Bienvenido, me llamo Luis y esta vez les traigo este tutorial.
Índice
Una breve introducción al aprendizaje y los desafíos federados
La próxima generación de inteligencia artificial se basa en la idea central que gira en torno a «privacidad de datos». Cuando la privacidad de los datos es una preocupación importante y no confiamos en que nadie retenga nuestros datos, podemos recurrir al aprendizaje federado para construir una IA que preserve la privacidad mediante la construcción de sistemas inteligentes de forma privada.
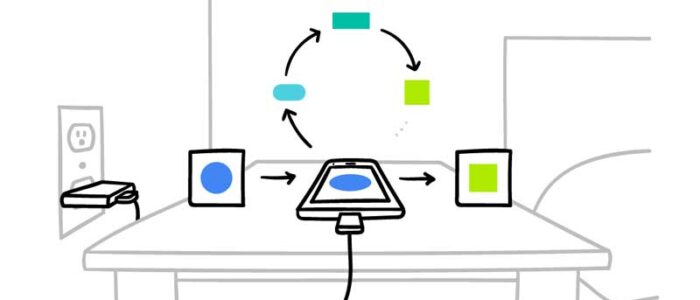
El aprendizaje federado consiste en trasladar cálculos a datos. Donde se compra un modelo compartido globalmente hasta donde están los datos, por ejemplo, teléfonos inteligentes. Al mover el modelo al dispositivo, podemos entrenar colectivamente un modelo como un todo.
Con este concepto en mente, cualquier persona puede participar en el aprendizaje federado en sus dispositivos, ya sea directa o indirectamente, por ejemplo, los dispositivos Edge, como los teléfonos inteligentes y los dispositivos de IoT, pueden beneficiarse de los datos en el dispositivo sin que los datos salgan del dispositivo, especialmente para dispositivos con restricciones computacionales donde la comunicación es un cuello de botella con dispositivos más pequeños.
El concepto de mover cálculos a datos es un concepto poderoso en términos de construir cualquier sistema inteligente mientras se protege la privacidad de cualquier individuo.
El aprendizaje federado también se presenta en tres categorías como:
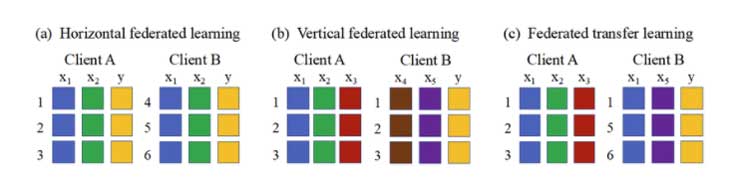
Aprendizaje federado horizontal
Utiliza conjuntos de datos con el mismo espacio de funciones en todos los dispositivos, esto significa que el Cliente A y el Cliente B tienen el mismo conjunto de funciones que se muestra en a) a continuación.
Aprendizaje federado vertical
Utiliza diferentes conjuntos de datos de diferentes espacios de características para entrenar conjuntamente un modelo global como se muestra en b) a continuación. Un ejemplo sería el Cliente A (Amazon) tiene información sobre las compras de películas del cliente en Amazon, y el Cliente B (IMDB) tiene información sobre las reseñas de películas del cliente, el uso de estos dos conjuntos de datos de diferentes dominios permite servir mejor a los clientes utilizando información de reseñas de películas (IMDB) para proporcionar una mejor recomendación de películas a los clientes que buscan películas en Amazon.
Aprendizaje de transferencia federado
Es el aprendizaje federado vertical que se utiliza con un modelo previamente entrenado que se entrena en un conjunto de datos similar para resolver un problema diferente. Un ejemplo de aprendizaje de transferencia federado es entrenar un modelo personalizado, por ejemplo, recomendación de película para el comportamiento de navegación anterior del usuario.
Cómo funciona el aprendizaje federado
El aprendizaje federado gira en torno al algoritmo de promediado federado denominado «FedAvg» [3]. FedAvg es el primer algoritmo de aprendizaje federado de vainilla formulado por Google [3] para resolver problemas de aprendizaje federado. Desde entonces, muchas variantes de algoritmos FedAvg como «FedProx«,»FedMa«,»FedOpt«,»Andamio”, Etc. se ha desarrollado para abordar muchos de los problemas de aprendizaje federado en [2].
A continuación se describe cómo funciona el algoritmo FedAvg a un alto nivel.
En cada ronda de FedAvg, el objetivo es minimizar el objetivo del modelo global w cual es solo la suma del promedio ponderado de la pérdida del dispositivo local.
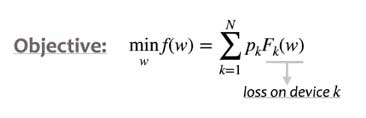
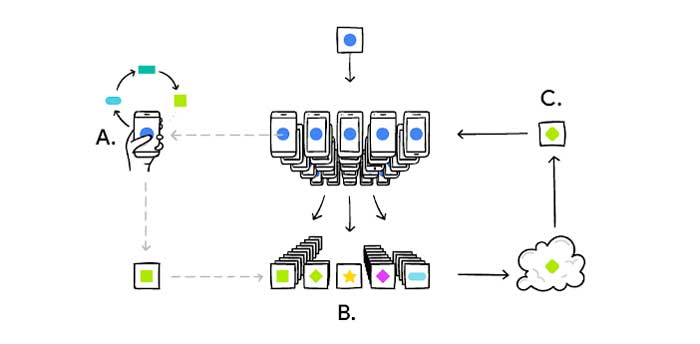
1. Un subconjunto de clientes / dispositivos se muestrea al azar.
2. El servidor transmite su modelo global a cada cliente.
3. En paralelo, los clientes corren Descenso de gradiente estocástico (SGD) en su propia función de pérdida y enviar el modelo resultante al servidor para su agregación.
4. Luego, el servidor actualiza su modelo global como el promedio de estos modelos locales.
5. A continuación, el proceso se repite durante norte tales rondas de comunicaciones.
Desafíos en el aprendizaje federado
Con una tecnología tan útil viene con una gran cantidad de desafíos que deben abordarse [2, 4]. Algunos de los desafíos más importantes que creo que deben abordarse fueron los siguientes cuatro puntos seleccionados de [4] (La lista no es de ninguna manera exhaustiva).
1. Compensación entre ruido y precisión
Utilizando Privacidad diferencial (DP), podemos agregar ruido a los datos para mejorar la protección de la privacidad. Sin embargo, con DP sacrificamos el rendimiento del modelo. Por lo tanto, se requiere una compensación para agregar la cantidad correcta de ruido y no comprometer el rendimiento del modelo.
2. Sistema y heterogeneidad estadística
La capacitación en dispositivos heterogéneos es un desafío, es importante garantizar que el aprendizaje federado se amplíe de manera efectiva en todos los dispositivos, independientemente del tipo de dispositivos. La diferencia de información estadística se refiere a la incapacidad de un dispositivo para derivar el patrón estadístico global de manera que las poblaciones, las muestras o los resultados sean diferentes de un dispositivo en comparación con los otros dispositivos.
3. Cuellos de botella en la comunicación
El costo de comunicación para llevar los modelos al dispositivo debe ser moderadamente bajo, ya que puede afectar el entorno FL, donde un dispositivo puede quedar inutilizado debido a cuellos de botella en la comunicación, lo que a su vez paraliza el proceso de capacitación federado. Hay varios trabajos para abordar los cuellos de botella de la comunicación, como la eliminación de rezagados (dispositivos que no pudieron calcular el entrenamiento dentro de la ventana de tiempo especificada) y la compresión / cuantificación del modelo para reducir el costo del ancho de banda.
4. Envenenamiento
El envenenamiento se presenta en dos formas:
a) Envenenamiento de datos
Durante un proceso de entrenamiento federado, varios clientes pueden participar contribuyendo con sus datos de entrenamiento en el dispositivo, y es difícil detectar / evitar que los clientes malintencionados envíen datos malintencionados / falsos para envenenar el proceso de entrenamiento que a su vez envenena el modelo.
b) Modelo de envenenamiento
Contrariamente al envenenamiento de datos, los clientes malintencionados modifican el modelo recibido alterando su gradiente / parámetros antes de enviarlo de vuelta al servidor central para su agregación, como resultado, el modelo global puede ser severamente envenenado con gradientes inválidos durante el proceso de agregación.
5. Compensación entre eficiencia y privacidad
Utilizando Multi-Computación segura (SMPC) y privacidad diferencial (DP) aumentar la capacidad de protección de la privacidad en el aprendizaje federado, sin embargo, dicha protección viene con una compensación entre costo y eficiencia. Utilizando SMPC, los clientes deben cifrar los parámetros de los modelos antes de enviarlos de vuelta al servidor central, por lo tanto, se requieren recursos computacionales adicionales para el cifrado, lo que comprometerá la eficiencia del entrenamiento del modelo. Con DP, se agrega ruido al modelo y los datos, por lo que se pierde algo de precisión. Por lo tanto, encontrar un equilibrio adecuado entre SMPC y DP es un desafío abierto en el aprendizaje federado.
Conclusión
El aprendizaje federado es todavía un campo relativamente nuevo con muchas oportunidades de investigación para mejorar la IA que preserva la privacidad. Esto incluye desafíos como heterogeneidad del sistema, heterogeneidad estadística, preocupaciones sobre la privacidad y eficiencia de la comunicación, etc.. Esto plantea muchos problemas abiertos en el aprendizaje federado que deben abordarse en su conjunto antes de que la industria pueda adoptar ampliamente el aprendizaje federado.
Referencias
[1] Aprendizaje federado: aprendizaje automático colaborativo sin datos de formación centralizados
[2] Avances y problemas abiertos en el aprendizaje federado
[3] Aprendizaje eficiente en comunicación de redes profundas a partir de datos descentralizados
[4] Una encuesta sobre seguridad y privacidad del aprendizaje federado
Gracias por leer.






Añadir comentario