
Muy buenas, me llamo Miguel y aquí les traigo otro nuevo post.
Este artículo está basado en la semana 2, por supuesto. Modelos de secuencia en Coursera. En este artículo, intento resumir y explicar el concepto de representación e incrustación de palabras.
Representación de palabras
Generalmente, representamos una palabra en el procesamiento del lenguaje natural a través de un vocabulario donde cada palabra está representada por un vector codificado en caliente. Supongamos que tenemos un vocabulario (V) de 10,000 palabras.
V = [a, aaron, …, zulu, <UNK>]
Supongamos que la palabra ‘Hombre’ está en la posición 5391 en el vocabulario, luego se puede representar mediante un vector codificado en caliente (O5391). La posición de 1 en el vector disperso O₅₃₉₁ es el índice de la palabra Hombre en el vocabulario.
O5391 = [0,0,0,0,...,1,...,0,0,0]
Así, podemos encontrar otras palabras en el vocabulario que pueden estar representadas por vectores codificados one-hot Women (O9853), King (O4914), Queen (O7157), Apple (O 456), Orange (O6257).
Pero este método no es un método efectivo para alimentar nuestros algoritmos para aprender modelos de secuencia porque el algoritmo no es capaz de capturar la relación entre diferentes ejemplos.
Supongamos que entrenamos nuestro modelo para la oración:
- Quiero un vaso de jugo de naranja.
- Y quiere predecir la siguiente palabra de la oración:
- Quiero un vaso de manzana _____.
Incluso si ambos ejemplos son casi iguales y nuestro algoritmo está bien entrenado, pero no pudo predecir la siguiente palabra en el ejemplo de prueba.
La razón detrás de esto es que en el caso de una representación vectorial codificada en caliente, el producto interno entre dos vectores codificados en caliente es 0. Incluso si se toma la distancia euclidiana entre dos vectores cualesquiera, también es 0.
Sabemos que la siguiente palabra funcionaría en el ejemplo que tomamos, pero el algoritmo no puede encontrar ninguna relación entre las palabras de las dos oraciones anteriores y no puede predecir la palabra en la oración.
Para resolver este problema, tomamos la ayuda de incrustaciones de palabras, es la representación caracterizada de palabras. Para cada palabra del vocabulario, podemos aprender un conjunto de características y valores.

En lugar de tomar un vector codificado escaso one-hot, tomamos un vector destacado denso para cada palabra. Podemos tomar diferentes propiedades de cada palabra y dar una ponderación de cuánto pertenece la propiedad a la palabra.
Así podemos establecer una relación entre las palabras que tienen las mismas propiedades. Ahora nuestro algoritmo también es capaz de encontrar la relación entre manzana y naranja, y predecir la siguiente palabra de acuerdo con ella.
En la imagen que se muestra arriba, hay 300 propiedades que se toman para cada palabra y se convierten en un vector, ahora la palabra hombre representada por ( e ₅₃₉₁)
e₅₃₉₁ = [-1, 0.01, 0.03, 0.04, ...]
Aquí e representa el vector incrustado.
Podemos tomar ayuda t-SNE ( incrustación de vecinos estocásticos distribuidos en t) algoritmo de aprendizaje automático para visualizar estas palabras en un diagrama 2-D.

En este gráfico, podemos ver que las palabras que tienen las mismas propiedades son vecinas y la palabra que no tiene ninguna propiedad común está lejos.
El reconocimiento de entidad de nombre es la tarea en la que tenemos que identificar un nombre en el texto dado. Por ejemplo en el texto
Sally Jhonsan is an orange farmer.
Sabemos que Sally Jhonson es el nombre en el ejemplo anterior y entrenamos nuestro modelo para tales ejemplos. Ahora, si le damos un ejemplo de prueba a nuestro algoritmo como.
Robert Lin is an apple farmer.
Al usar la incrustación de palabras, el algoritmo reconoce fácilmente que el agricultor de manzanas y el agricultor de naranjas son identificables, entonces puede predecir que Rober Lin es el nombre en el ejemplo de prueba.
Es una toma fácil para nuestro algoritmo, ahora tomamos otro ejemplo:
Robert Lin is a durain cultivator.
Durian es una fruta popular en Singapur y algunos otros países. Y este término no está disponible en el vocabulario disponible como datos de entrenamiento porque nuestro conjunto de datos de entrenamiento es pequeño. Existe una alta probabilidad de que el algoritmo no reconozca el nombre en la oración.
En tal caso, la incrustación de palabras es útil, puede examinar fácilmente grandes conjuntos de datos sin etiquetar. Grandes conjuntos de datos pueden estar disponibles en línea de forma gratuita.
Entonces, la palabra incrustación se puede aprender de ese corpus de texto o conjunto de datos y se puede transferir a nuestro modelo. De esta manera, la incrustación de palabras se puede utilizar mediante el aprendizaje por transferencia para nuestro modelo. El aprendizaje por transferencia es útil cuando nuestro corpus de texto es pequeño.
En el ejemplo anterior, al usar la incrustación para un corpus de texto grande y transferir el conocimiento adquirido a nuestro corpus de texto, el algoritmo puede identificar que el durian y el naranja comparten las mismas propiedades y el encuadre está relacionado con el cultivador, por lo que puede predecir que el nombre en la oración es Robert Lin.
La incrustación de palabras también ayuda en el razonamiento de analogías. El razonamiento por analogía no es solo un caso de uso de la incrustación de palabras, sino que también nos ayuda a comprender cómo funciona la incrustación de palabras y qué podemos hacer mediante la incrustación de palabras.
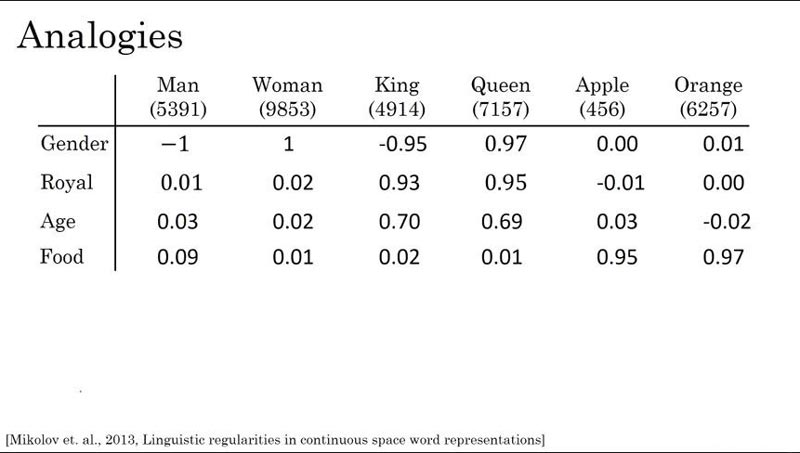
Las imágenes muestran la incrustación de palabras para un conjunto de palabras. Ahora queremos saber que si el Hombre está relacionado con la Mujer de la misma manera, ¿a quién pertenece el Rey?
Puede representarse como:
Man ----> Woman King ----> ?
Aquí estamos usando solo un vector de 4 dimensiones en lugar de usar 50 o 100 dimensiones o más. Vectores incrustados para las palabras Hombre, Mujer, Rey, Reina, podemos escribir como:
eman = [ -1 0.04 0.03 0.09] ewoman = [ 1 0.02 0.02 0.01] eking = [ -0.95 0.93 0.70 0.02] equeen = [ -0.97 0.95 0.69 0.01]
Si tomamos la diferencia entre vectores eman y ewoman entonces aproximadamente es:
eman - ewoman ≈[-2 0 0 0]
Y si tomamos la diferencia entre vectores eking y equeen entonces también es aproximadamente el mismo que el anterior.
eking - equeen ≈[-2 0 0 0]
Entonces, nuestro algoritmo es capaz de determinar si el hombre está relacionado con la mujer y el rey también está relacionado con la reina de la misma manera.
En realidad, el algoritmo no solo toma la diferencia entre el rey y la reina, el algoritmo encuentra el máximo para la ecuación que se indica a continuación.
eman - ewoman ≈ eking - ew find word w : argmax Sim(ew, eking - eman + ewoman)
Aquí w representa las palabras en el corpus de texto. Entonces realizamos la operación matemática para eking, eman y ewoman y comprobar la similitud del vector resultante con todos los demás vectores incrustados. El vector incrustado que muestra la máxima similitud es la salida.
Para calcular la similitud usamos la función de similitud de coseno porque cuando el ángulo entre dos vectores es 0, su valor de coseno es 1, que es el máximo.
Por tanto, podemos obtener el valor más similar y si dos vectores están en un ángulo de 90, entonces da 0, lo que significa que dos vectores no están relacionados en absoluto.
Y si el ángulo entre el vector es 180 entonces da -1, lo que significa que los vectores están relacionados pero en dirección opuesta. La fórmula de similitud de coseno entre dos vectores A y B es:
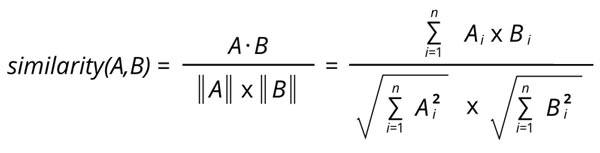
Podemos considerar la fórmula de la distancia euclidiana normal para calcular la similitud, pero la similitud del coseno da un resultado más conveniente, por lo que se usa con mayor frecuencia.
La principal diferencia entre la distancia euclidiana y la similitud del coseno es que la similitud del coseno normaliza los vectores como se muestra en la fórmula y la distancia euclidiana se usa generalmente para la medida de la disimilitud.
Así es como la palabra incrustación es útil para el razonamiento de analogías.
Para tareas de aprendizaje de secuencias en el procesamiento del lenguaje natural, la representación de vectores codificada en un solo uso no es útil. Para tales tareas, tenemos que utilizar la incrustación de palabras.
La incrustación de palabras convierte los vectores dispersos en vectores densos al considerar las propiedades de las palabras en el vocabulario. Si nuestro corpus de texto de entrenamiento es pequeño, podemos tomar la ayuda del aprendizaje por transferencia y hacer que nuestro algoritmo sea más robusto.
La incrustación de palabras se puede entender mediante el razonamiento de analogía y proporciona información precisa sobre cómo funciona la incrustación de palabras. La similitud de coseno se usa ampliamente para medir y calcular la similitud entre dos vectores.
Gracias por leer este artículo.






Añadir comentario