
Bienvenido, soy Miguel y esta vez les traigo este nuevo tutorial.
Índice
Cómo visualizar el rendimiento del modelo de clasificación con Yellowbrick
Ya sea que estemos iterando sobre modelos de rendimiento o presentándonos a los clientes, los científicos de datos utilizan visualizaciones con regularidad. Si bien tenemos muchas bibliotecas de visualización disponibles, Yellowbrick sirve como una extensión natural del proceso de modelado de scikit-learn y ayuda con la interpretación y ajuste del modelo.
«La visualización le da respuestas a preguntas que no sabía que tenía».
– Ben Schneiderman
Esta publicación sirve como introducción a Yellowbrick y muestra algunas formas en las que puede simplificar el proceso de visualización de los resultados de varios modelos de clasificación.
Usaré Pandas y NumPy para ayudar con la manipulación del marco de datos y usaré seaborn, irónicamente, para cargar el famoso marco de datos del pingüino. Importaré clasificadores y módulos sobre la marcha para facilitar la interpretación. El primer bloque de código incluye importaciones estándar, lectura de datos y limpieza básica de datos.
import pandas as pd import numpy as np import seaborn as sns import warnings warnings.simplefilter(action='ignore', category=FutureWarning) # Loading in data and dropping NaNs penguins = sns.load_dataset('penguins') penguins = penguins.dropna() # Mapping species of penguins to a numerical value penguins['species'] =\penguins['species'].replace({'Adelie': 0, 'Chinstrap': 1, 'Gentoo': 2}) # Mapping sex to a numerical value penguins['sex'] = \np.where(penguins['sex'] == 'Male', 1, 0) # Binarizing 'island' penguins = pd.get_dummies(penguins, drop_first=True) # Viewing a sample of the data penguins.sample(3)

# Creating my input variables, X and target variable, y
X = penguins.drop('species', axis=1)
y = penguins['species']
# Splitting data into training and test sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
# Identifying classes. The classes variable will be useful when using Yellowbrick's visualizers
classes = ['Adelie', 'Chinstrap', 'Gentoo']
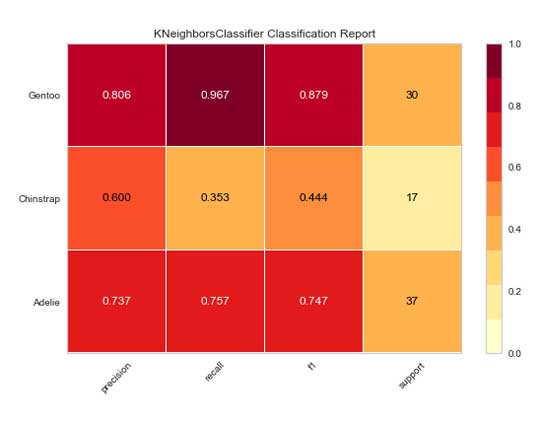
Informe de clasificación
El informe de clasificación es un mapa de calor de la precisión, recuperación y puntuación f-1 de su modelo según la clase. El informe de clasificación de base de clase ayuda a comprender los problemas de varias clases que pueden ser difíciles de evaluar con una puntuación global de f-1 o de precisión. Además, puede establecer el argumento support=True para ver el número de ocurrencias reales en cada clase en el conjunto de datos.
from yellowbrick.classifier import ClassificationReport from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier() vizualizer = ClassificationReport(model, classes=classes, support=True) vizualizer.fit(X_train, y_train) vizualizer.score(X_test, y_test) vizualizer.show();
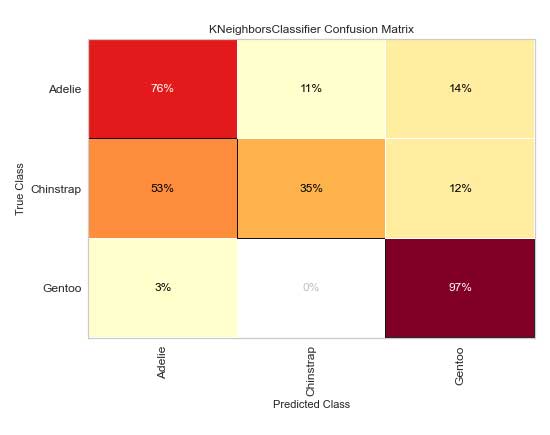
Matriz de confusión
Aunque scikit-learn tiene una función plot_confusion_matrix dentro de su biblioteca de métricas, la matriz de confusión de Yellowbrick tiene características adicionales que pueden resultar beneficiosas. El argumento percent=True mostrará el porcentaje de verdadero (o la celda dividida por el total de la fila). los label_encoder El argumento aceptará un codificador de etiquetas de aprendizaje de sci-kit o un diccionario.
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(
model, classes=classes,
percent=True
#label_encoder=0: 'Adelie', 1: 'Chinstrap', 2: 'Gentoo'
)
cm.fit(X_train, y_train)
cm.score(X_test, y_test)
cm.show();
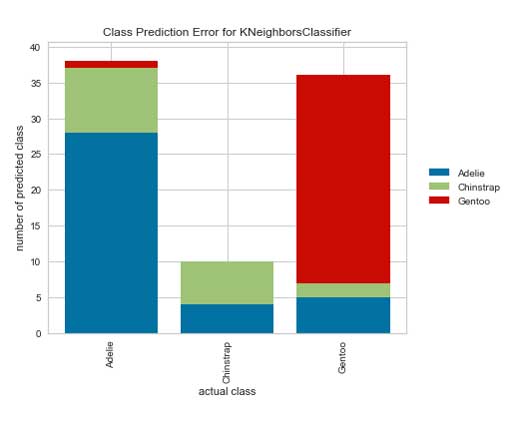
Error de predicción de clase
El gráfico de barras de error de predicción de clases es uno de mis favoritos. Es una versión diferente de una matriz de confusión que es un poco menos confusa. El gráfico muestra sus predicciones de una manera que es fácil de identificar errores. Tome el siguiente gráfico, por ejemplo; podemos ver en la primera columna que el modelo clasificó una porción considerable de pingüinos de barbijo (verde) como Adelia. Mientras tanto, los barbijos se identificaron perfectamente, pero muchos de ellos se categorizaron incorrectamente. Con estos nuevos conocimientos, se pueden detectar fácilmente las funciones que causan problemas y solucionar el problema rápidamente.
from yellowbrick.classifier import ClassPredictionError visualizer = ClassPredictionError(model, classes=classes) visualizer.fit(X_train, y_train) visualizer.score(X_test, y_test) visualizer.show();
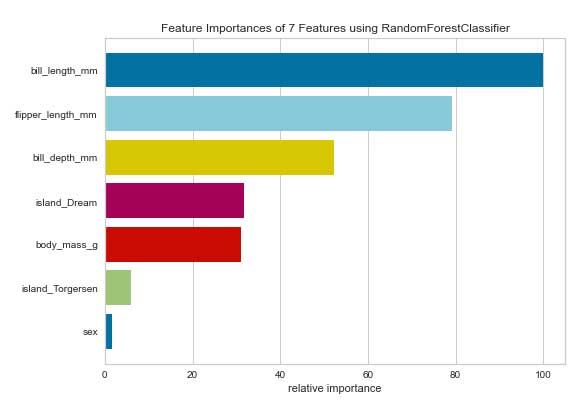
Importancia de las funciones
Aunque no se limita a problemas de clasificación, el visualizador de Importancias de características es una forma rápida de utilizar scikit-learn’s atributo feature_importances_. Para problemas de regresión donde no hay atributo feature_importances_, el visualizador utilizará el modelo atributo coef_. La documentación de Yellowbrick sugiere que establezca relative=False al utilizar un modelo de regresión para comprender la verdadera magnitud del coeficiente.
from yellowbrick.model_selection import FeatureImportances from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) visualizer = FeatureImportances(model) visualizer.fit(X_train, y_train) visualizer.show();
ROC AUC
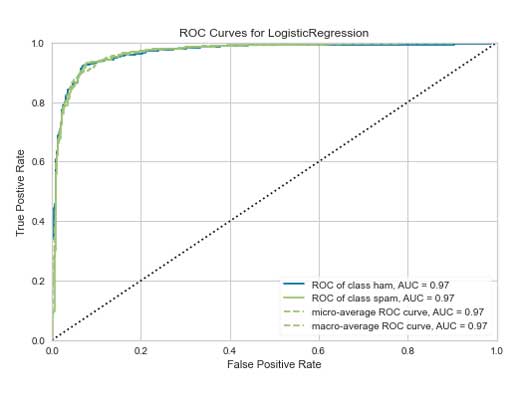
A continuación se muestra una característica de funcionamiento del receptor / área bajo el gráfico de curva, o ROC AUC, utilizando Yellowbrick spam conjunto de datos para clasificación binaria. El AUC de ROC se utiliza generalmente para la clasificación binaria, sin embargo, el AUC de ROC de Yellowbrick permite la clasificación de clases múltiples. Elegí presentar el conjunto de datos de spam en lugar de nuestros queridos pingüinos porque hizo un mejor trabajo al mostrar la curva ROC AUC por excelencia. El gráfico muestra el ROC para cada clase, así como los promedios micro y macro. Los micropromedios se calculan a partir de la suma de todos los verdaderos positivos y falsos positivos en todas las clases y los macropromedios son los promedios de las curvas en todas las clases. Consulte la documentación para obtener más información.
Aprecio la multitud de opciones dentro de este visualizador. Puede alternar entre las diferentes curvas y hacer que se muestren, incluida la puntuación ROC AUC correspondiente en la leyenda.
from yellowbrick.classifier import ROCAUC from yellowbrick.datasets import load_spam from sklearn.linear_model import LogisticRegression X, y = load_spam() X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y) model = LogisticRegression(max_iter=10000) model.fit(X_train, y_train) visualizer = ROCAUC(model, classes=['ham', 'spam']) visualizer.fit(X_train, y_train) visualizer.score(X_test, y_test) visualizer.show();
Gracias por explorar conmigo una selección de visualizaciones de clasificación de Yellowbrick. He estado utilizando estos visualizadores en mis propios modelos y los he encontrado convenientes e informativos. Planeo escribir otra entrada dedicada a las visualizaciones de regresión.






Añadir comentario