
Hola, me llamo Miguel y para hoy les traigo otro nuevo post.
Índice
Aprender a usar el poder de las CNN
Cada año, los fabricantes de automóviles están agregando sistemas de asistencia al conductor más avanzados (ADAS) a sus flotas. Estos incluyen control de crucero adaptativo (ACC), advertencia de colisión frontal (FCW), estacionamiento automático y más. Un estudio descubrió que ADAS podría prevenir hasta 28% de todos los accidentes en los Estados Unidos. Esta tecnología solo mejorará y eventualmente se convertirá en autos totalmente autónomos de Nivel 5.
Para que un automóvil se conduzca por sí solo, debe ser capaz de comprender su entorno. Esto incluye otros vehículos, peatones y las señales de tráfico.
Las señales de tránsito nos brindan información importante sobre la ley, nos advierten sobre condiciones peligrosas y nos guían hacia el destino deseado. Si un automóvil no puede distinguir las diferencias en símbolos, colores y formas, muchas personas podrían resultar gravemente heridas.
La forma en que un automóvil ve la carretera es diferente de cómo la percibimos nosotros. Todos podemos distinguir instantáneamente la diferencia entre las señales de tráfico y las distintas situaciones de tráfico. Al enviar imágenes a una computadora, solo ven unos y ceros. Eso significa que debemos enseñarle al automóvil a aprender como los humanos, o al menos a identificar signos como nosotros.
Para resolver este problema, intenté construir mi propia red neuronal convolucional (CNN) para clasificar las señales de tráfico. En este proceso, hay tres pasos principales: imágenes de preprocesamiento, construyendo la red neuronal convolucionaly emitiendo una predicción.
Imágenes de preprocesamiento
En la etapa de preprocesamiento, las imágenes se importan del repositorio de Bitbucket “german-traffic-signs”. Esto contiene un conjunto de datos de imágenes etiquetadas lo que nos permitirá construir un modelo de aprendizaje supervisado. Este repositorio se puede clonar en un cuaderno de Google Colab, lo que facilita la importación del conjunto de datos y el inicio de la codificación.
Ahora, para hacer uso de este conjunto de datos, las imágenes se alimentarán a través de un escala de grises y igualar función.
Escala de grises
Actualmente, las imágenes del repositorio son tridimensional. Esto se debe a que las imágenes en color tienen tres canales de color: rojo, verde y azul (RGB) que se apilan entre sí para darles sus colores vibrantes.
Para este modelo de aprendizaje automático, no se necesitan tres capas de imágenes, solo se necesitan las características de los letreros. Por lo tanto, pasar las imágenes del conjunto de datos a través de una función de escala de grises limpia nuestros datos y filtra solo la información importante, reduciendo también las imágenes a una sola dimensión.

Igualar
Ahora que las imágenes están en escala de grises, han perdido algo de su contraste, o la blancura o negrura de los píxeles. Para aumentar el contraste, las imágenes deben ecualizado. Esto es importante porque el modelo tiene que distinguir varias características que son recogidas por sus cambios de contraste.
Ecualizar una imagen significa extender la distribución del valor de los píxeles, creando un rango más amplio de blancura y negrura de la imagen.

Red neuronal convolucional
Una red neuronal convolucional es una clase de redes de aprendizaje profundo que se utiliza para analizar imágenes visuales. En este caso, se utiliza para encontrar conjuntos únicos de características entre la variedad de señales de tráfico.
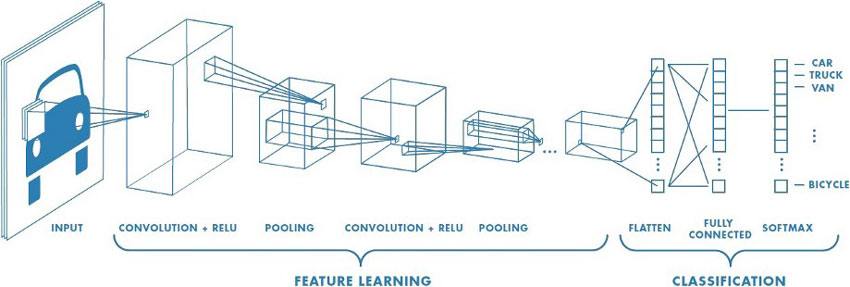
El proceso que utiliza es similar a cómo nuestros ojos y cerebros clasifican todo lo que vemos. Por ejemplo, al mirar un conjunto de números, puede notar la diferencia entre un 1 y un 8. Un 1 es una línea vertical, mientras que un 8 es un bucle encima de otro bucle. Por supuesto, en realidad no dices esto en tu cabeza porque los hemos visto tantas veces que se ha convertido en un hábito.
Como aprenden
Para que una red neuronal convolucional extraiga las características importantes de una imagen, utilizan granos para escanear o caminar sobre una imagen.
Pienso en ello como tus ojos moviéndose en movimientos sacádicos sobre una imagen. Analizan una parte y se mueven horizontalmente a la siguiente sección hasta que haya visto la imagen completa.

Los kernels comparan la diferencia entre lo que ven y lo que buscan. Cuando una característica coincide, se registra y almacena en el mapa de características. Estos mapas de características son versiones refinadas de la imagen original. Guardan las características importantes del letrero e ignoran el resto. Varios kernels diferentes revisan la imagen original y extraen diferentes características importantes, luego se unen para crear el patrón convolucionado final.

Resolver el sobreajuste
Cuando se trabaja con un conjunto de datos pequeño como el que se usa en el modelo, un problema llamado sobreajuste surge. Aquí es cuando el modelo comienza a memorizar las imágenes, en lugar de trabajar para encontrar sus características. Más específicamente, cuando el modelo pasa por demasiadas épocas (básicamente cuántas veces el modelo pasa por el conjunto de datos), comienza a escuchar la entrada de algunos nodos e ignora otros. Esto reduce la precisión del modelo porque no sabrá cómo clasificar ninguna imagen nueva fuera del conjunto de datos.
Para solucionarlo, un capa de abandono está agregado. Esta es una solución simple para este modelo. Al eliminar un subconjunto aleatorio de nodos, se evita el sobreajuste porque los nodos no pueden memorizar las etiquetas (porque hay una alta probabilidad de que el nodo se apague). Es como el maestro que llama al niño que no presta atención en clase. Al avergonzarlo y llamar su atención, (con suerte) se concentrará y aportará valor a la clase.
Predicción
Finalmente, el modelo se proporciona con una imagen de una señal de tráfico, se ejecuta a través de la red neuronal convolucional y escupe el número asociado con la señal correspondiente.
Cuando se ejecuta el siguiente signo aleatorio en el modelo …

El modelo predice la clase como [1], ¡cual es correcta!.

Para cualquier persona interesada en el código, puede encontrarlo en mi GitHub, aquí!.
- Las imágenes se preprocesan con una función de ecualización y escala de grises.
- Una red neuronal convolucional (CNN) utiliza núcleos para extraer las características de un signo.
- Las características se comparan con otras imágenes clasificadas para hacer una predicción.
Conclusiones clave
- Las imágenes se preprocesan con una función de ecualización y escala de grises.
- Una red neuronal convolucional (CNN) utiliza núcleos para extraer las características de un signo.
- Las características se comparan con otras imágenes clasificadas para hacer una predicción.






Añadir comentario