
Hola, me llamo Miguel y esta vez les traigo un tutorial.
Este artículo explica los conceptos básicos de la clasificación de imágenes multiclase y cómo realizar el aumento de imágenes.
Índice
¿Qué es el aumento de imagen?
Aumento de imagen, una solución al problema de datos limitados. El aumento de imagen es una técnica que se puede utilizar para ampliar el tamaño de un conjunto de datos de entrenamiento creando versiones modificadas de imágenes en el conjunto de datos. El aumento de imágenes abarca un conjunto de técnicas que mejoran el tamaño y la calidad de las imágenes de entrenamiento, de modo que se pueden construir mejores modelos de aprendizaje profundo con ellas.

Instalación de Tensorflow
Prerrequisitos
- Linux, macOS, Windows
- Python ≥ 3.7
Instalar TensorFlow
Solo CPU
pip install “tensorflow>=1.15.2,<2.0” or conda install tensorflow’>=1.15.2,<2.0.0'
Soporte de GPU
pip install “tensorflow-gpu>=1.15.2,<2.0” or conda install tensorflow-gpu’>=1.15.2,<2.0.0'
Prueba de cordura
>> import tensorflow as tf >> tf.__version__ '2.3.0'
Ahora vamos a usar Conjunto de datos de piedra, papel y tijeras de Kaggle para realizar la clasificación de imágenes multiclase.
¡Saltemos a eso!
1. Exploración de conjuntos de datos
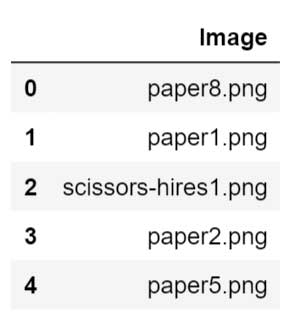
El conjunto de datos tiene tres directorios, a saber, entrenamiento, prueba y validación. Aquí, entrenar y probar tienen tres clases de imagen y la validación tiene una lista de imágenes para probar.
La salida es,
Train set --> ['paper', 'scissors', 'rock'] Test set --> ['paper', 'scissors', 'rock'] Validation set --> ['paper8.png', 'paper1.png', 'scissors-hires1.png']
2. Muestra de conjunto de datos
Visualicemos una imagen aleatoria de cada clase del conjunto de datos.
Entonces, las imágenes son:
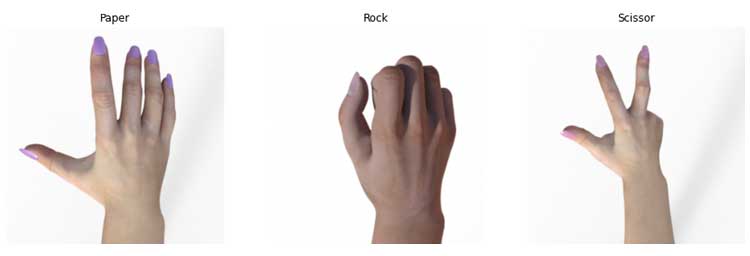
3. Definición del modelo de CNN
Este modelo se compone de cinco tipos diferentes de capa,
- Capa de convolución: Esta capa extraerá características importantes de la imagen
- Capa de agrupaciónr: esta capa reduce el volumen espacial de la imagen de entrada después de la convolución al aislar las características importantes
- Capa plana: Aplana la entrada en una matriz unidimensional
- Capa oculta: También llamada capa densa, conecta la red de una capa a otra capa
- Capa de salida: Es la capa final que consta de neuronas igual al no. De clases
Aquí, tenemos tres clases de imagen, entonces, la capa de salida debería tener tres neuronas.
Y, el resumen del modelo es,
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 1) 513 ================================================================= Total params: 3,453,121 Trainable params: 3,453,121 Non-trainable params: 0 _________________________________________________________________
4. Recopilación de modelos y función de devolución de llamada
Para este modelo, usamos adam optimizer y categorical_crossentropy como función de pérdida.
La función de devolución de llamada aquí detendrá el entrenamiento del modelo al final de la época cuando alcance la precisión> 95%.
5. Generadores
Generador de entrenamiento con aumento de imagen
Found 2520 images belonging to 3 classes.
Generador de validación
Found 372 images belonging to 3 classes.
6. Ajuste del modelo
Como estamos usando generadores en lugar de model.fit, necesitamos usar la función model .fit_generator
Epoch 1/10 126/126 - 46s - loss: 1.0141 - accuracy: 0.4591 - val_loss: 0.4937 - val_accuracy: 0.9301 Epoch 2/10 126/126 - 27s - loss: 0.5067 - accuracy: 0.7968 - val_loss: 0.0886 - val_accuracy: 0.9785 Epoch 3/10 126/126 - 27s - loss: 0.2712 - accuracy: 0.9056 - val_loss: 0.1290 - val_accuracy: 0.9624 Epoch 4/10 126/126 - 27s - loss: 0.1608 - accuracy: 0.9393 - val_loss: 0.1045 - val_accuracy: 0.9597 Epoch 5/10 Reached >95% accuracy so cancelling training! 126/126 - 26s - loss: 0.1408 - accuracy: 0.9512 - val_loss: 0.0784 - val_accuracy: 0.9677
7. Visualización del entrenamiento del modelo
Distribuyamos la precisión y la pérdida del modelo a lo largo de la época.
Y las gráficas resultantes son:


Podemos ver que la precisión aumenta y la pérdida disminuye para cada época.
8. Predicción
Preparación de datos de prueba
Generador de prueba
Found 33 validated image filenames.
Predicción del modelo
Asignación de etiquetas
Para identificar las etiquetas de la imagen, se utiliza la función class_indices
0: 'paper', 1: 'rock', 2: 'scissors'
Trazando la predicción

Rendimiento del modelo en imágenes no vistas

Precisión del modelo en imágenes no vistas
Accuracy of the model on test data is 93.94%
El código completo está disponible aquí
Gracias por leer.






Añadir comentario