paquete para métricas como la desviación estándar o crearlas usted mismo utilizando las funciones predeterminadas existentes, lo que no es nada difícil de hacer.
Estas son tareas estándar, pero lo que es más sorprendente es que SQL es un lenguaje completo de Turing. En pocas palabras, podría representar un programa en, digamos, Python o C ++, en SQL, construyendo sus propios sistemas de memoria complejos y usando elementos de SQL como funciones, if / elses, recursividad, etc. Puede ver algunas demostraciones fascinantes de Turing -sQL completo here. El punto principal de esto no es alentarlo a usar SQL como lenguaje operativo, sino demostrar que SQL puede usarse para hacer mucho más de lo que pensaba.
Hay mucho más que puede hacer en SQL que no hemos discutido:
- Especifique sus propias funciones personalizadas, como declararía una función en Python o C ++. Estos se pueden utilizar para, por ejemplo, analizar direcciones IP.
- Utilice la recursividad para crear bucles complejos y generación de datos con el
WITHpalabra clave. - Ordene las columnas de cadena por una subcadena.
- Realice uniones complejas entre varias tablas.
- Utilice SQL para generar SQL (tareas de automatización).
- Genere pronósticos utilizando modelos estadísticos.
- Crea histogramas.
- Construya estructuras de árbol (con hojas, ramas, nodos de raíz).
Es cierto que puede hacer mucho más con SQL que con Pandas. Dicho esto, normalmente esa funcionalidad adicional no es necesaria. La razón principal por la que debería usar SQL es porque está diseñado para manejar grandes cantidades de datos en un entorno personalizado que DataFrames no.
Generalmente, SQL es un lenguaje simple pero a veces muy desordenado, y generalmente debe usarse solo para reducir el tamaño de los datos hasta que sea más manejable en el entorno más pequeño de Pandas.
Puntos clave
- Pandas no es bueno en el manejo de macrodatos y todas sus funciones se pueden realizar con SQL. Sin embargo, el valor de Pandas proviene de su integración con otras bibliotecas de trazado, bibliotecas de aprendizaje automático y el lenguaje Python.
- El objetivo generalmente debería ser usar SQL para reducir un conjunto de datos grande a uno que sea más relevante para la tarea, luego manejarlo en un entorno Python, usando el DataFrame de Pandas como base para el almacenamiento.
- No tenga miedo de tocar SQL para manejar problemas de big data. Como se demostró anteriormente, la sintaxis de SQL es simple y casi se trata de encadenar comandos simples para producir resultados más complejos. Si tiene una visión clara del resultado, puede hacerlo realidad con SQL.
- SQL puede hacer mucho más de lo que la mayoría de la gente cree.





Añadir comentario