
Bienvenido, les saluda Miguel y para hoy les traigo otro post.
Índice
TL; DR
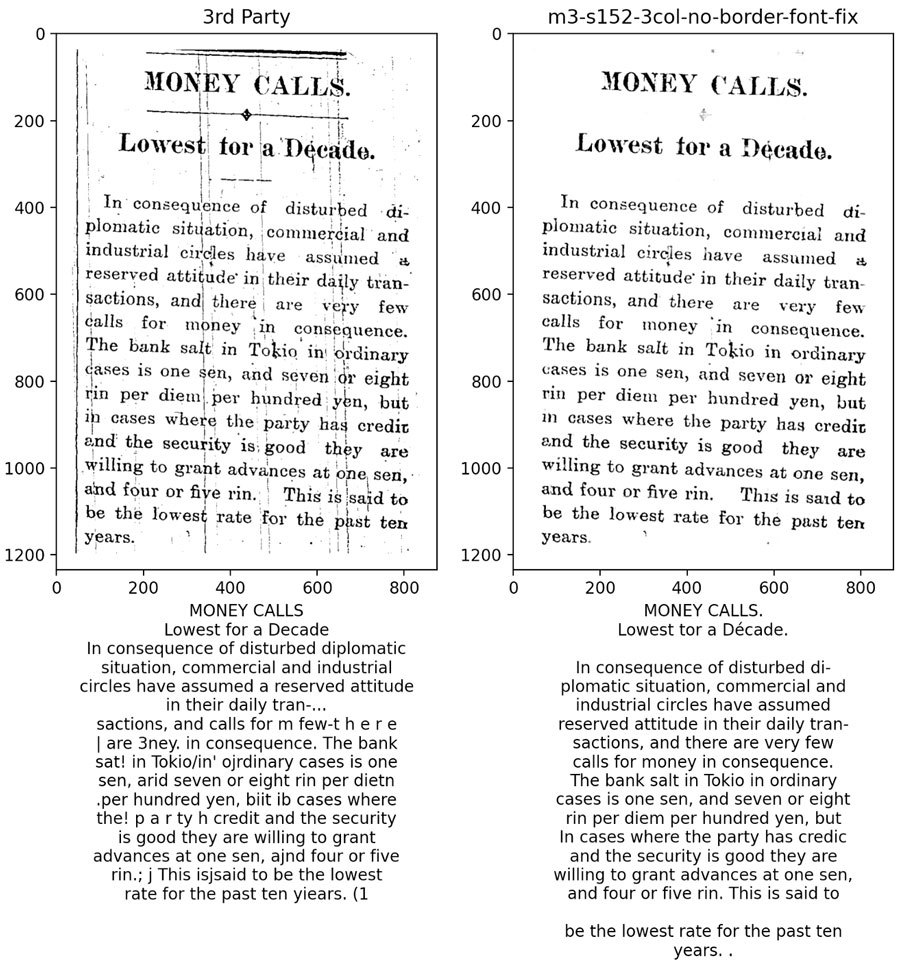
Estamos en el proceso de mejorar el texto OCR de nuestro archivo histórico de noticias digitales. El archivo consta de PDFs, producidos a partir de microfilms e impresos de noticias originales.
La calidad de los PDF varía, lo que resulta en un resultado de OCR pobre. Nuestra suposición es que si la calidad de la imagen puede ser mejorada, la precisión del OCR mejorará a su vez.
Nos encontramos con una técnica de aprendizaje de máquinas llamada Denoising Autoencoder (DAE) , que codifica y decodifica la imagen pasándola a través de una red neural convolucional (CNN).
Aunque se necesita un mayor esfuerzo para perfeccionar el modelo, los resultados hasta ahora son prometedores.
Antecedentes
Contamos con más de 100 años de archivo de noticias en forma de microfilms y noticias impresas. Fueron escaneados por un proveedor y convertidos a formatos PDF y TIFF. Luego, los archivos se pasaron a otro proveedor para extraer el texto (OCR).
Los resultados de OCR fueron extremadamente pobres, debido al desgaste de los microfilms debido al uso. Aunque no son visibles para los ojos humanos, aparecen líneas verticales en el texto de los escaneos.
Las manchas de tinta y el ruido de fondo denso debido a la calidad del papel y los procesos de impresión, así como el texto desalineado y torcido, se suman a la complejidad.
El archivo XML también detalla las coordenadas de los artículos en el artículo original, en caso de que tengamos que volver al original como referencia.
Por lo tanto, todo lo que tenemos que hacer es encontrar la mejor manera de eliminar el ruido de las imágenes PDF y OCR nuevamente con Tesseract.
Los enfoques tradicionales
Al principio, buscamos una técnica de procesamiento de imágenes simple para eliminar el ruido.

Aunque la mayor parte del ruido se eliminó de los experimentos anteriores, algunos detalles de los personajes también se erosionaron.
El desenfoque medio es muy efectivo contra el ruido de sal y pimienta que estamos buscando eliminar, pero las líneas permanecieron. El método de dilatación y erosión tuvo un mejor resultado que el desenfoque medio, pero quedan rastros de ruidos en todo el párrafo, lo que afectó la precisión del OCR.
La mayoría de nuestros periódicos escaneados ya están binarizados, por lo que el umbral adaptativo no puede ayudar en este caso. El umbral adaptativo funciona mejor cuando hay una variación considerable en la intensidad del fondo, donde el texto suele ser más oscuro que el ruido de fondo.
El enfoque de la IA
Después de varias pruebas de uso de la técnica anterior, comenzamos a buscar un enfoque más «inteligente» . Nos encontramos con el término «codificador automático» .
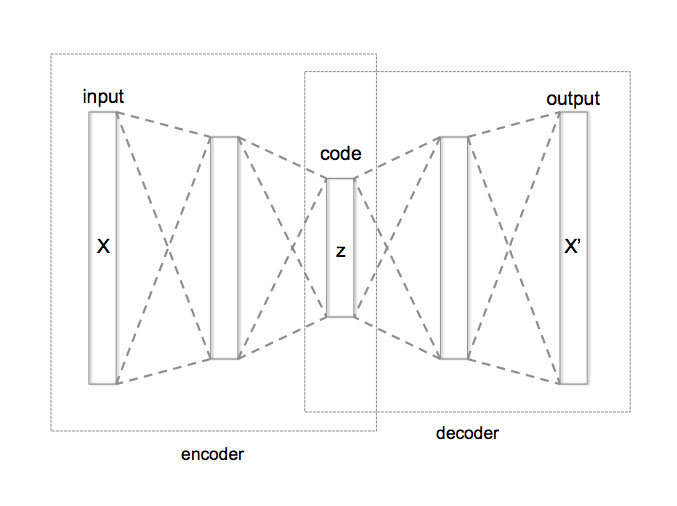
Denoising Autoencoder (DAE) es un tipo de red neuronal artificial que se compone de un codificador y un decodificador. El codificador convierte la entrada en una representación comprimida, mientras que el decodificador reconstruye la forma comprimida lo más cerca posible de su entrada original.
La red neuronal convolucional (CNN) se utiliza para la ingeniería de funciones, que consiste en extraer y seleccionar funciones útiles en el proceso.
El decodificador aprende a generar la salida y comparar el resultado con nuestras muestras limpiadas manualmente. Repetimos el proceso de formación hasta que ya no se pueda mejorar la precisión de la validación y antes de que se produzca el sobreajuste.
El proceso de codificación tiene pérdidas y podemos usar el codificador para comprimir imágenes. Esto es similar a cómo funciona el JPEG. Pero, en general, la compresión funciona mejor en JPEG, ya que el codificador solo funciona mejor con el tipo de datos con el que está entrenado.
Ejemplo de DAE con Keras
input_img = Input(shape=(28, 28, 1))x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x)x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
Ejemplo de código cortesía de Francois Chollet.
La imagen de entrada es de 28 x 28 píxeles con 1 canal (1 color, escala de grises) del ejemplo anterior. La entrada se procesa con 2 convoluciones.
Cada capa de convolución tiene 32 filtros con un kernel de 3x3 para producir 32 mapas de características. Luego, estos mapas de características se reducen (submuestreo) mediante un núcleo de 2x2, lo que da como resultado un mapa de características más pequeño.
2 convoluciones, la representación comprimida se reconstruirá para producir la salida.
Aquí se utilizan otras 2 convoluciones. Esta vez, Upsampling se utiliza para restaurar el tamaño de salida para que coincida con el tamaño de entrada.
En la última capa de convolución, observe el número de filtros establecido en 1 porque necesitamos reducir el canal a 1 para que coincida con el número del canal de entrada.
Si ejecuta el código de Python anterior junto con autoencoder.summary(), obtendrá los siguientes detalles del modelo. La forma es la misma para la capa. input_1 y conv2d_4.
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 28, 28, 32) 320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 14, 14, 32) 9248 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 7, 7, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 7, 7, 32) 9248 _________________________________________________________________ up_sampling2d (UpSampling2D) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 14, 14, 32) 9248 _________________________________________________________________ up_sampling2d_1 (UpSampling2 (None, 28, 28, 32) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 28, 28, 1) 289 ================================================================= Total params: 28,353 Trainable params: 28,353 Non-trainable params: 0 _________________________________________________________________
Todavía estamos buscando un buen modelo que pueda manejar nuestro caso de uso, pero elegir DAE es definitivamente el enfoque correcto para resolver nuestro problema de manera “inteligente”.
Espero que te sea de utilidad. Gracias por leer este post.





Añadir comentario